AWS News Blog
Search and Interact With Your Streaming Data Using the Kinesis Connector to Elasticsearch

|
My colleague Rahul Patil wrote a guest post to show you how to build an application that loads streaming data from Kinesis into an Elasticsearch cluster in real-time.
— Jeff;
The Amazon Kinesis team is excited to release the Kinesis connector to Elasticsearch! Using the connector, developers can easily write an application that loads streaming data from Kinesis into an Elasticsearch cluster in real-time and reliably at scale.
Elasticsearch is an open-source search and analytics engine. It indexes structured and unstructured data in real-time. Kibana is Elasticsearch’s data visualization engine; it is used by dev-ops and business analysts to setup interactive dashboards. Data in an Elasticsearch cluster can also be accessed programmatically using RESTful API or application SDKs. You can use the CloudFormation template in our sample to quickly create an Elasticsearch cluster on Amazon Elastic Compute Cloud (Amazon EC2), fully managed by Auto Scaling.
Wiring Kinesis, Elasticsearch, and Kibana
Here’s a block diagram to help you see how the pieces fit together:
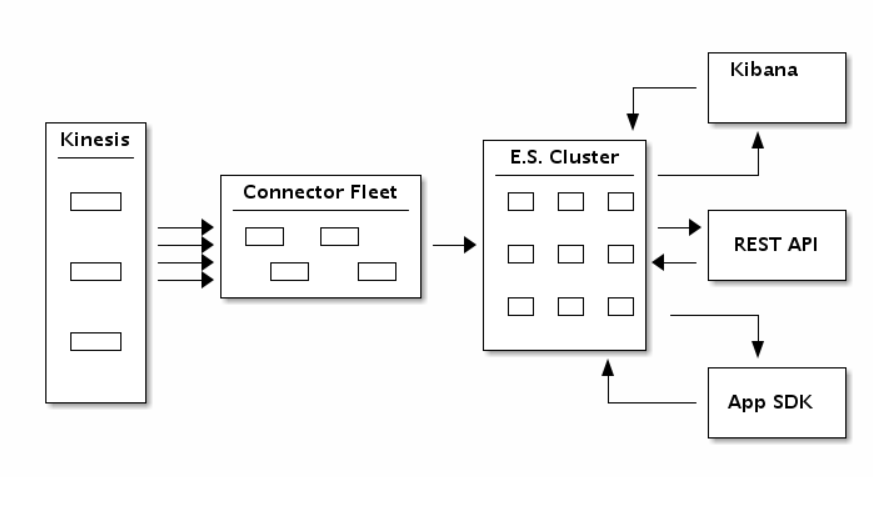
Using the new Kinesis Connector to Elasticsearch, you author an application to consume data from Kinesis Stream and index the data into an Elasticsearch cluster. You can transform, filter, and buffer records before emitting them to Elasticsearch. You can also finely tune Elasticsearch specific indexing operations to add fields like time to live, version number, type, and id on a per record basis. The flow of records is as illustrated in the diagram below.
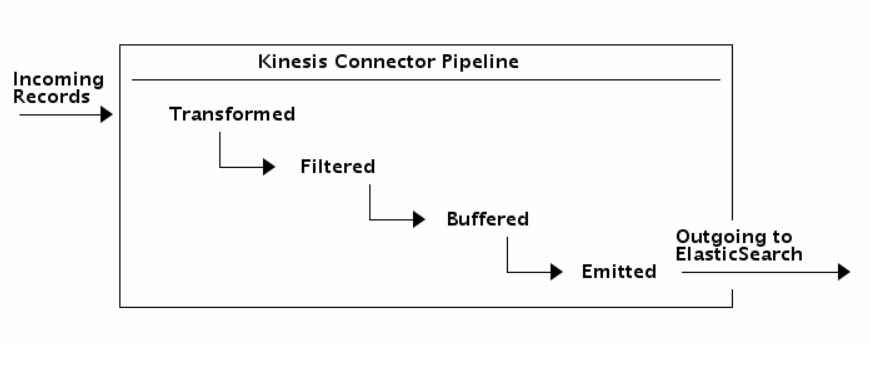
Note that you can also run the entire connector pipeline from within your Elasticsearch cluster using River.
Getting Started
Your code has the following duties:
- Set application specific configurations.
- Create and configure a
KinesisConnectorPipelinewith a Transformer, a Filter, a Buffer, and an Emitter. - Create a KinesisConnectorExecutor that runs the pipeline continuously.
All the above components come with a default implementation, which can easily be replaced with your custom logic.
Configure the Connector Properties
The sample comes with a .properties file and a configurator. There are many settings and you can leave most of them set to their default values. For example, the following settings will:
- Configure the connector to bulk load data into Elasticsearch only after you’ve collect at least 1000 records.
- Use the local Elasticsearch cluster endpoint for testing.
bufferRecordCountLimit = 1000
elasticSearchEndpoint = localhost
Implementing Pipeline Components
In order to wire the Transformer, Filter, Buffer, and Emitter, your code must implement the IKinesisConnectorPipeline interface.
public class ElasticSearchPipeline implements
IKinesisConnectorPipeline
public IEmitter getEmitter
(KinesisConnectorConfiguration configuration) {
return new ElasticSearchEmitter(configuration);
}
public IBuffer getBuffer(
KinesisConnectorConfiguration configuration) {
return new BasicMemoryBuffer(configuration);
}
public ITransformerBase getTransformer
(KinesisConnectorConfiguration configuration) {
return new StringToElasticSearchTransformer();
}
public IFilter getFilter
(KinesisConnectorConfiguration configuration) {
return new AllPassFilter();
}
The following snippet implements the abstract factory method, indicating the pipeline you wish to use:
public KinesisConnectorRecordProcessorFactory
getKinesisConnectorRecordProcessorFactory() {
return new KinesisConnectorRecordProcessorFactory(new ElasticSearchPipeline(), config);
}
Defining an Executor
The following snippet defines a pipeline where the incoming Kinesis records are strings and outgoing records are an ElasticSearchObject:
public class ElasticSearchExecutor extends
KinesisConnectorExecutor
The following snippet implements the main method, creates the Executor and starts running it:
public static void main(String[] args) {
KinesisConnectorExecutor executor
= new ElasticSearchExecutor(configFile);
executor.run();
}
 From here, make sure your AWS Credentials are provided correctly. Setup the project dependencies using
From here, make sure your AWS Credentials are provided correctly. Setup the project dependencies using ant setup. To run the app, use ant run and watch it go! All of the code is on GitHub, so you can get started immediately. Please post your questions and suggestions on the Kinesis Forum.
Kinesis Client Library and Kinesis Connector Library
When we launched Kinesis in November of 2013, we also introduced the Kinesis Client Library. You can use the client library to build applications that process streaming data. It will handle complex issues such as load-balancing of streaming data, coordination of distributed services, while adapting to changes in stream volume, all in a fault-tolerant manner.
We know that many developers want to consume and process incoming streams using a variety of other AWS and non-AWS services. In order to meet this need, we released the Kinesis Connector Library late last year with support for Amazon DynamoDB, Amazon Redshift, and Amazon Simple Storage Service (Amazon S3). We then followed up that with a Kinesis Storm Spout and Amazon EMR connector earlier this year. Today we are expanding the Kinesis Connector Library with support for Elasticsearch.
— Rahul