AWS News Blog
Behind the Scenes of the AWS Jobs Page, or Scope Creep in Action

|
The AWS team is growing rapidly and we’re all doing our best to find, interview, and hire the best people for each job. In order to do my part to grow our team, I started to list the most interesting and relevant open jobs at the end of my blog posts. At first I searched our main job site for openings. I’m not a big fan of that site; it serves its purpose but the user interface is oriented toward low-volume searching. I write a lot of blog posts and I needed something better and faster.
Over a year ago I decided to scrape all of the jobs on the site and store them in a SimpleDB domain for easy querying. I wrote a short PHP program to do this. The program takes the three main search URLs (US, UK, and Europe/Asia/South Africa) and downloads the search results from each one in turn. Each set of results consists of a list of URLs to the actual job pages (e.g. Mgr – AWS Dev Support).
Early versions of my code downloaded the job pages sequentially. Since there are now 370 open jobs, this took a few minutes to run and I became impatient. I found Pete Warden’s ParallelCurl and adapted my code to use it. I was now able to fetch and process up to 16 job pages at a time, greatly reducing the time spent in the crawl phase.
for ( $i = 0 ; $i < count ( $JobLinks ) ; $i ++ )
{
$PC -> startRequest ( $JobLinks [ $i ] [ ‘Link’ ] , ‘JobPageFetched’ , $i ) ;
}
$PC -> finishAllRequests ( ) ;
My code also had to parse the job pages and to handle five different formatting variations. Once the pages were parsed it was easy to write the jobs to a SimpleDB domain using the AWS SDK for PHP.
Now that I had the data at hand, it was time to do something interesting with it. My first attempt at visualization included a tag cloud and some jQuery code to show the jobs that matched a tag:
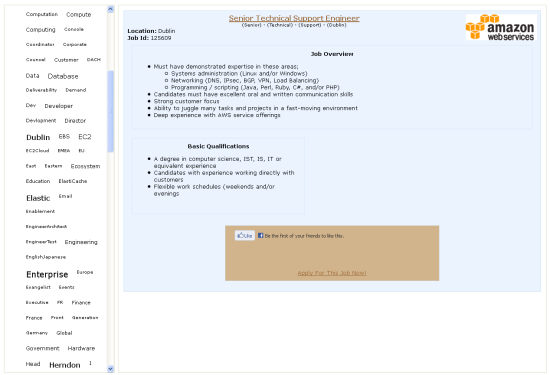
I was never able to get this page to work as desired. There were some potential scalability issues because all of the jobs were loaded (but hidden) so I decided to abandon this approach.
I gave upon the fancy dynamic presentation and generated a simple static page (stored in Amazon S3, of course) instead, grouping the jobs by city:
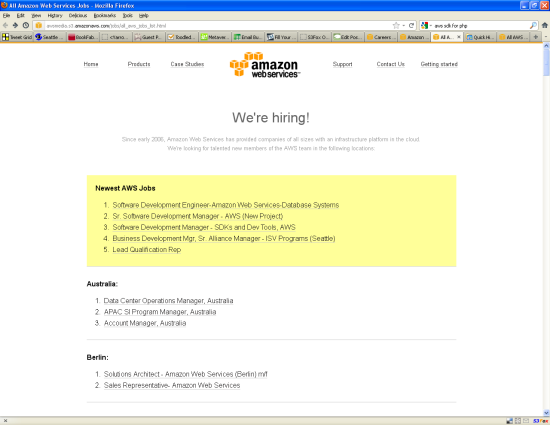
My code uses the data stored in the SimpleDB domain to identify jobs that have appeared since the previous run. The new jobs are highlighted in the yellow box at the top of the page.
I set up a cron job on an EC2 instance to run my code once per day. In order to make sure that the code ran as expected, I decided to have it send me an email at the conclusion of the run. Instead of wiring my email address in to the code, I created an SNS (Simple Notification Service) topic and subscribed to it. When SNS added support for SMS last month, I subscribed my phone number to the same topic.
I found the daily text message to be reassuring, and I decided to take it even further. I set up a second topic and published a notification to it for each new job, in human readable, plain-text form.
The next step seemed obvious. With all of this data in hand, I could generate a tweet for each new job. I started to write the code for this and then discovered that I was reinventing a well-rounded wheel! After a quick conversation with my colleague Matt Wood, it turned out that he already had the right mechanism in place to publish a tweet for each new job.
Matt subscribed an SQS queue to my per-job notification topic. He used a CloudWatch alarm to detect a non-empty queue, and used the alarm to fire up an EC2 instance via Auto Scaling. When the queue is empty, a second alarm reduces the capacity of the group, thereby terminating the instance.
Being more clever than I, Matt used an AWS CloudFormation template to create and wire up all of the moving parts:
“ProcessorInstance” : {
“Type” : “AWS::AutoScaling::AutoScalingGroup” ,
“Properties” : {
“AvailabilityZones” : { “Fn::GetAZs” : “” } ,
“LaunchConfigurationName” : { “Ref” : “LaunchConfig” } ,
“MinSize” : “0” ,
“MaxSize” : “1” ,
“Cooldown” : “300” ,
“NotificationConfiguration” : {
“TopicARN” : { “Ref” : “EmailTopic” } ,
“NotificationTypes” : [ “autoscaling:EC2_INSTANCE_LAUNCH” ,
“autoscaling:EC2_INSTANCE_LAUNCH_ERROR” ,
“autoscaling:EC2_INSTANCE_TERMINATE” ,
“autoscaling:EC2_INSTANCE_TERMINATE_ERROR” ]
}
}
} ,
You can also view and download the full template.
The instance used to process the new job positions runs a single Ruby script, and is bootstrapped from a standard base Amazon Linux AMI using CloudFormation.
The CloudFormation template passes in a simple bootstrap script using instance User Data, taking advantage of the cloud-init daemon which runs at startup on the Amazon Linux AMI. This in turn triggers CloudFormations own cfn-init process, which configures the instance for use based on information in the CloudFormation template.
A collection of packages are installed via the yum and rubygems package managers (including the AWS SDK for Ruby), the processing script is downloaded and installed from S3, and a simple, YAML format configuration file is written to the instance which contains keys, Twitter configuration details and queue names used by the processing script.
queue.poll(:poll_interval => 10) do |msg|
notification = TwitterNotification.new(msg.body)
begin
client.update(notification.update)
rescue Exception => e
log.debug “Error posting to Twitter: #{e}”
end end
The resulting tweets show up on the AWSCloud Twitter account.
At a certain point, we decided to add some geo-sophistication to the process. My code already identified the location of each job, so it was a simple matter to pass this along to Matt’s code. Given that I am located in Seattle and he’s in Cambridge (UK, not Massachusetts), we didn’t want to coordinate any type of switchover. Instead, I simple created another SNS topic and posted JSON-formatted messages to it. This loose coupling allowed Matt to make the switch at a time convenient to him.
So, without any master plan in place, Matt and I have managed to create a clean system for finding, publishing, and broadcasting new AWS jobs. We made use of the following AWS technologies:
- S3 – Page storage.
- EC2 – Page and queue processing.
- SQS – Storage of queued notifications of new jobs.
- SNS – Publication of new job notifications.
- SimpleDB – Storage of job list.
- CloudWatch – Monitoring SQS queue to scale up and scale down.
- Auto Scaling – Implementation of scaling up and scaling down.
- CloudFormation – Stack construction.
- AWS SDK for PHP – My code.
- AWS SDK for Ruby – Matt’s code.
Here is a diagram to show you how it all fits together:
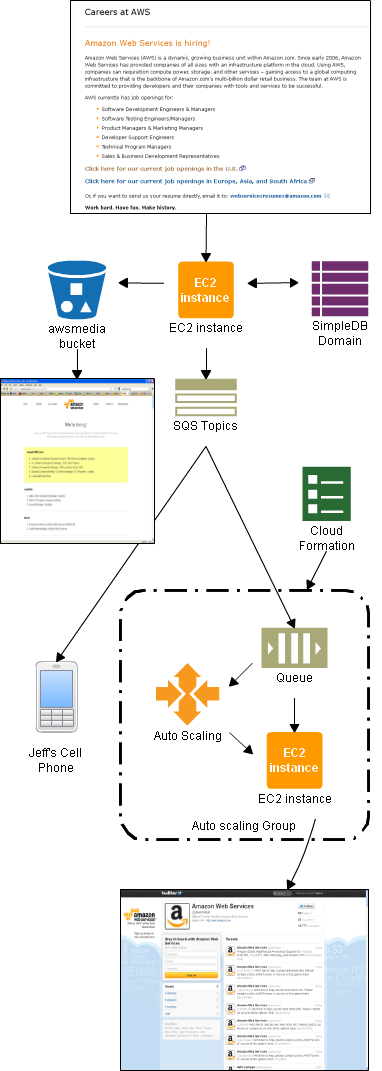
If you want to hook in to the job processing system, here are the SNS topic IDs:
- Run complete – arn:aws:sns:us-east-1:348414629041:aws-jobs-process
- New job found (human readable) – arn:aws:sns:us-east-1:348414629041:aws-new-job
- New job found (JSON) – arn:aws:sns:us-east-1:348414629041:aws-new-job-json
The topics are all set to be publicly readable so you can subscribe to them without any help from me. If you build something interesting, please feel free to post a comment so that I know about it.
The point of all of this is to make sure that you can track the newest AWS jobs. Please follow @AWSCloud take a look at the list of All AWS Jobs.
— Jeff (with lots of help from Matt);