AWS Big Data Blog
Category: Amazon EMR
Install Python libraries on a running cluster with EMR Notebooks
This post discusses installing notebook-scoped libraries on a running cluster directly via an EMR Notebook. Before this feature, you had to rely on bootstrap actions or use custom AMI to install additional libraries that are not pre-packaged with the EMR AMI when you provision the cluster. This post also discusses how to use the pre-installed Python libraries available locally within EMR Notebooks to analyze and plot your results. This capability is useful in scenarios in which you don’t have access to a PyPI repository but need to analyze and visualize a dataset.

Secure your Amazon EMR cluster from unintentional network exposure with Block Public Access configuration
This post discusses a new account level feature called Block Public Access (BPA) configuration that helps administrators enforce a common public access rule across all of their EMR clusters in a region.

Implement perimeter security in Amazon EMR using Apache Knox
Perimeter security helps secure Apache Hadoop cluster resources to users accessing from outside the cluster. It enables a single access point for all REST and HTTP interactions with Apache Hadoop clusters and simplifies client interaction with the cluster. For example, client applications must acquire Kerberos tickets using Kinit or SPNEGO before interacting with services on Kerberos enabled clusters. In this post, we walk through setup of Apache Knox to enable perimeter security for EMR clusters.

Run Spark applications with Docker using Amazon EMR 6.0.0 (Beta)
This post shows you how to use Docker with the EMR release 6.0.0 Beta. You’ll learn how to launch an EMR release 6.0.0 Beta cluster and run Spark jobs using Docker containers from both Docker Hub and Amazon ECR.
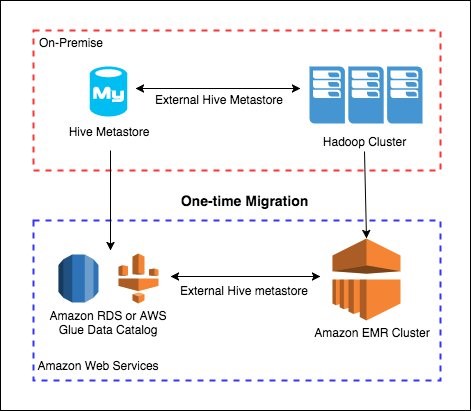
Migrate and deploy your Apache Hive metastore on Amazon EMR
Combining the speed and flexibility of Amazon EMR with the utility and ubiquity of Apache Hive provides you with the best of both worlds. However, getting started with big data projects can feel intimidating. Whether you want to deploy new data on EMR or migrate an existing project, this post provides you with the basics to get started.

Modify your cluster on the fly with Amazon EMR reconfiguration
April 2024: This post was reviewed for accuracy. If you are a developer or data scientist using long-running Amazon EMR clusters, you face fast-changing workloads. These changes often require different application configurations to run optimally on your cluster. With the reconfiguration feature, you can now change configurations on running EMR clusters. Starting with EMR release […]

Performance updates to Apache Spark in Amazon EMR 5.24 – Up to 13x better performance compared to Amazon EMR 5.16
Amazon EMR release 5.24.0 includes several optimizations in Spark that improve query performance. To evaluate the performance improvements, we used TPC-DS benchmark queries with 3-TB scale and ran them on a 6-node c4.8xlarge EMR cluster with data in Amazon S3. We observed up to 13X better query performance on EMR 5.24 compared to EMR 5.16 when operating with a similar configuration.
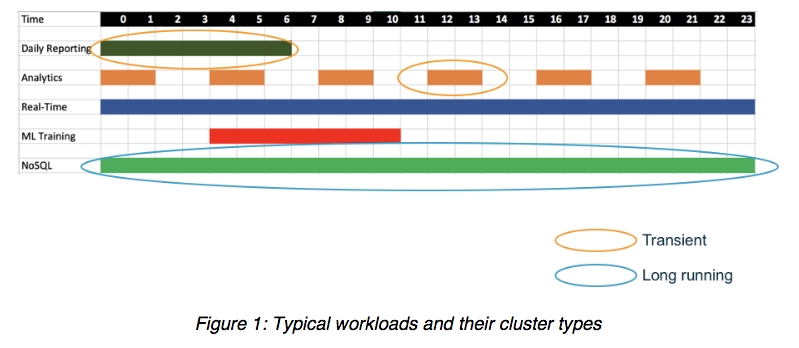
Amazon EMR Migration Guide
Today, we’re introducing the Amazon EMR Migrations Guide (first published June 2019.) This paper is a comprehensive guide to offer sound technical advice to help customers in planning how to move from on-premises big data deployments to EMR.

Optimize downstream data processing with Amazon Data Firehose and Amazon EMR running Apache Spark
This blog post shows how to use Amazon Kinesis Data Firehose to merge many small messages into larger messages for delivery to Amazon S3, which results in faster processing with Amazon EMR running Spark. This post also shows how to read the compressed files using Apache Spark that are in Amazon S3, which does not have a proper file name extension and store back in Amazon S3 in parquet format.

Trigger cross-region replication of pre-existing objects using Amazon S3 inventory, Amazon EMR, and Amazon Athena
In Amazon Simple Storage Service (Amazon S3), you can use cross-region replication (CRR) to copy objects automatically and asynchronously across buckets in different AWS Regions. CRR is a bucket-level configuration, and it can help you meet compliance requirements and minimize latency by keeping copies of your data in different Regions. CRR replicates all objects in […]