AWS Big Data Blog
Centralize governance for your data lake using AWS Lake Formation while enabling a modern data architecture with Amazon Redshift Spectrum
Many customers are modernizing their data architecture using Amazon Redshift to enable access to all their data from a central data location. They are looking for a simpler, scalable, and centralized way to define and enforce access policies on their data lakes on Amazon Simple Storage Service (Amazon S3). They want access policies to allow their data lake consumers to use the analytics service of their choice, to best suit the operations they want to perform on the data. Although the existing method of using Amazon S3 bucket policies to manage access control is an option, when the number of combinations of access levels and users increase, managing bucket level policies may not scale.
AWS Lake Formation allows you to simplify and centralize access management. It allows organizations to manage access control for Amazon S3-based data lakes using familiar concepts of databases, tables, and columns (with more advanced options like row and cell-level security). Lake Formation uses the AWS Glue Data Catalog to provide access control for Amazon S3 data lake with most commonly used AWS analytics services, like Amazon Redshift (via Amazon Redshift Spectrum), Amazon Athena, AWS Glue ETL, and Amazon EMR (for Spark-based notebooks). These services honor the Lake Formation permissions model out of the box, which makes it easy for customers to simplify, standardize, and scale data security management for data lakes.
With Amazon Redshift, you can build a modern data architecture, to seamlessly extend your data warehouse to your data lake and read all data – data in your data warehouse, and data in your data lake – without creating multiple copies of data. Amazon Redshift Spectrum feature enable direct query of your S3 data lake, and many customers are leveraging this to modernize their data platform. You can use Amazon Redshift managed storage for frequently accessed data and move less frequently accessed data to Amazon S3 data lake and securely access it using Redshift Spectrum.
In this post, we discuss how you can use AWS Lake Formation to centralize data governance and data access management while using Amazon Redshift Spectrum to query your data lake. Lake Formation allows you to grant and revoke permissions on databases, tables, and column catalog objects created on top of Amazon S3 data lake. This is easier for customers, as it is similar to managing permissions on relational databases.
In the first post of this two-part series, we focus on resources within the same AWS account. In the second post, we extend the solution across AWS accounts using the Lake Formation data sharing feature.
Solution overview
The following diagram illustrates our solution architecture.
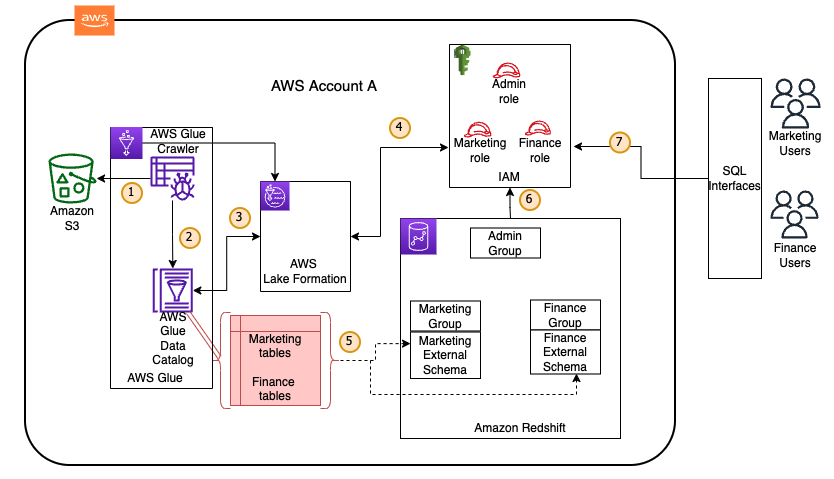
The solution workflow consists of the following steps:
- Data stored in an Amazon S3 data lake is crawled using an AWS Glue crawler.
- The crawler infers the metadata of data on Amazon S3 and stores it in the form of a database and tables in the AWS Glue Data Catalog.
- You register the Amazon S3 bucket as the data lake location with Lake Formation. It’s natively integrated with the Data Catalog.
- You use Lake Formation to grant permissions at the database, table, and column level to defined AWS Identity and Access Management (IAM) roles.
- You create external schemas within Amazon Redshift to manage access for marketing and finance teams.
- You provide access to the marketing and finance groups to their respective external schemas and associate the appropriate IAM roles to be assumed. The admin role and admin group is limited for administration work.
- Marketing and finance users now can assume their respective IAM roles and query data using the SQL query editor to their external schemas inside Amazon Redshift.
Lake Formation default security settings
To maintain backward compatibility with AWS Glue, Lake Formation has the following initial security settings:
- The super permission is granted to the group
IAMAllowedPrincipalson all existing Data Catalog resources. - Settings to use only IAM access control are enabled for new Data Catalog resources.
To change security settings, see Changing the Default Security Settings for Your Data Lake.
Note: Leave the default settings as is until you’re ready to move completely to the Lake Formation permission model. You can update settings at a database level if you want permissions set by Lake Formation to take effect. For more details about upgrades, refer to Upgrading AWS Glue Data Permissions to the AWS Lake Formation Model.
We don’t recommend reverting back from the Lake Formation permission model to an IAM-only permission model. You may also want to first deploy the solution in a new test account.
Prerequisites
To set up this solution, you need basic familiarity with the AWS Management Console, an AWS account, and access to the following AWS services:
- AWS CloudFormation
- AWS Glue
- IAM
- Lake Formation
- AWS Lambda
- Amazon Redshift
- Amazon S3
- AWS Step Functions
- Amazon Virtual Private Cloud (Amazon VPC)
Create the data lake administrator
Data lake administrators are initially the only IAM users or roles that can grant Lake Formation permissions on data locations and Data Catalog resources to any principal.
To set up an IAM user as a data lake administrator, add the provided inline policy to the IAM user or IAM role you use to provision the resources for this blog solution. For more details, refer to Create a Data Lake Administrator.
- On the IAM console, choose Users, and choose the IAM user who you want to designate as the data lake administrator.
- Choose Add an inline policy on the Permissions tab and add the following policy:
- Provide a policy name.
- Review and save your settings.
Note: If you’re using an existing administrator user/role, you may have this already provisioned.
- Sign in to the AWS management console as the designated data lake administrator IAM user or role for this solution.
Note: The CloudFormation template doesn’t work if you skip the below step.
- If this is your first time on the Lake Formation console, select Add myself and choose Get started.

You can also add yourself as data lake administrator by going to Administrative roles and tasks under Permissions, select Choose administrators, and adding yourself as an administrator if you missed this in the initial welcome screen.
Provision resources with CloudFormation
In this step, we create the solution resources using a CloudFormation template. The template performs the following actions:
- Creates an S3 bucket to copy sample data files and SQL scripts
- Registers the S3 data lake location with Lake Formation
- Creates IAM roles and policies as needed for the environment
- Assigns principals (IAM roles) to handle data lake settings
- Creates Lambda and Step Functions resources to load necessary data
- Runs AWS Glue crawler jobs to create Data Catalog tables
- Configures Lake Formation permissions
- Creates an Amazon Redshift cluster
- Runs a SQL script to create the database group, database user, and external schemas for the admin, marketing, and finance groups
To create your resources, complete the following steps:
- Launch the provided template in AWS Region
us-east-1. - Choose Next.
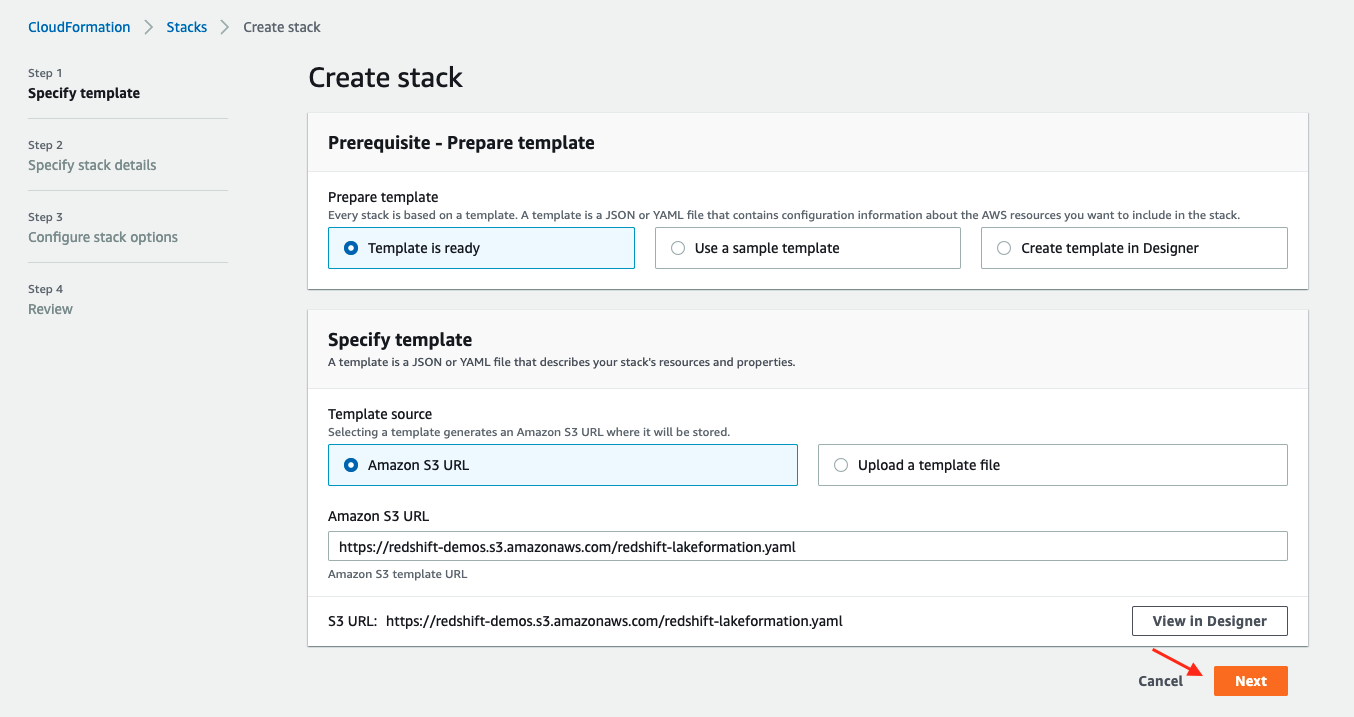
- For Stack name, you can keep the default stack name or change it.
- For DbPassword, provide a secure password instead of using the default provided.
- For InboundTraffic, change the IP address range to your local machine’s IP address in CIDR format instead of using the default.
- Choose Next.

- Choose Next again until you get to the review page.
- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.
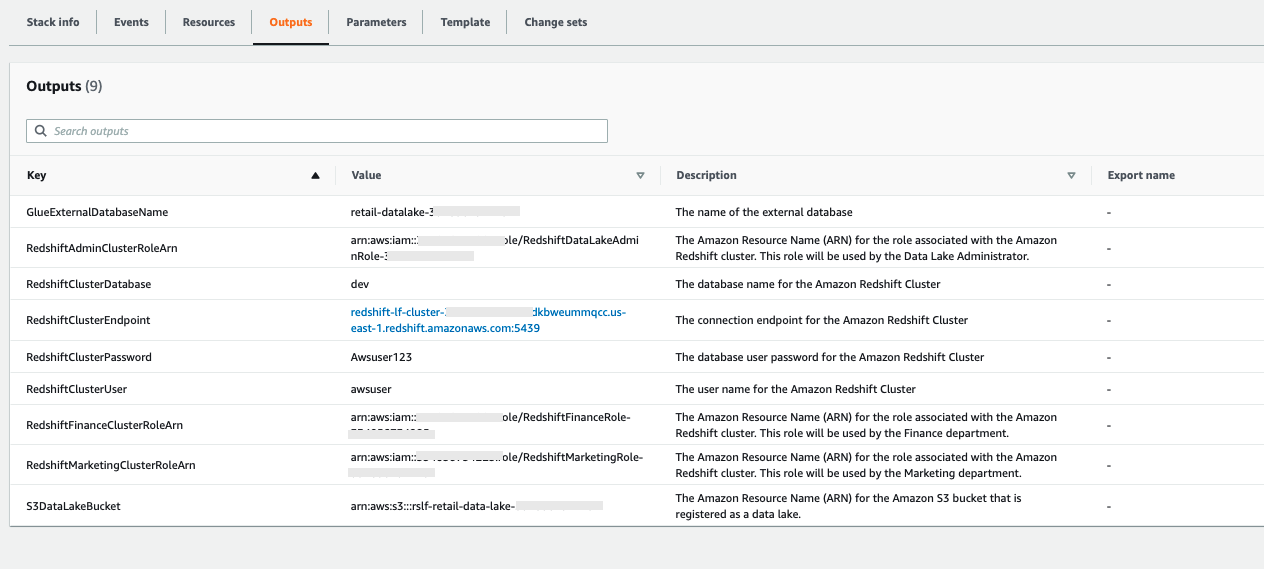
The stack takes approximately 10 minutes to deploy successfully. When it’s complete, you can view the outputs on the AWS CloudFormation console.
Update Lake Formation default settings
You also need to update the default settings at the Lake Formation database level. This makes sure that the Lake Formation permissions the CloudFormation template sets up during provisioning can take effect over the default settings.
- On the Lake Formation console, under Data catalog in the navigation pane, choose Databases.
- Choose the database you created with the CloudFormation template.

- Choose Edit.
- If selected, deselect Use only IAM access control for new tables in the database.
- Choose Save.

This action is important because it removes the IAM control model from this database and allows only Lake Formation to take security grant/revoke access to it. This step makes sure other steps in this solution are successful.
- Choose Databases in the navigation pane.
- Select the same database.
- On the Actions menu, choose View permissions.

You can review the permissions enabled for this database. Please note these steps 9-12 are required only if you have granted access to IAMAllowedPrincipals earlier.
- Select the
IAMAllowedPrincipalsgroup and choose Revoke to remove default permission settings for this individual database.
The IAMAllowedPrincipal row no longer appears in the list on the Permissions page.
Similarly, we need to remove the IAMAllowedPrincipal group at the table level. The CloudFormation template created six tables for this database. Let’s see how to use data lake permissions to remove access at the table level.
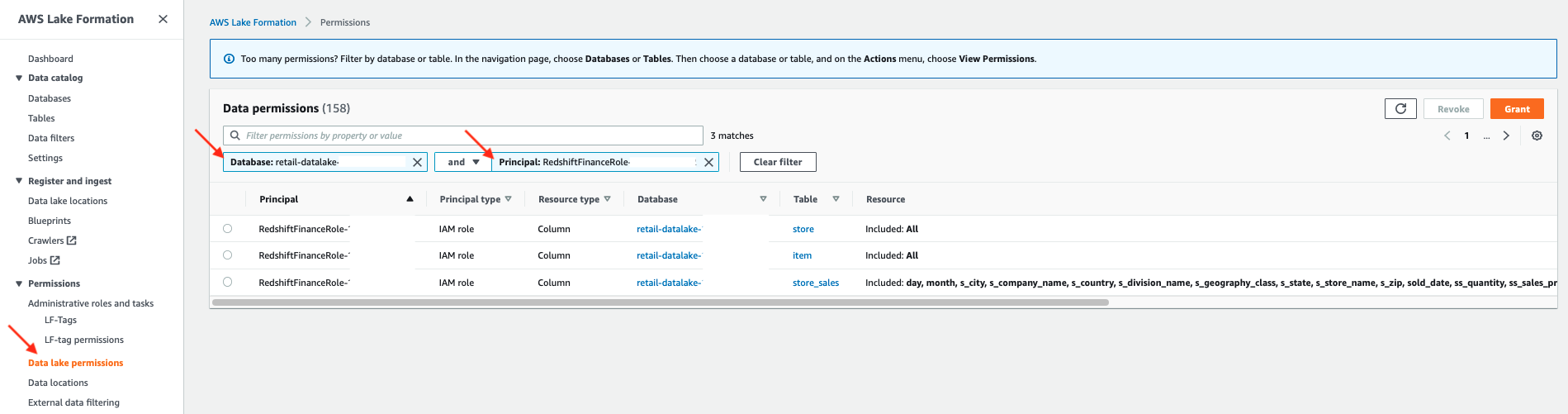
- On the Lake Formation console, choose Data lake permissions in the navigation pane.
- Filter by
Principal:IAMAllowedPrincipalsandDatabase:<<database name>>.
You can review all the tables we need to update permissions for.
- Select each table one by one and choose Revoke.
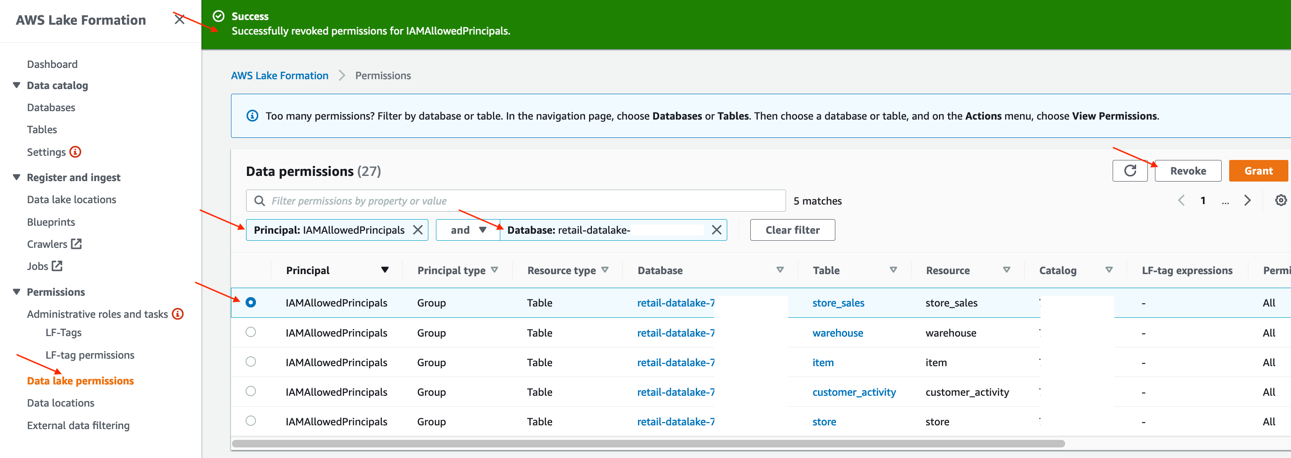
With these steps, we’ve made sure that the default settings at the Lake Formation account level are still in place, and only manually updated for the database and tables we’re going to work with in this post. When you’re ready to move completely to a Lake Formation permission model, you can update the settings at the account level instead of individually updating them. For more details, see Change the default permission model.
Validate the provisioned resources
The CloudFormation template provisions many resources automatically to create your environment. In this section, we check some of the key resources to understand them better.
Lake Formation resources
On the Lake Formation console, check that a new data lake location is registered with an IAM role on the Data lake locations page.
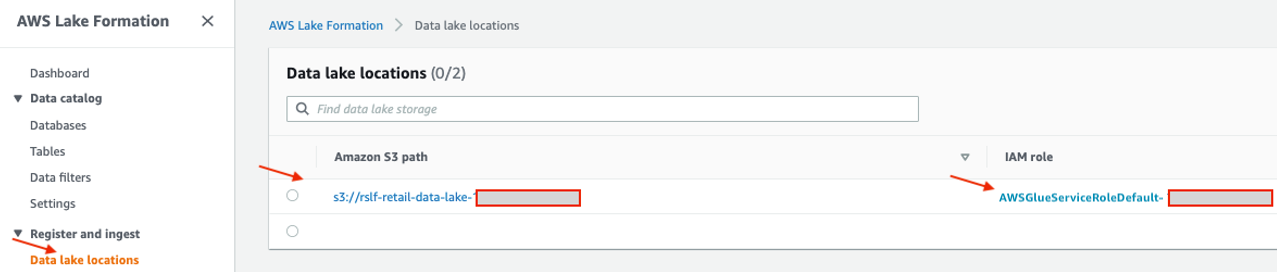
This is the IAM role any integrated service like Amazon Redshift assumes to access data on the registered Amazon S3 location. This integration happens out of the box when the right roles and policies are applied. For more details, see Requirements for Roles Used to Register Locations.
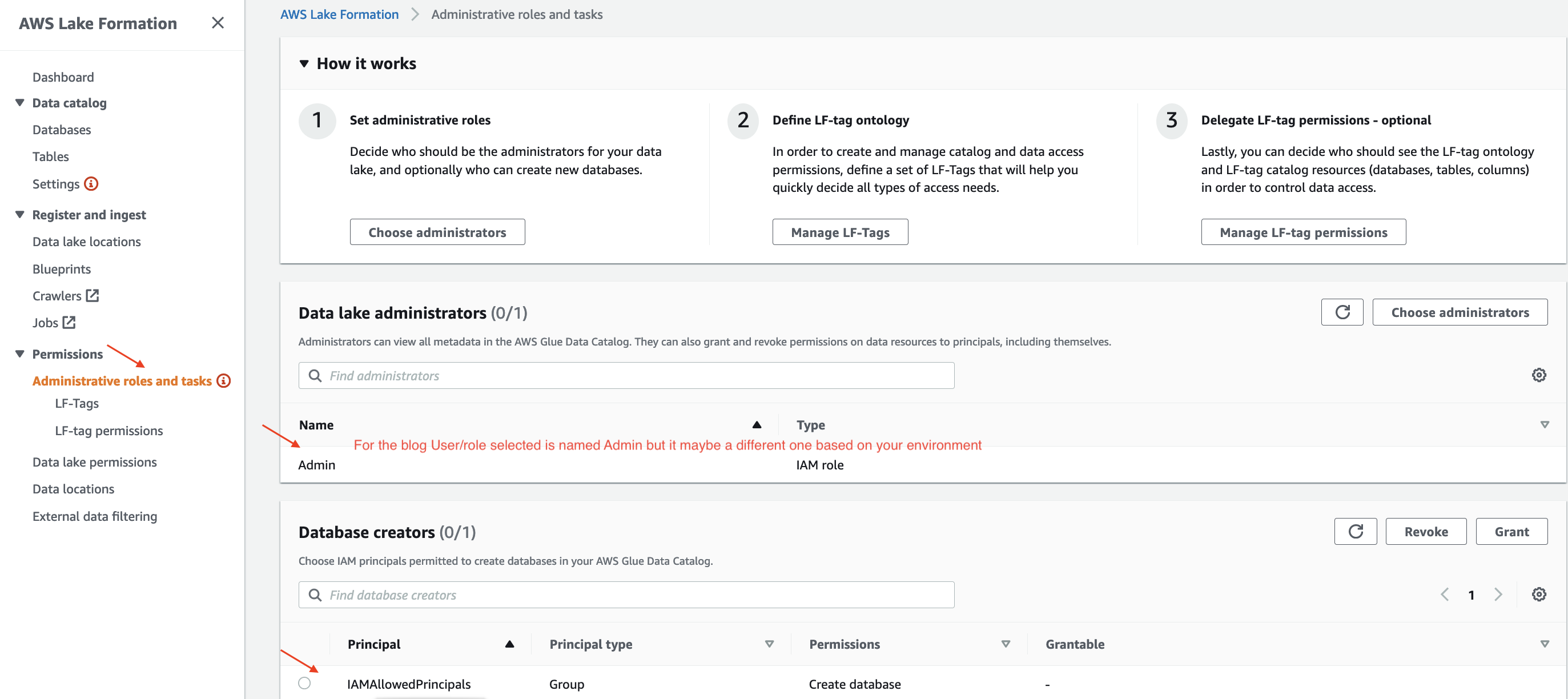
Check the Administrative roles and tasks page confirm that the logged-in user is added as the data lake administrator and IAMAllowedPrincipals is added as database creator.
Then check the tables that the AWS Glue crawlers created in the Data Catalog database. These tables are logical entities, because the data is in an Amazon S3 location. After you create these objects, you can access them via different services.
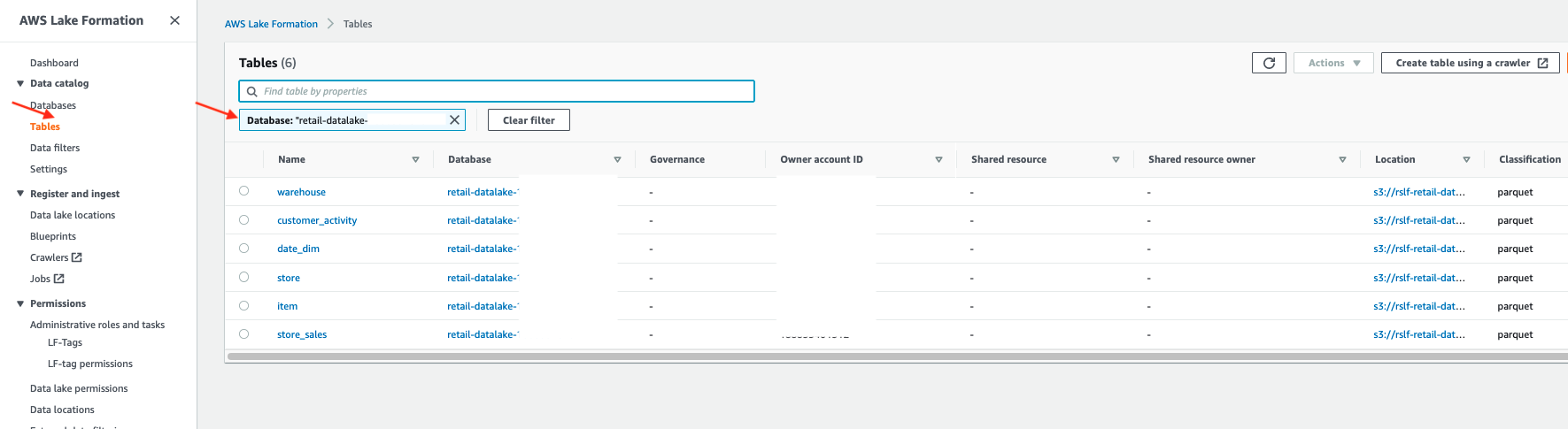
Lastly, check permissions set by the template using the Lake Formation permission model on the tables to be accessed by finance and marketing users from Amazon Redshift.
The following screenshot shows that the finance role has access to all columns for the store and item tables, but only the listed columns for the store_sales table.
Similarly, you can review access for the marketing role, which has access to all columns in the customer_activity and store_sales tables.

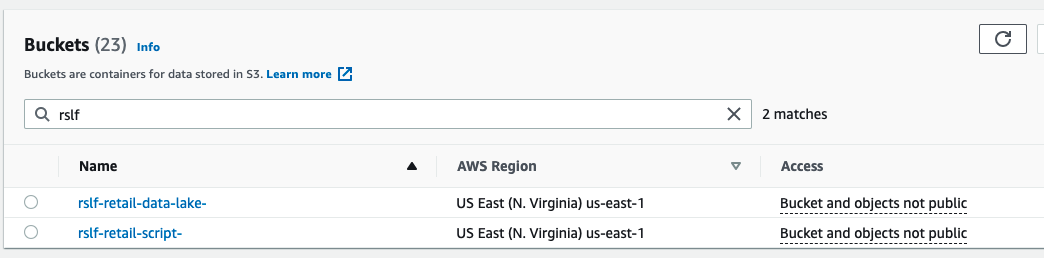
Amazon S3 resources
The CloudFormation template creates two S3 buckets:
- data-lake – Contains the data used for this post
- script – Contains the SQL which we use to create Amazon Redshift database objects
Open the script bucket to see the scripts. You can download and open them to view the SQL code used.
The setup_lakeformation_demo.sql script gives you the SQL code to create the external database schema and assign different roles for data governance purposes. The external schema is for AWS Glue Data Catalog-based objects that point to data in the data lake. We then grant access to different database groups and users to manage security for finance and marketing users.
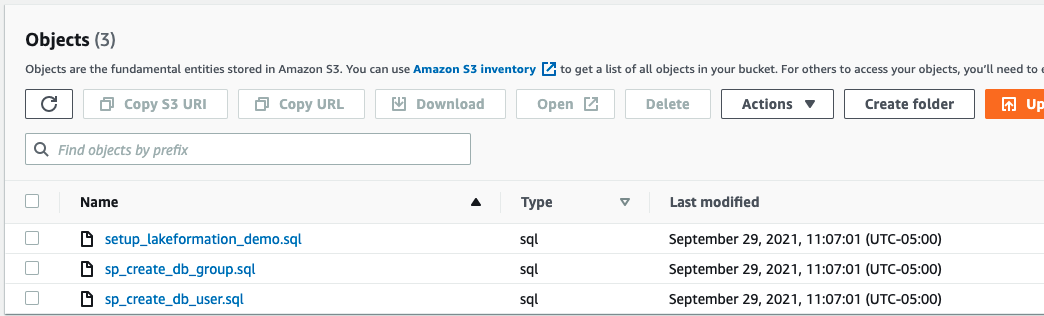
The scripts run in the following order:
sp_create_db_group.sqlsp_create_db_user.sqlsetup_lakeformation_demo.sql
Amazon Redshift resources
On the Amazon Redshift console, choose Clusters in the navigation pane and choose the cluster you created with the CloudFormation template. Then choose the Properties tab.

The Cluster permissions section lists three attached roles. The template used the admin role to provision Amazon Redshift database-level objects. The finance role is attached to the finance schema in Amazon Redshift, and the marketing role is attached to the marketing schema.

Each of these roles are given permissions in such a way that they can use the Amazon Redshift query editor to query Data Catalog tables using Redshift Spectrum. For more details, see Using Redshift Spectrum with AWS Lake Formation and Query the Data in the Data Lake Using Amazon Redshift Spectrum.
Query the data
We use Amazon Redshift query editor v2 to query the external schema and Data Catalog tables (external tables). The external schema is already created as part of the CloudFormation template. When the external schema is created using the Data Catalog, the tables in the database are automatically created and are available through Amazon Redshift as external tables.
- On the Amazon Redshift console, choose Query editor v2.
- Choose Configure account.
- Choose the database cluster.
- For Database, enter
dev. - For User name, enter
awsuser. - For Authentication, select Temporary credentials.
- Choose Create connection.
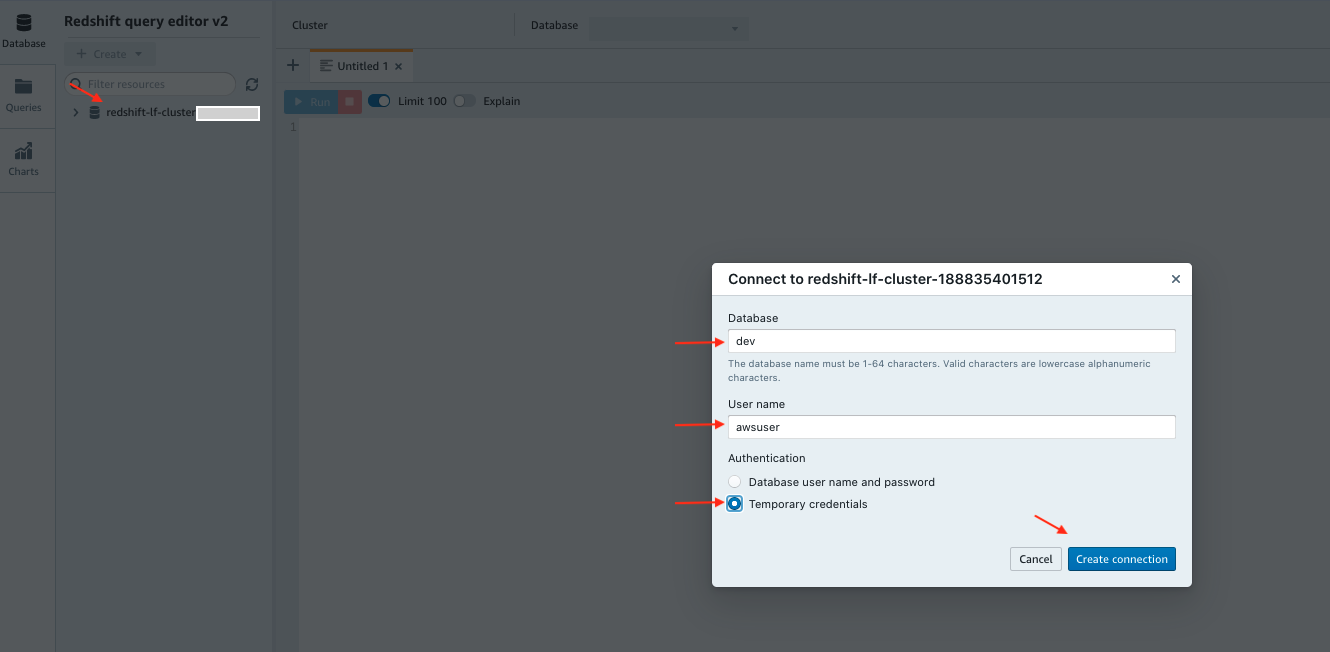
When you’re connected and logged in as administrator user, you can see both local and external schemas and tables, as shown in the following screenshot.
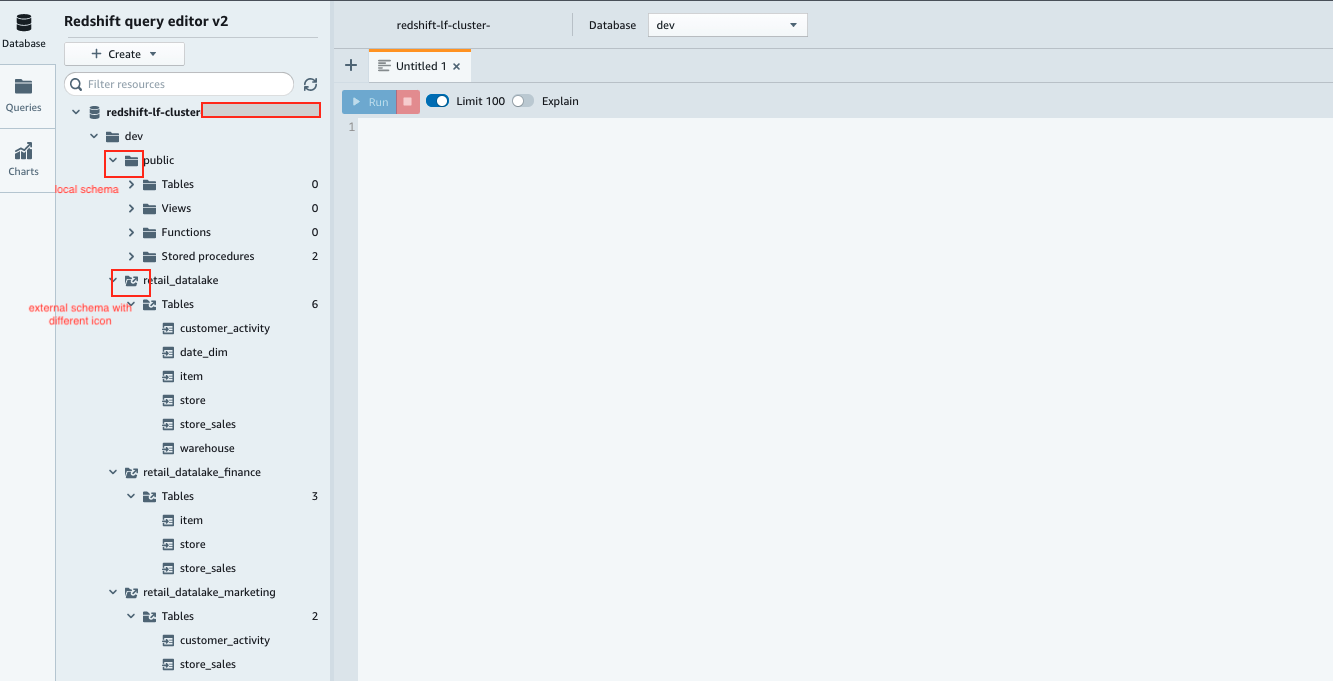
Validate role-based Lake formation permissions in Amazon Redshift
Next, we validate how the Lake Formation security settings work for the marketing and finance users.
- In the query editor, choose (right-click) the database connection.
- Choose Edit connection.
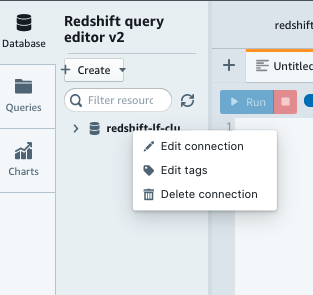
- For User name, enter
marketing_ro. - Choose Edit connection.

- After connected as
maketing_ro, choose the dev database under the cluster and navigate to thecustomer_activitytable. - Choose the refresh icon.

- Repeat these steps to edit the connection and update the user to
finance_ro.

- Try again to refresh the
devdatabase.
As expected, this user only has access to the allowed schema and tables.
With this solution, you can segregate different users at the schema level and use Lake Formation to make sure they can only see the tables and columns their role allows.
Column-level security with Lake Formation permissions
Lake Formation also allows you to set which columns a principal can or can’t see within a table. For example, when you select store_sales as the marketing_ro user, you see many columns, like customer_purchase_estimate. However, as the finance_ro user, you don’t see these columns.
Manual access control via the Lake Formation console
In this post, we’ve been working with a CloudFormation template-based environment, which is an automated way to create environment templates and simplify operations.
In this section, we show how you can set up all the configurations through the console, and we use another table as an example to walk you through the steps.
As demonstrated in previous steps, the marketing user in this environment has all column access to the tables customer_activity and store_sales in the external schema retail_datalake_marketing. We change some of that manually to see how it works using the console.
- On the Lake Formation console, choose Data lake permissions.
- Filter by the principal
RedshiftMarketingRole. - Select the principal for the
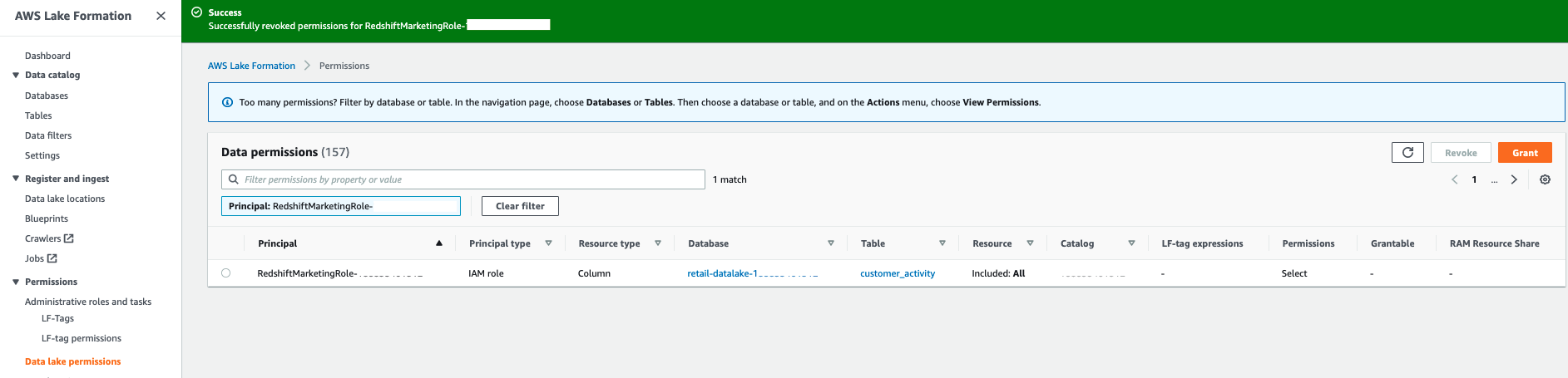
store_salestable and choose Revoke.

- Confirm by choosing Revoke again.

A success message appears, and the permission row is no longer listed.
- Choose Grant to configure a new permission level for the marketing user on the
store_salestable at the column level.

- Select IAM users and roles and choose your role.
- In the LF-Tags or catalog resources section, select Named data catalog resources.
- For Databases, choose your database.
- For Tables, choose the
store_salestable.

- For Table permissions¸ check Select.
- In the Data permissions section, select Simple column-based access.
- Select Exclude columns.
- Choose the columns as shown in the following screenshot.
- Choose Grant.

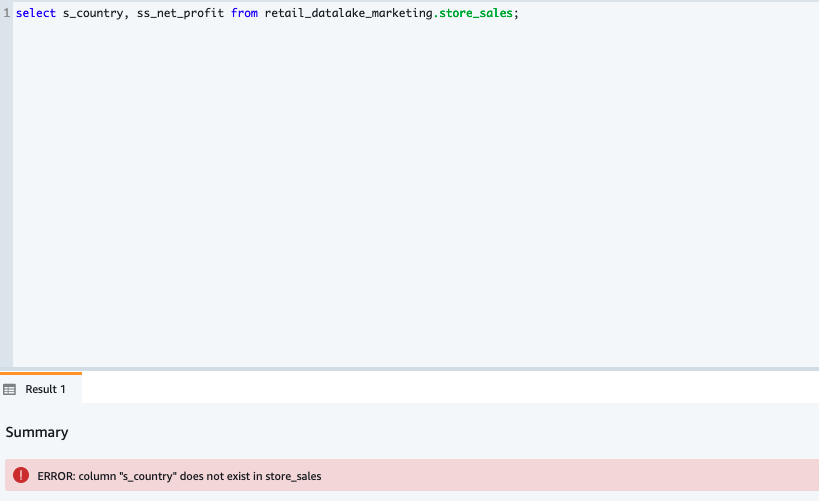
We now query the table from Amazon Redshift again to confirm that the effective changes match the controls placed by Lake Formation. In the following query, we select a column that isn’t authorized:
As expected, we get an error.
Clean up
Clean up resources created by the CloudFormation template to avoid unnecessary cost to your AWS account. You can delete the CloudFormation stack by selecting the stack on the AWS CloudFormation console and choosing Delete. This action deletes all the resources it provisioned. If you manually updated a template-provisioned resource, you may see some issues during clean-up, and you need to clean these up manually.
Summary
In this post, we showed how you can integrate Lake Formation with Amazon Redshift to seamlessly control access to Amazon S3 data lake. We also demonstrated how to query your data lake using Redshift Spectrum and external tables. This is a powerful mechanism that helps you build a modern data architecture to easily query data on your data lake and data warehouses together. We also saw how you can use CloudFormation templates to automate the resource creation with infrastructure as code. You can use this to simplify your operations, especially when you want replicate the resource setup from development to production landscape during your project cycles.
Finally, we covered how data lake administrators can manually control search on data catalog objects and grant or revoke access at the database, table, and column level. We encourage you to try the steps we outlined in this post and use the CloudFormation template to set up security in Lake Formation to control data lake access from Redshift Spectrum.
In the second post of this series, we focus on how you can take this concept and apply it across accounts using a Lake Formation data-sharing feature in a hub-and-spoke topography.
About the Authors
 Vaibhav Agrawal is an Analytics Specialist Solutions Architect at AWS. Throughout his career, he has focused on helping customers design and build well-architected analytics and decision support platforms.
Vaibhav Agrawal is an Analytics Specialist Solutions Architect at AWS. Throughout his career, he has focused on helping customers design and build well-architected analytics and decision support platforms.
 Jason Pedreza is an Analytics Specialist Solutions Architect at AWS with over 13 years of data warehousing experience. Prior to AWS, he built data warehouse solutions at Amazon.com. He specializes in Amazon Redshift and helps customers build scalable analytic solutions.
Jason Pedreza is an Analytics Specialist Solutions Architect at AWS with over 13 years of data warehousing experience. Prior to AWS, he built data warehouse solutions at Amazon.com. He specializes in Amazon Redshift and helps customers build scalable analytic solutions.
 Rajesh Francis is a Senior Analytics Customer Experience Specialist at AWS. He specializes in Amazon Redshift and focuses on helping to drive AWS market and technical strategy for data warehousing and analytics services. Rajesh works closely with large strategic customers to help them adopt our new services and features, develop long-term partnerships, and feed customer requirements back to our product development teams to guide our product roadmap.
Rajesh Francis is a Senior Analytics Customer Experience Specialist at AWS. He specializes in Amazon Redshift and focuses on helping to drive AWS market and technical strategy for data warehousing and analytics services. Rajesh works closely with large strategic customers to help them adopt our new services and features, develop long-term partnerships, and feed customer requirements back to our product development teams to guide our product roadmap.