AWS Big Data Blog
How Morningstar used tag-based access controls in AWS Lake Formation to manage permissions for an Amazon Redshift data warehouse
This post was co-written by Ashish Prabhu, Stephen Johnston, and Colin Ingarfield at Morningstar and Don Drake, at AWS.
With “Empowering Investor Success” as the core motto, Morningstar aims at providing our investors and advisors with the tools and information they need to make informed investment decisions.
In this post, Morningstar’s Data Lake Team Leads discuss how they utilized tag-based access control in their data lake with AWS Lake Formation and enabled similar controls in Amazon Redshift.
The business challenge
At Morningstar, we built a data lake solution that allows our consumers to easily ingest data, make it accessible via the AWS Glue Data Catalog, and grant access to consumers to query the data via Amazon Athena. In this solution, we were required to ensure that the consumers could only query the data to which they had explicit access. To enforce our access permissions, we chose Lake Formation tag-based access control (TBAC). TBAC helps us categorize the data into a simple, broad level or a complex, more granular level using tags and then grant consumers access to those tags based on what group of data they need. Tag-based entitlements allow us to have a flexible and manageable entitlements system that solves our complex entitlements scenarios.
However, our consumers pushed us for better query performance and enhanced analytical capabilities. We realized we needed a data warehouse to cater to all of these consumer requirements, so we evaluated Amazon Redshift. Amazon Redshift provides us with features that we could use to work with our consumers and enable their analytical requirements:
- Better performance for consumers’ analytical requirements
- Ability to tune query performance with user-specified sort keys and distribution keys
- Ability to have different representations of the same data via views and materialized views
- Consistent query performance regardless of concurrency
Many new Amazon Redshift features helped solve and scale our analytical query requirements, specifically Amazon Redshift Serverless and Amazon Redshift data sharing.
Because our Lake Formation-enforced data lake is a central data repository for all our data, it makes sense for us to flow the data permissions from the data lake into Amazon Redshift. We utilize AWS Identity and Access Management (IAM) authentication and want to centralize the governance of permissions based on IAM roles and groups. For each AWS Glue database and table, we have a corresponding Amazon Redshift schema and table. Our goal was to ensure customers who have access to AWS Glue tables via Lake Formation also have access to the corresponding tables in Amazon Redshift.
However, we faced a problem with user-based entitlements as we moved to Amazon Redshift.
The entitlements problem
Even though we added Amazon Redshift as part of our overall solution, the entitlement requirements and challenges that came with it remained the same for our users consuming via Lake Formation. At the same time, we had to find a way to implement entitlements in our Amazon Redshift data warehouse with the same set of tags that we had already defined in Lake Formation. Amazon Redshift supports resource-based entitlements but doesn’t support tag-based entitlements. The challenge we had to overcome was how to map our existing tag-based entitlements in Lake Formation to the resource-based entitlements in Amazon Redshift.
The data in the AWS Glue Data Catalog needed to be also loaded in the Amazon Redshift data warehouse native tables. This was necessary so that the users get a familiar list of schema and tables that they are accustomed to seeing in the Data Catalog when accessing via Athena. This way, our existing data lake consumers could easily transition to Amazon Redshift.
The following diagram illustrates the structure of the AWS Glue Data Catalog mapped 1:1 with the structure of our Amazon Redshift data warehouse.

We wanted to utilize the ontology of tags in Lake Formation to also be used on the datasets in Amazon Redshift so that consumers could be granted access to the same datasets in both places. This enabled us to have a single entitlement policy source API that would grant appropriate access to both our Amazon Redshift tables as well as the corresponding Lake Formation tables based on the Lake Formation tag-based policies.
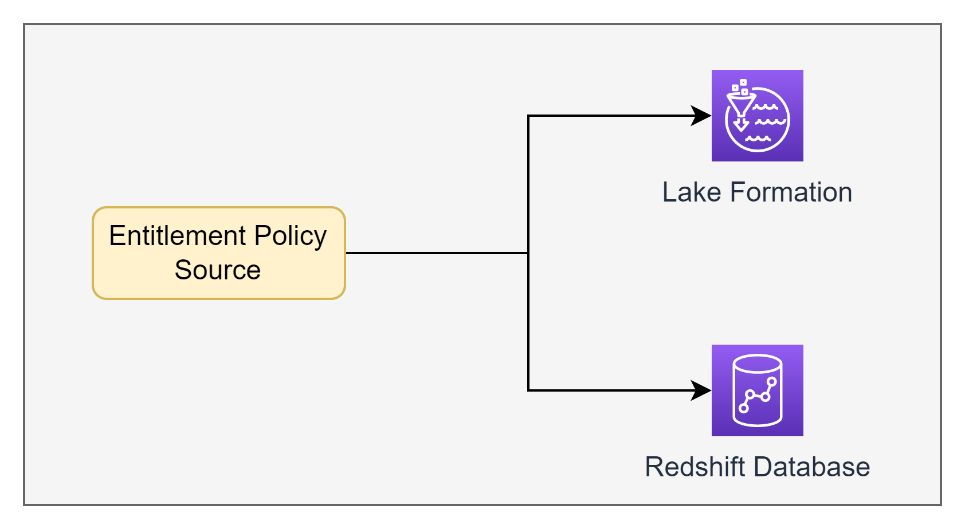
To solve this problem, we needed to build our own solution to convert the tag-based policies in Lake Formation into grants and revokes in the resource-based entitlements in Amazon Redshift.
Solution overview
To solve this mismatch, we wanted to synchronize our Lake Formation tag ontology and classifications to the Amazon Redshift permission model. To do this, we map Lake Formation tags and grants to Amazon Redshift grants with the following steps:
- Map all the resources (databases, schemas, tables, and more) in Lake Formation that are tagged to their equivalent Amazon Redshift tables.
- Translate each policy in Lake Formation on a tag expression to a set of Amazon Redshift table grants and revokes.
The net result is that when there is a tag or policy change in Lake Formation, a corresponding set of grants or revokes are made to the equivalent Amazon Redshift tables to keep our entitlements in sync.
Map all tagged resources in Lake Formation to Amazon Redshift equivalents
The tag-based access control of Lake Formation allowed us to apply multiple tags on a single resource (database and table) in the AWS Glue Data Catalog. If visualized in a mapping form, the resource tagging can be displayed as how multiple tags on a single table would be flattened into individual entitlements on Amazon Redshift tables.
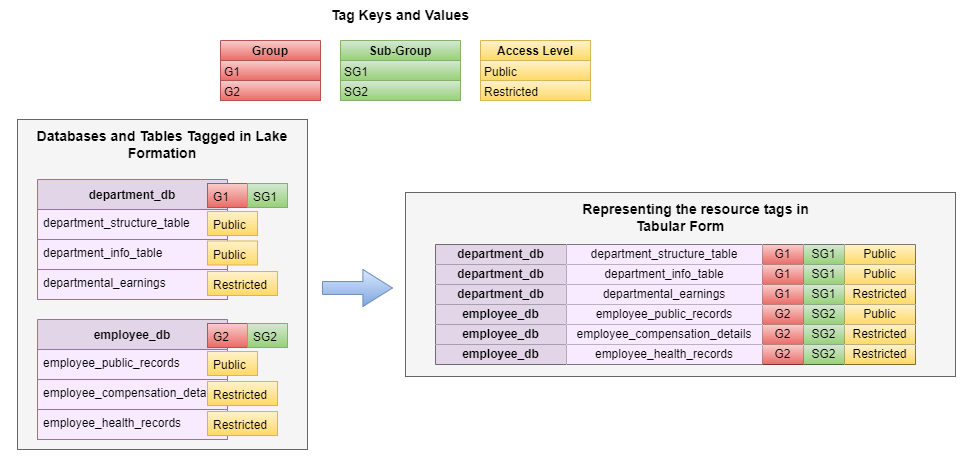
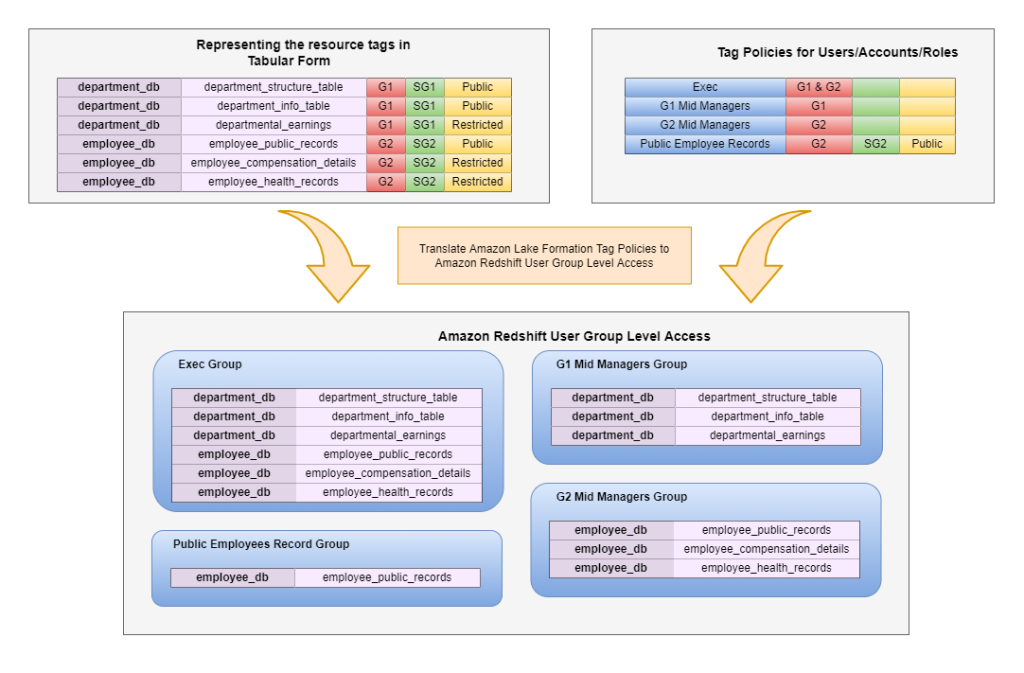
Translate tags to Amazon Redshift grants and revokes
To enable the migration of the tag-based policy enforced in Lake Formation, the permissions can be converted into simple grants and revokes that can be done on a per-group level.
There are two fundamental parts to a tag policy: the principal_id and the tag expression (for example, “Acess Level” = “Public”). Assuming that we have an Amazon Redshift database group for each principal_id, then the resources that represent the tag expression can be permissioned accordingly. We plan on migrating from database groups to database roles in a future implementation.
The solution implementation
The implementation of this solution led us to develop two components:
- The mapper service
- The Amazon Redshift data configuration
The mapper service can be thought of as a translation service. As the name suggests, it has the core business logic to map the tag and policy information into resource-based grants and revokes in Amazon Redshift. It needs to mimic the behavior of Lake Formation when handling the tag policy translation.
To do this translation, the mapper needs to understand and store the metadata at two levels:
- Understanding what resource in Amazon Redshift is to be tagged with what value
- Tracking the grants and revokes already performed so they can be updated with changes in the policy
To do this, we created a config schema in our Amazon Redshift cluster, which currently stores all the configurations.
As part of our implementation, we store the mapped (translated) information in Amazon Redshift. This allows us to incrementally update table grants as Lake Formation tags or policies changed. The following diagram illustrates this schema.

Business impact and value
The solution we put together has created key business impacts and values out of the current implementation and allows us greater flexibility in the future.
It allows us to get the data to our users faster with the tag policies applied in Lake Formation and translated directly to permissions in Amazon Redshift with immediate effect. It also allows us to have consistency in permissions applied in both Lake Formation and Amazon Redshift, based on the effective permissions derived from tag policies. And all this happens via a single source that grants and revokes permissions across the board, instead of managing them separately.
If we translate this into the business impact and business value that we generate, the solution improves the time to market of our data, but at the same time provides consistent entitlements across the business-driven categories that we define as tags.
The solution also opens up solutions to add more impact as our product scales both horizontally and vertically. There are potential solutions we could implement in terms of automation, users self-servicing their permissions, auditing, dashboards, and more. As our business scales, we expect to take advantage of these capabilities.
Conclusion
In this post, we shared how Morningstar utilized tag-based access control in our data lake with Lake Formation and enabled similar controls in Amazon Redshift. We developed two components that handle mapping of the tag-based access controls to Amazon Redshift permissions. This solution has improved the time to market for our data and provides consistent entitlements across different business-driven categories.
If you have any questions or comments, please leave them in the comments section.
About the Authors
 Ashish Prabhu is a Senior Manager of Software Engineering in Morningstar, Inc. He focuses on the solutioning and delivering the different aspects of Data Lake and Data Warehouse for Morningstar’s Enterprise Data and Platform Team. In his spare time he enjoys playing basketball, painting and spending time with his family.
Ashish Prabhu is a Senior Manager of Software Engineering in Morningstar, Inc. He focuses on the solutioning and delivering the different aspects of Data Lake and Data Warehouse for Morningstar’s Enterprise Data and Platform Team. In his spare time he enjoys playing basketball, painting and spending time with his family.
 Stephen Johnston is a Distinguished Software Architect at Morningstar, Inc. His focus is on data lake and data warehousing technologies for Morningstar’s Enterprise Data Platform team.
Stephen Johnston is a Distinguished Software Architect at Morningstar, Inc. His focus is on data lake and data warehousing technologies for Morningstar’s Enterprise Data Platform team.
 Colin Ingarfield is a Lead Software Engineer at Morningstar, Inc. Based in Austin, Colin focuses on access control and data entitlements on Morningstar’s growing Data Lake platform.
Colin Ingarfield is a Lead Software Engineer at Morningstar, Inc. Based in Austin, Colin focuses on access control and data entitlements on Morningstar’s growing Data Lake platform.
 Don Drake is a Senior Analytics Specialist Solutions Architect at AWS. Based in Chicago, Don helps Financial Services customers migrate workloads to AWS.
Don Drake is a Senior Analytics Specialist Solutions Architect at AWS. Based in Chicago, Don helps Financial Services customers migrate workloads to AWS.