Category: Elastic MapReduce
AWS GovCloud (US) Update – AWS Key Management Service Now Available
 The AWS Key Management Service (KMS) provides you with seamless, centralized control over your encryption keys. As I noted when we launched the service (see my post, New AWS Key Management Service, for more information), this service gives you a new option for data protection and relieves you of many of the more onerous scalability and availability issues that inevitably surface when you implement key management at enterprise scale. KMS uses Hardware Security Modules to protect the security of your keys. It is also integrated with AWS CloudTrail for centralized logging of all key usage.
The AWS Key Management Service (KMS) provides you with seamless, centralized control over your encryption keys. As I noted when we launched the service (see my post, New AWS Key Management Service, for more information), this service gives you a new option for data protection and relieves you of many of the more onerous scalability and availability issues that inevitably surface when you implement key management at enterprise scale. KMS uses Hardware Security Modules to protect the security of your keys. It is also integrated with AWS CloudTrail for centralized logging of all key usage.
AWS GovCloud (US), as you probably know, is an AWS region designed to allow U.S. government agencies (federal, state, and local), along with contractors, educational institutions, enterprises, and other U.S. customers to run regulated workloads in the cloud. AWS includes many security features and is also subject to many compliance programs. AWS GovCloud (US) allows customers to run workloads that are subject to U.S. International Traffic in Arms Regulations (ITAR), the Federal Risk and Authorization Management Program (FedRAMPsm), and levels 1-5 of the Department of Defense Cloud Security Model (CSM).
KMS in GovCloud (US)
Today we are making AWS Key Management Service (KMS) available in AWS GovCloud (US). You can use it to encrypt data in your own applications and within the following AWS services, all using keys that are under your control:
- Amazon EBS volumes.
- Amazon S3 objects using Server-Side Encryption (SSE-KMS) or client-side encryption using the encryption client in the AWS SDKs.
- Output from Amazon EMR clusters to S3 using the EMRFS client.
To learn more, visit the AWS Key Management Service (KMS) page. To get started in the AWS GovCloud (US) region, contact us today!
— Jeff;
Resource Groups and Tagging for AWS
For many years, AWS customers have used tags to organize their EC2 resources (instances, images, load balancers, security groups, and so forth), RDS resources (DB instances, option groups, and more), VPC resources (gateways, option sets, network ACLS, subnets, and the like) Route 53 health checks, and S3 buckets. Tags are used to label, collect, and organize resources and become increasingly important as you use AWS in larger and more sophisticated ways. For example, you can tag relevant resources and then take advantage AWS Cost Allocation for Customer Bills.
Today we are making tags even more useful with the introduction of a pair of new features: Resource Groups and a Tag Editor. Resource Groups allow you to easily create, maintain, and view a collection of resources that share common tags. The new Tag Editor allows you to easily manage tags across services and Regions. You can search globally and edit tags in bulk, all with a couple of clicks.
Let’s take a closer look at both of these cool new features! Both of them can be accessed from the new AWS menu:
Tag Editor
Until today, when you decided to start making use of tags, you were faced with the task of stepping through your AWS resources on a service-by-service, region-by-region basis and applying tags as needed. The new Tag Editor centralizes and streamlines this process.
Let’s say I want to find and then tag all of my EC2 resources. The first step is to open up the Tag Editor and search for them:
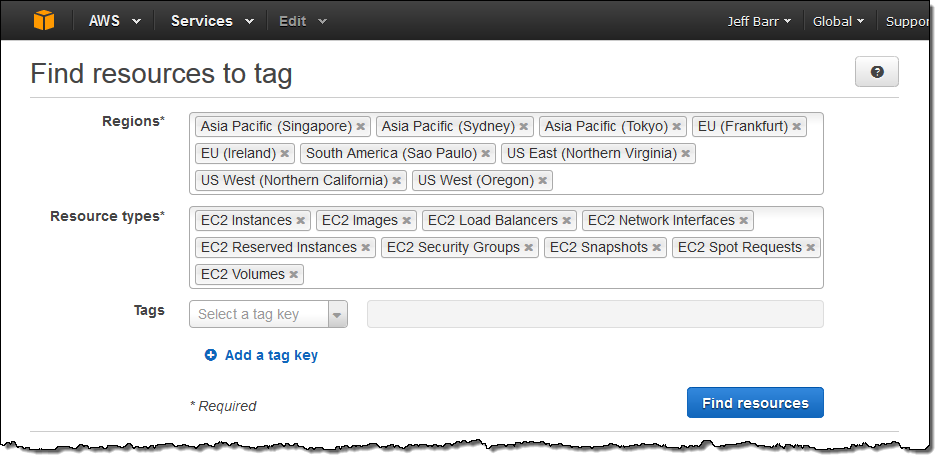
The Tag Editor searches my account for the desired resource types across all of the selected Regions and then displays all of the matches:
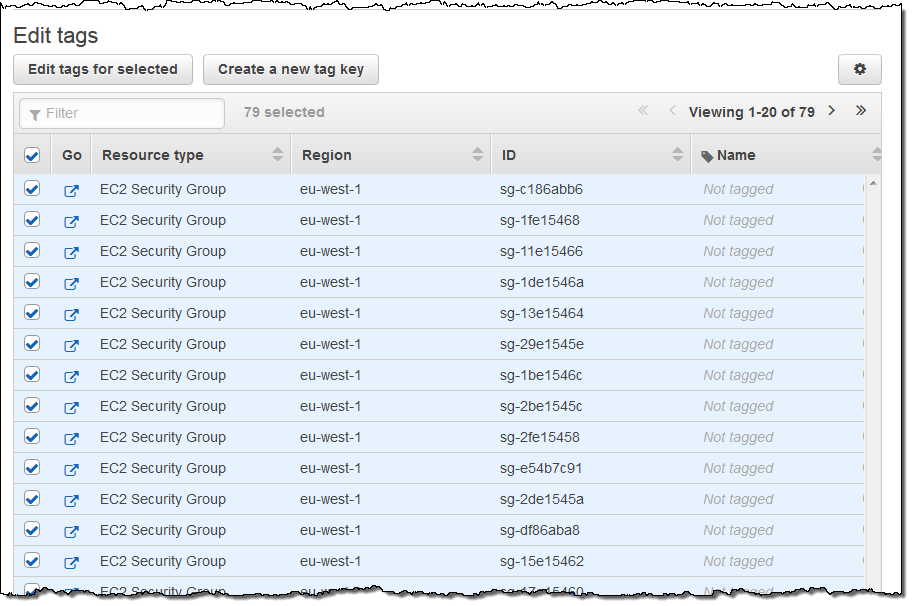
I can then select all or some of the resources for editing. When I click on the Edit tags for selected button, I can see and edit existing tags and add new ones. I can also see existing System tags:
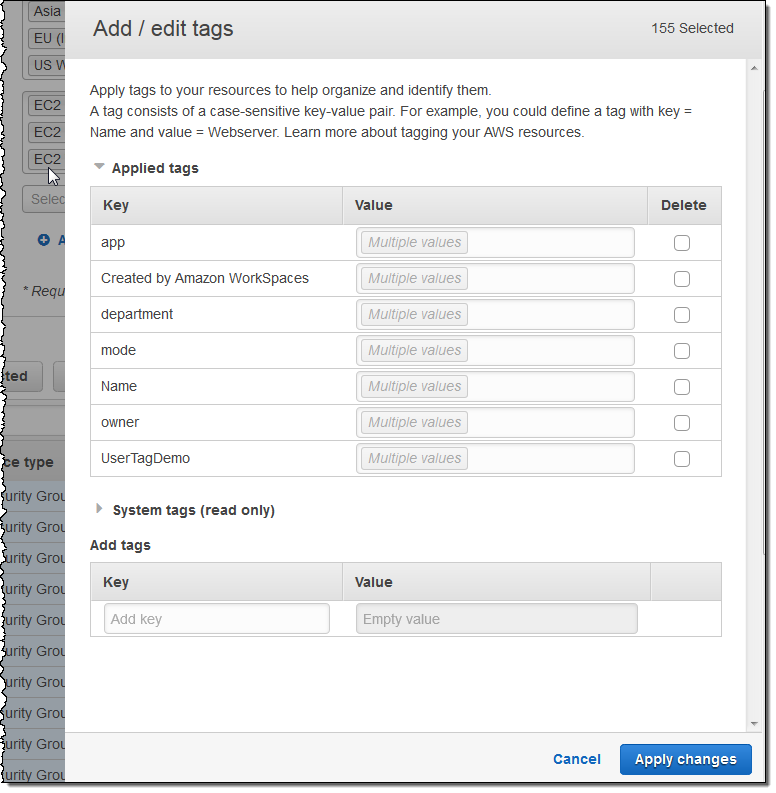
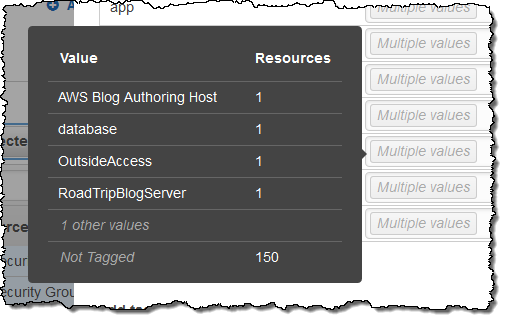
I can see which values are in use for a particular tag by simply hovering over the Multiple values indicator:
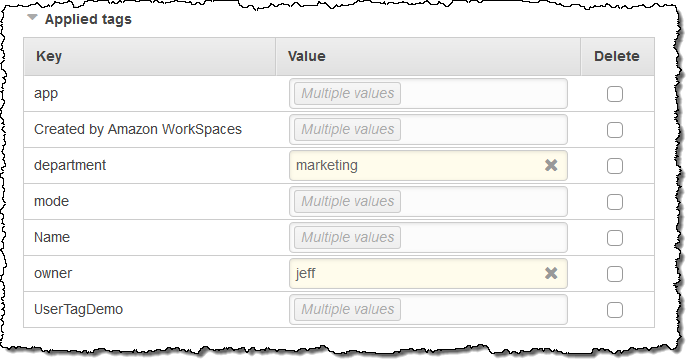
I can change multiple tags simultaneously (changes take effect when I click on Apply changes):
Resource Groups
A Resource Group is a collection of resources that shares one or more tags. It can span Regions and services and can be used to create what is, in effect, a custom console that organizes and consolidates the information you need on a per-project basis.
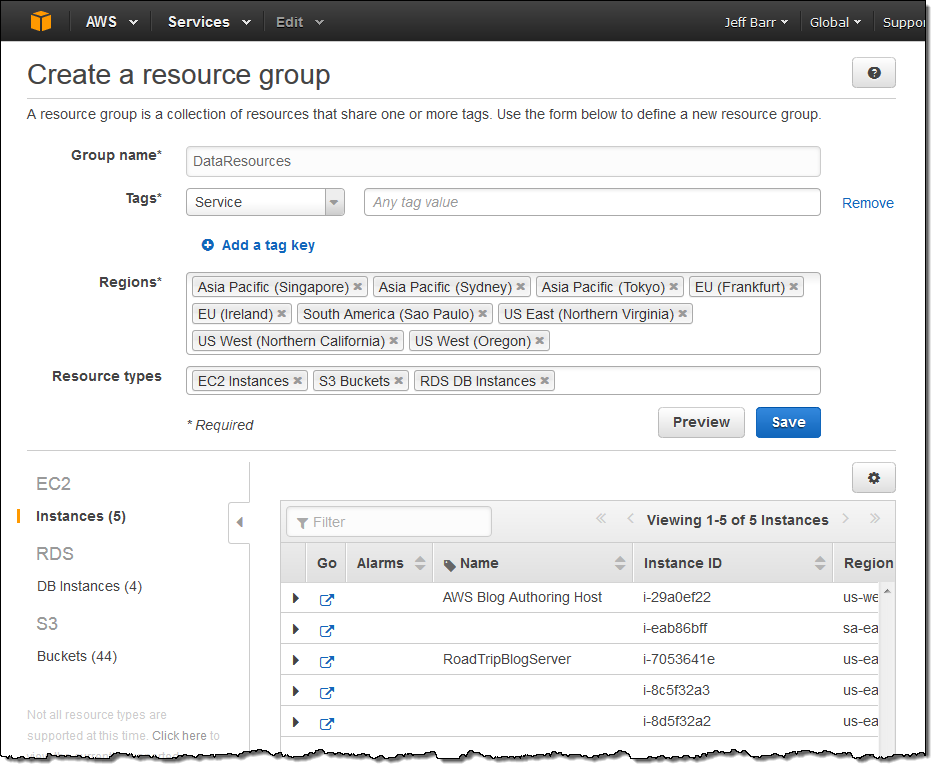
You can create a new Resource Group with a couple of clicks. I tagged a bunch of my AWS resources with Service and then added the EC2 instances, DB instances, and S3 buckets to a new Resource Group:
My Resource Groups are available from within the AWS menu:
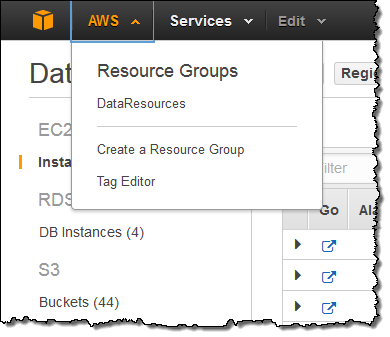
Selecting a group displays information about the resources in the group, including any alarm conditions (as appropriate):
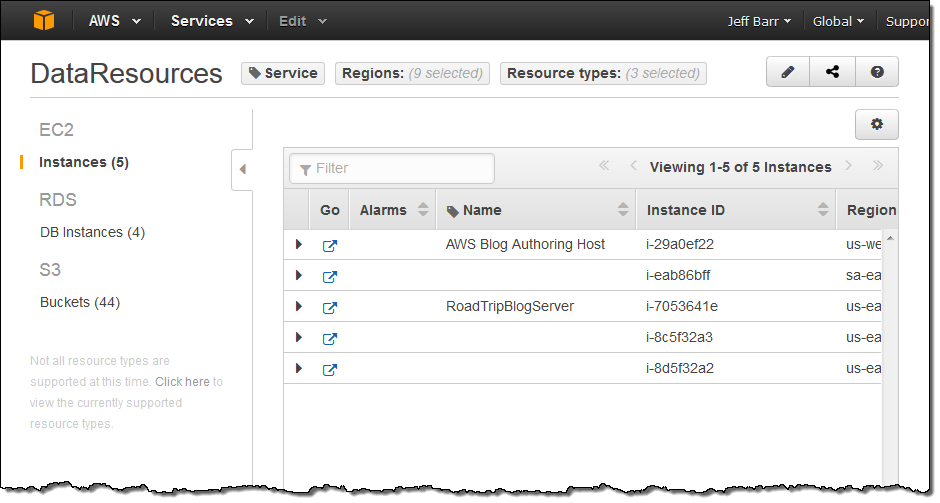
This information can be further expanded:
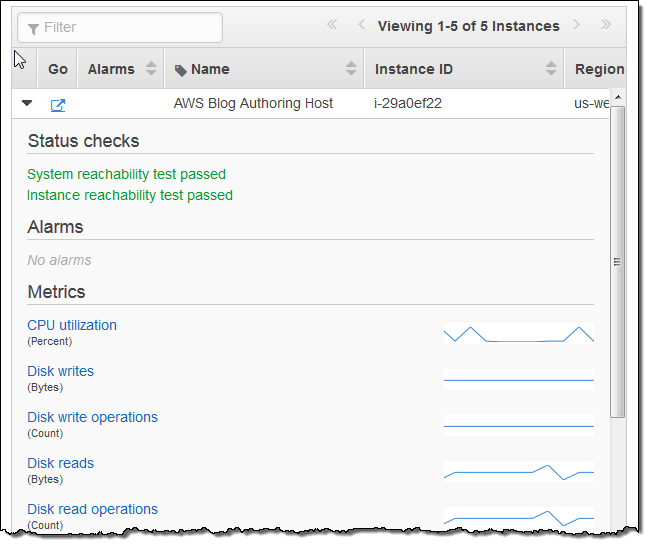
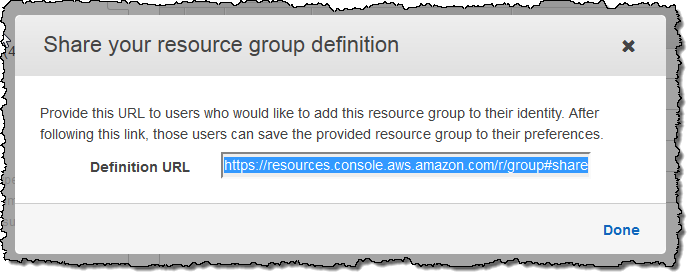
Each identity within an AWS account can have its own set of Resource Groups. They can be shared between identities by clicking on the Share icon:
Down the Road
We are, as usual, very interested in your feedback on this feature and would love to hear from you! To get in touch, simply open up the Resource Groups Console and click on the Feedback button.
Available Now
Resource Groups and the Tag Editor are available now and you can start using them today!
— Jeff;
Hue – A Web User Interface for Analyzing Data With Elastic MapReduce
Hue is an open source web user interface for Hadoop. Hue allows technical and non-technical users to take advantage of Hive, Pig, and many of the other tools that are part of the Hadoop and EMR ecosystem. You can think of Hue as the primary user interface to Amazon EMR and the AWS Management Console as the primary administrator interface.
I am happy to announce that Hue is now available for Amazon EMR as part of the newest (version 3.3) Elastic MapReduce AMI. You can load your data, run interactive Hive queries, develop and run Pig scripts, work with HDFS, check on the status of your jobs, and more.
We have extended Hue to work with Amazon Simple Storage Service (S3). Hue’s File Browser allows you to browse S3 buckets and you can use the Hive editor to run queries against data stored in S3. You can also define an S3-based table using Hue’s Metastore Manager.
To get started, you simply launch a cluster with the new AMI and log in to Hue (it runs on the cluster’s master node). You can save and share queries with your colleagues, you can visualize query results, and you can view logs in real time (this is very helpful when debugging).
Hue in Action
Here are some screen shots of Hue in action. The main page displays all of my Hue documents (Hive queries and Pig scripts):
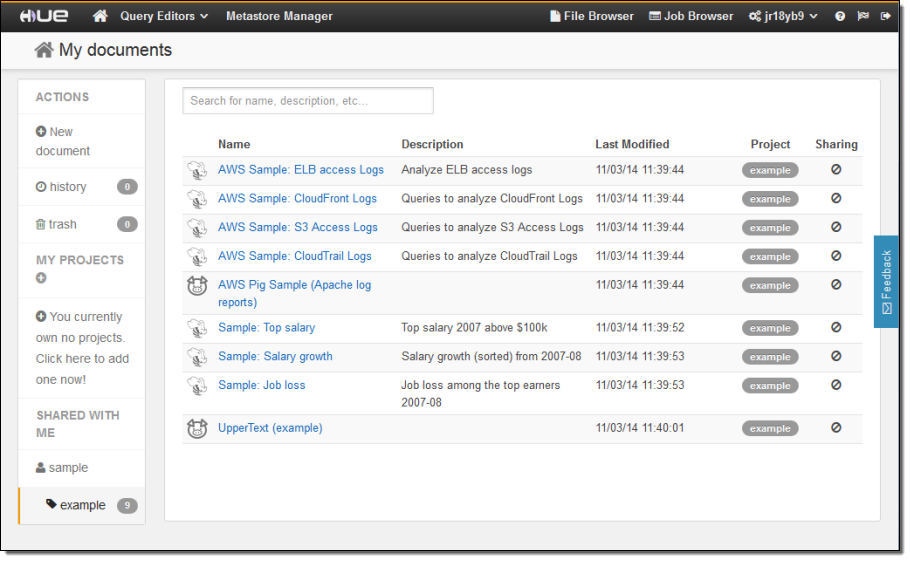
I can click on a document to open it up in appropriate query editor:
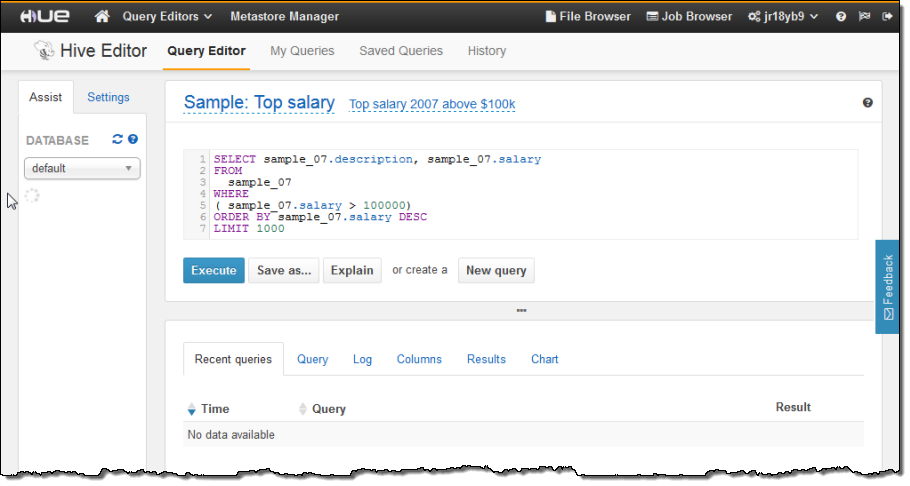
I can view and edit the query, and then run it on my cluster with a single click of the Execute button. After I do this, I can inspect the logs as the job runs:
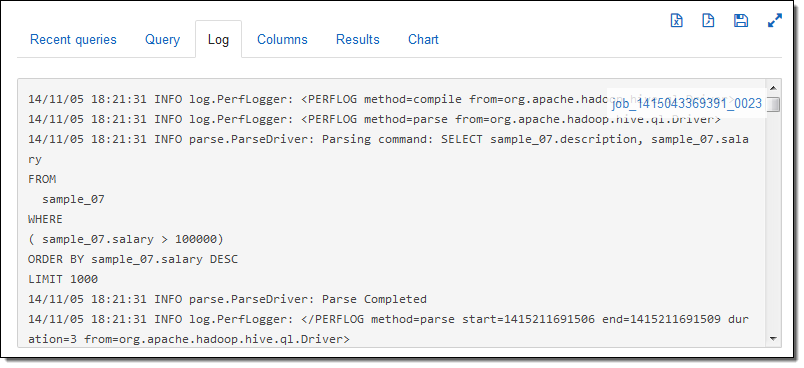
After the query runs to completion I can see the results, again with one click:
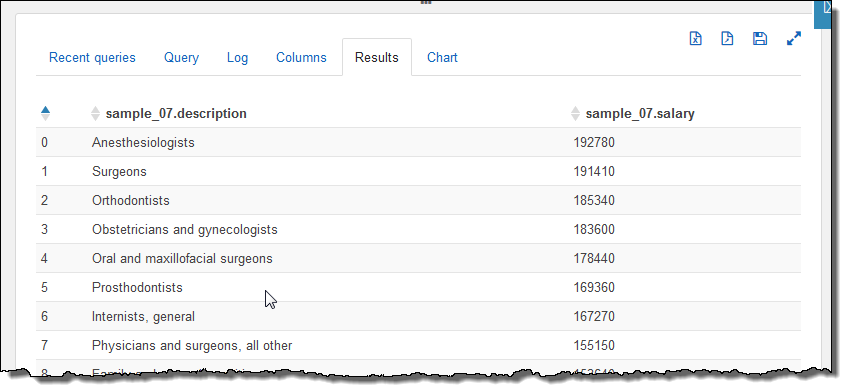
I can also see the results in graphical (chart) form:
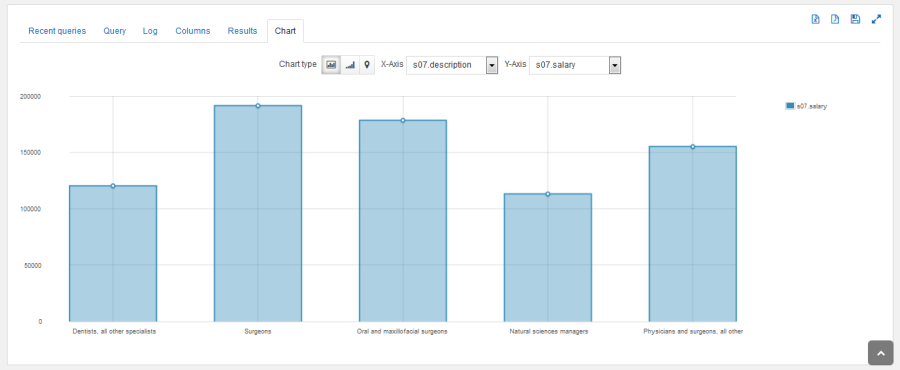
I have shown you just a couple of Hue’s features. You can read the Hue Tutorials and the Hue User Guide to learn more.
You can launch an EMR cluster (with Hue included) from the AWS Management Console. You can also launch it from the command line like this:
$ aws emr create-cluster --ami-version=3.3.0 \
--applications Name=Hue Name=Hive Name=Pig \
--use-default-roles --ec2-attributes KeyName=myKey \
--instance-groups \
InstanceGroupType=MASTER,InstanceCount=1,InstanceType=m3.xlarge \
InstanceGroupType=CORE,InstanceCount=2,InstanceType=m1.large
Hue for You
Hue is available on version 3.3 and above of the Elastic MapReduce AMI at no extra cost. It runs on the master node of your EMR cluster.
— Jeff;
New AWS Quick Start – Cloudera Enterprise Data Hub
 date: 2014-10-15 2:03:16 PM The new Quick Start Reference Deployment Guide for Cloudera Enterprise Data Hub does exactly what the title suggests! The comprehensive (20 page) guide includes the architectural considerations and configuration steps that will help you to launch the new Cloudera Director and an associated Cloudera Enterprise Data Hub (EDH) in a matter of minutes. As the folks at Cloudera said in their blog post, “Cloudera Director delivers an enterprise-class, elastic, self-service experience for Hadoop in cloud environments.”
date: 2014-10-15 2:03:16 PM The new Quick Start Reference Deployment Guide for Cloudera Enterprise Data Hub does exactly what the title suggests! The comprehensive (20 page) guide includes the architectural considerations and configuration steps that will help you to launch the new Cloudera Director and an associated Cloudera Enterprise Data Hub (EDH) in a matter of minutes. As the folks at Cloudera said in their blog post, “Cloudera Director delivers an enterprise-class, elastic, self-service experience for Hadoop in cloud environments.”
The reference deployment takes the form of a twelve-node cluster that will cost between $12 and $82 per hour in the US East (Northern Virginia) Region, depending on the instance type that you choose to deploy.
The cluster runs within a Virtual Private Cloud that includes public and private subnets, a NAT instance, security groups, a placement group for low-latency networking within the cluster, and an IAM role. The EDH cluster is fully customizable and includes worker nodes, edge nodes, and management nodes, each running on the EC2 instance type that you designate:
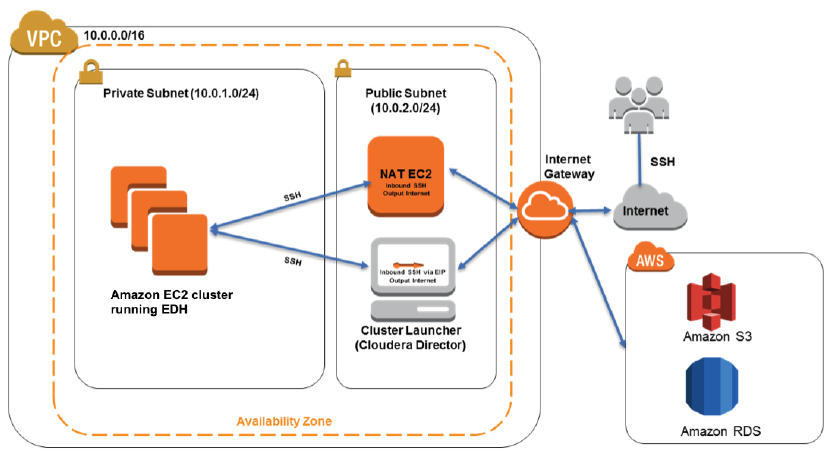
The entire cluster is launched and configured by way of a parameterized AWS CloudFormation template that is fully described in the guide.
— Jeff;
Elastic MapReduce Now Supports Hive 13
I am pleased to announce that Elastic MapReduce now supports version 13 of Hive. Hive is a great tool for building and querying large data sets. It supports the ETL (Extract/Transform/Load) process with some powerful tools, and give you access to files stored on your EMR cluster in HDFS or in Amazon Simple Storage Service (S3). Programmatic or ad hoc queries supplied to Hive are executed in massively parallel fashion by taking advantage of the MapReduce model.
Version 13 Features
 Version 13 of Hive includes all sorts of cool and powerful new features. Here’s a sampling:
Version 13 of Hive includes all sorts of cool and powerful new features. Here’s a sampling:
Vectorized Query Execution – This feature reduces CPU usage for query options such as scans, filters, aggregates, and joins. Instead of processing queries on a row-by-row basis, the vectorized query execution feature processes blocks of 1024 rows at a time. This reduces internal overhead and allows the column of data stored within the block to be processed in a tight, efficient loop. In order to take advantage of this feature, your data must be stored in the ORC (Optimized Row Columnar) format. To learn more about this format and its advantages, take a look at ORC: An Intelligent Big Data file format for Hadoop and Hive.
Faster Plan Serialization – The process of serializing a query plan (turning a complex Java object in to an XML representation) is now faster. This speeds up the transmission of the query plan to the worker nodes and improves overall Hive performance.
Support for DECIMAL and CHAR Data Types – The new DECIMAL data type supports exact representation of numerical values with up to 38 digits of precision. The new CHAR data type supports fixed-length, space-padded strings. See the documentation on Hive Data Types for more information.
Subquery Support for IN, NOT IN, EXISTS, and NOT EXISTS – Hive subqueries within a WHERE clause now support the IN, NOT IN, EXISTS, and NOT EXISTS statements in both correlated and uncorrelated form. In an uncorrelated subquery, columns from the parent query are not referenced.
JOIN Conditions in WHERE Clauses – Hive now supports JOIN conditions within WHERE clauses.
Improved Windowing Functions – Hive now supports improved, highly optimized versions of the “windowing” functions that perform aggregation over a moving window. For example, you can easily compute the moving average of a stock price over a specified number of days.
Catch the Buzz
You can start using these new features today by making use of version 3.2.0 of the Elastic MapReduce AMI in your newly launched clusters.
— Jeff;
Using Elastic MapReduce as a Generic Hadoop Cluster Manager
My colleague Steve McPherson sent along a nice guest post to get you thinking about ways to use Elastic MapReduce in non-traditional ways!
— Jeff;
Amazon Elastic MapReduce (EMR) is a fully managed Hadoop-as-a-service platform that removes the operational overhead of setting up, configuring and managing the end-to-end lifecycle of Hadoop clusters. Many of our customers never interact with Hadoop for scheduled data processing tasks or job flows (clusters in EMR terminology). Instead, they specify an input data source, the query or program that should be run, and the output location for the results.
As the Hadoop ecosystem has expanded from being a generic MapReduce (batch-oriented data processing) system, EMR has expanded to support Hadoop clusters that are long-running, shared, interactive data-processing environments. EMR clusters have Hive and Pig already set up when started and implement the full suite of best practices and integrations with related AWS services such as EC2, VPC, CloudWatch, S3, DynamoDB and Kinesis.
Despite the name Elastic MapReduce, the service goes far beyond batch-oriented processing. Clusters in EMR have a flexible and rich cluster-management framework that users can customize to run any Hadoop ecosystem application such as low-latency query engines like Hbase (with Phoenix), Impala, Spark/Shark and machine learning frameworks like Mahout. These additional components can be installed using Bootstrap Actions or Steps.
Bootstrap Actions are scripts that run on every machine in the cluster as they are brought online, but before the core Hadoop services like HDFS (name node or data node) and the Hive Metastore are configured and started. For example, Cascading, Apache Spark, and Presto can be deployed to a cluster without any need to communicate with HDFS or Zookeeper.
Steps are scripts as well, but they run only on machines in the Master-Instance group of the cluster. This mechanism allows applications like Zookeeper to configure the master instances and allows applications like Hbase and Apache Drill to configure themselves.
The Amazon EMR team maintains an open source repository of bootstrap actions and related steps that can be used as examples for writing your own Bootstrap actions and Steps. Using these examples, our customers configure applications like Apache Drill and OpenTSB to run in EMR. If you are using these, we.d love to know how you.ve customized EMR to suit your use case. And yes, pull requests are welcome!
Here’s an example that shows you how to use the Presto boostrap action from the repository. Run the following command to create an Elastic MapReduce cluster:
$ elastic-mapreduce --create --name "Presto" --alive \
--hive-interactive --ami-version 3.1.0 --num-instances 4 \
--master-instance-type i2.2xlarge --slave-instance-type i2.2xlarge \
--bootstrap-action s3://presto-bucket/install_presto_0.71.rb --args "-t","1GB","-l","DEBUG","-j","-server -Xmx1G -XX:+UseConcMarkSweepGC -XX:+ExplicitGCInvokesConcurrent -XX:+AggressiveOpts -XX:+HeapDumpOnOutOfMemoryError -XX:OnOutOfMemoryError=kill -9 %p -Dhive.config.resources=/home/hadoop/conf/core-site.xml,/home/hadoop/conf/hdfs-site.xml","-v","0.72","-s","1GB","-a","1h","-p","http://central.maven.org/maven2/com/facebook/presto/" \
--bootstrap-name "Install Presto"
Once the cluster is up and running, start Hive like this:
$ hive
Create, set up, and test a table:
# Create Hive table
DROP TABLE IF EXISTS apachelog;
CREATE EXTERNAL TABLE apachelog (
host STRING,
IDENTITY STRING,
USER STRING,
TIME STRING,
request STRING,
STATUS STRING,
SIZE STRING,
referrer STRING,
agent STRING
)
PARTITIONED BY(iteration_no int)
LOCATION 's3://publicprestodemodata/apachelogsample/hive';
ALTER TABLE apachelog RECOVER PARTITIONS;
# Test Hive
select * from apachelog where iteration_no=101 limit 10;
# Exit Hive
exit
Start Presto and run a test query:
# Set Presto Pager to null for clean display
export PRESTO_PAGER=
# Launch Presto
./presto --catalog hive
# Show tables to prove that Presto is seeing Hive's tables
show tables;
# Run test query in Presto
select * from apachelog where iteration_no=101 limit 10;
— Steve
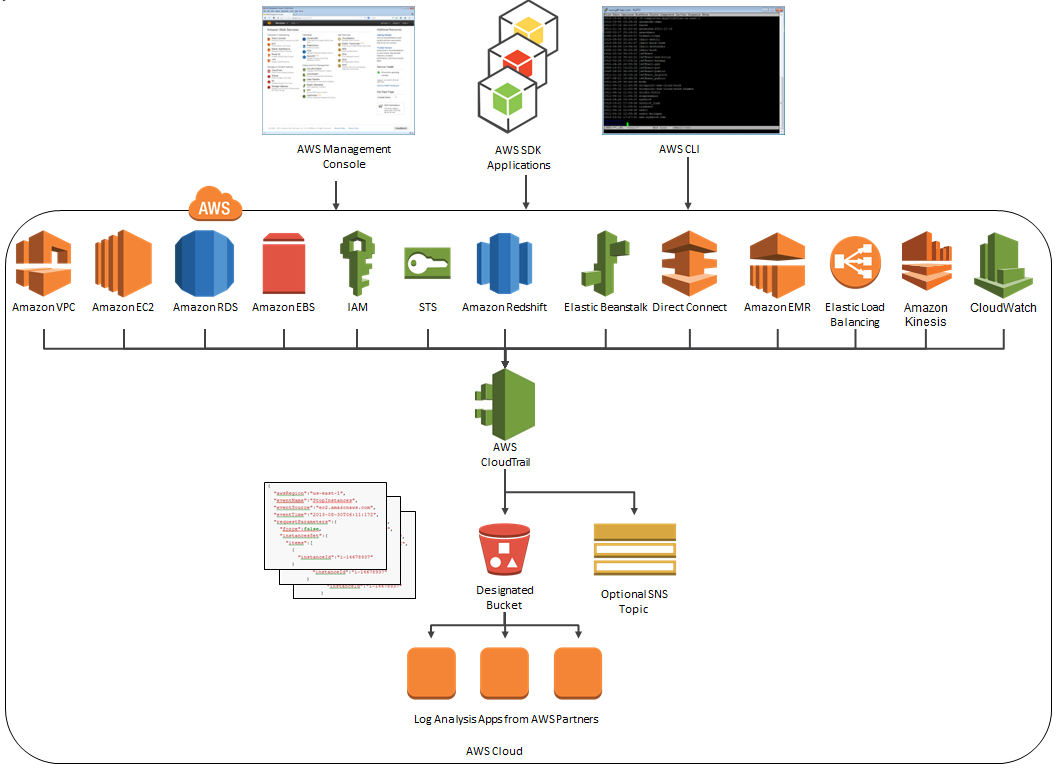
AWS CloudTrail Update – Seven New Services & Support From CloudCheckr
AWS CloudTrail records the API calls made in your AWS account and publishes the resulting log files to an Amazon S3 bucket in JSON format, with optional notification to an Amazon SNS topic each time a file is published.
Our customers use the log files generated CloudTrail in many different ways. Popular use cases include operational troubleshooting, analysis of security incidents, and archival for compliance purposes. If you need to meet the requirements posed by ISO 27001, PCI DSS, or FedRAMP, be sure to read our new white paper, Security at Scale: Logging in AWS, to learn more.
Over the course of the last month or so, we have expanded CloudTrail with support for additional AWS services. I would also like to tell you about the work that AWS partner CloudCheckr has done to support CloudTrail.
New Services
At launch time, CloudTrail supported eight AWS services. We have added support for seven additional services over the past month or so. Here’s the full list:
- Amazon EC2
- Elastic Block Store (EBS)
- Virtual Private Cloud (VPC)
- Relational Database Service (RDS)
- Identity and Access Management (IAM)
- Security Token Service (STS)
- Redshift
- CloudTrail
- Elastic Beanstalk – New!
- Direct Connect – New!
- CloudFormation – New!
- Elastic MapReduce – New!
- Elastic Load Balancing – New!
- Kinesis – New!
- CloudWatch – New!
Here’s an updated version of the diagram that I published when we launched CloudTrail:
News From CloudCheckr
CloudCheckr (an AWS Partner) integrates with CloudTrail to provide visibility and actionable information for your AWS resources. You can use CloudCheckr to analyze, search, and understand changes to AWS resources and the API activity recorded by CloudTrail.
Let’s say that an AWS administrator needs to verify that a particular AWS account is not being accessed from outside a set of dedicated IP addresses. They can open the CloudTrail Events report, select the month of April, and group the results by IP address. This will display the following report:
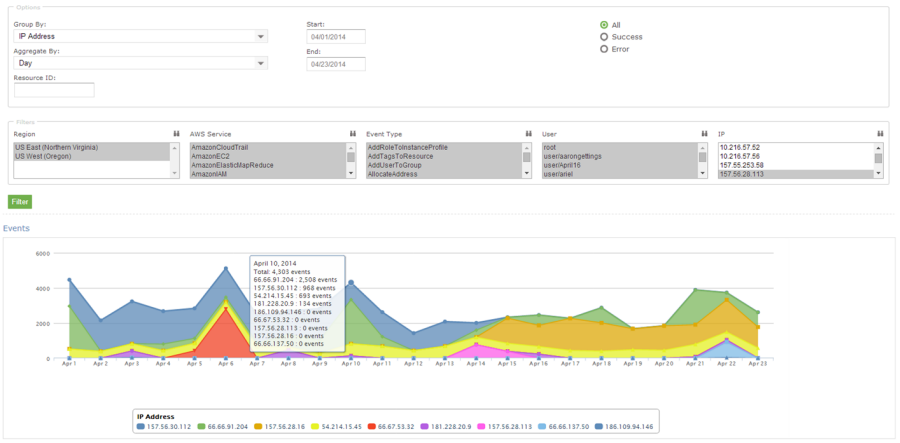
As you can see, the administrator can use the report to identify all the IP addresses that are being used to access the AWS account. If any of the IP addresses were not on the list, the administrator could dig in further to determine the IAM user name being used, the calls being made, and so forth.
CloudCheckr is available in Freemium and Pro versions. You can try CloudCheckr Pro for 14 days at no charge. At the end of the evaluation period you can upgrade to the Pro version or stay with CloudCheckr Freemium.
— Jeff;
