AWS Big Data Blog
Orchestrate big data workflows with Apache Airflow, Genie, and Amazon EMR: Part 1
December 2023: This post was reviewed and we recommend referring to the following blog posts for more recent and relevant for orchestrating big data workloads:
- Orchestrate big data jobs on on-premises clusters with AWS Step Functions
- Orchestrate Amazon EMR Serverless jobs with AWS Step functions
- Prepare, transform, and orchestrate your data using AWS Glue DataBrew, AWS Glue ETL, and AWS Step Functions
- Simplify AWS Glue job orchestration and monitoring with Amazon MWAA
Large enterprises running big data ETL workflows on AWS operate at a scale that services many internal end-users and runs thousands of concurrent pipelines. This, together with a continuous need to update and extend the big data platform to keep up with new frameworks and the latest releases of big data processing frameworks, requires an efficient architecture and organizational structure that both simplifies management of the big data platform and promotes easy access to big data applications.
This post introduces an architecture that helps centralized platform teams maintain a big data platform to service thousands of concurrent ETL workflows, and simplifies the operational tasks required to accomplish that.
Architecture components
At high level, the architecture uses two open source technologies with Amazon EMR to provide a big data platform for ETL workflow authoring, orchestration, and execution. Genie provides a centralized REST API for concurrent big data job submission, dynamic job routing, central configuration management, and abstraction of the Amazon EMR clusters. Apache Airflow provides a platform for job orchestration that allows you to programmatically author, schedule, and monitor complex data pipelines. Amazon EMR provides a managed cluster platform that can run and scale Apache Hadoop, Apache Spark, and other big data frameworks.
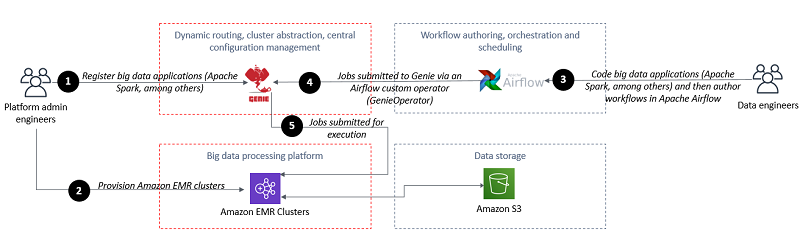
The following diagram illustrates the architecture.
Apache Airflow
Apache Airflow is an open source tool for authoring and orchestrating big data workflows.
With Apache Airflow, data engineers define direct acyclic graphs (DAGs). DAGs describe how to run a workflow and are written in Python. Workflows are designed as a DAG that groups tasks that are executed independently. The DAG keeps track of the relationships and dependencies between tasks.
Operators define a template to define a single task in the workflow. Airflow provides operators for common tasks, and you can also define custom operators. This post discusses the custom operator (GenieOperator) to submit tasks to Genie.
A task is a parameterized instance of an operator. After an operator is instantiated, it’s referred to as a task. A task instance represents a specific run of a task. A task instance has an associated DAG, task, and point in time.
You can run DAGs and tasks on demand or schedule them to run at a specific time defined as a cron expression in the DAG.
For additional details on Apache Airflow, see Concepts in the Apache Airflow documentation.
Genie
Genie is an open source tool that provides configuration-management capabilities and dynamic routing of jobs by abstracting access to the underlining Amazon EMR clusters.
Genie provides a REST API to submit jobs from big data applications such as Apache Hadoop MapReduce or Apache Spark. Genie manages the metadata of the underlining clusters and the commands and applications that run in the clusters.
Genie abstracts access to the processing clusters by associating one or more tags with the clusters. You can also associate tags with the metadata details for the applications and commands that the big data platform supports. As Genie receives job submissions for specific tags, it uses a combination of the cluster/command tag to route each job to the correct EMR cluster dynamically.
Genie’s data model
Genie provides a data model to capture the metadata associated with resources in your big data environment.
An application resource is a reusable set of binaries, configuration files, and setup files to install and configure applications supported by the big data platform on the Genie node that submits the jobs to the clusters. When Genie receives a job, the Genie node downloads all dependencies, configuration files, and setup files associated with the applications and stores it in a job working directory. Applications are linked to commands because they represent the binaries and configurations needed before a command runs.
Command resources represent the parameters when using the command line to submit work to a cluster and which applications need to be available on the PATH to run the command. Command resources glue metadata components together. For example, a command resource representing a Hive command would include a hive-site.xml and be associated with a set of application resources that provide the Hive and Hadoop binaries needed to run the command. Moreover, a command resource is linked to the clusters it can run on.
A cluster resource identifies the details of an execution cluster, including connection details, cluster status, tags, and additional properties. A cluster resource can register with Genie during startup and deregister during termination automatically. Clusters are linked to one or more commands that can run in it. After a command is linked to a cluster, Genie can start submitting jobs to the cluster.
Lastly, there are three job resource types: job request, job, and job execution. A job request resource represents the request submission with details to run a job. Based on the parameters submitted in the request, a job resource is created. The job resource captures details such as the command, cluster, and applications associated with the job. Additionally, information on status, start time, and end time is also available on the job resource. A job execution resource provides administrative details so you can understand where the job ran.
For more information, see Data Model on the Genie Reference Guide.
Amazon EMR and Amazon S3
Amazon EMR is a managed cluster platform that simplifies running big data frameworks, such as Apache Hadoop and Apache Spark, on AWS to process and analyze vast amounts of data. For more information, see Overview of Amazon EMR Architecture and Overview of Amazon EMR.
Data is stored in Amazon S3, an object storage service with scalable performance, ease-of-use features, and native encryption and access control capabilities. For more details on S3, see Amazon S3 as the Data Lake Storage Platform.
Architecture deep dive
Two main actors interact with this architecture: platform admin engineers and data engineers.
Platform admin engineers have administrator access to all components. They can add or remove clusters, and configure the applications and the commands that the platform supports.
Data engineers focus on writing big data applications with their preferred frameworks (Apache Spark, Apache Hadoop MR, Apache Sqoop, Apache Hive, Apache Pig, and Presto) and authoring python scripts to represent DAGs.
At high level, the team of platform admin engineers prepares the supported big data applications and its dependencies and registers them with Genie. The team of platform admin engineers launches Amazon EMR clusters that register with Genie during startup.
The team of platform admin engineers associates each Genie metadata resource (applications, commands, and clusters) with Genie tags. For example, you can associate a cluster resource with a tag named environment and the value can be “Production Environment”, “Test Environment”, or “Development Environment”.
Data engineers author workflows as Airflow DAGs and use a custom Airflow Operator—GenieOperator—to submit tasks to Genie. They can use a combination of tags to identify the type of tasks they are running plus where the tasks should run. For example, you might need to run Apache Spark 2.4.3 tasks in the environment identified by the “Production Environment” tag. To do this, set the cluster and command tags in the Airflow GenieOperator as the following code:
(cluster_tags=['emr.cluster.environment:production'],command_tags=['type:spark-submit','version:2.4.3'])
The following diagram illustrates this architecture.
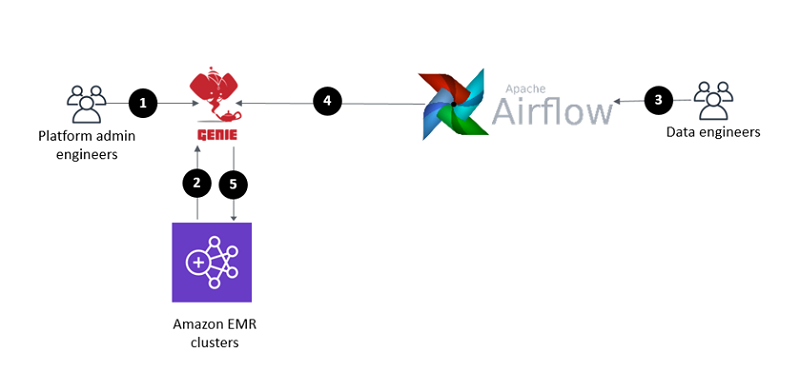
The workflow, as it corresponds to the numbers in this diagram are as follows:
- A platform admin engineer prepares the binaries and dependencies of the supported applications (Spark-2.4.5, Spark-2.1.0, Hive-2.3.5, etc.). The platform admin engineer also prepares commands (spark-submit, hive). The platform admin engineer registers applications and commands with Genie. Moreover, the platform admin engineer associates commands with applications and links commands to a set of clusters after step 2 (below) is concluded.
- Amazon EMR cluster(s) register with Genie during startup.
- A data engineer authors Airflow DAGs and uses the Genie tag to reference the environment, application, command or any combination of the above. In the workflow code, the data engineer uses the GenieOperator. The GenieOperator submits jobs to Genie.
- A schedule triggers workflow execution or a data engineer manually triggers the workflow execution. The jobs that compose the workflow are submitted to Genie for execution with a set of Genie tags that specify where the job should be run.
- The Genie node, working as the client gateway, will set up a working directory with all binaries and dependencies. Genie dynamically routes the jobs to the cluster(s) associated with the provided Genie tags. The Amazon EMR clusters run the jobs.
For details on the authorization and authentication mechanisms supported by Apache Airflow and Genie see Security in the Apache Airflow documentation and Security in the Genie documentation. This architecture pattern does not expose SSH access to the Amazon EMR clusters. For details on providing different levels of access to data in Amazon S3 through EMR File System (EMRFS), see Configure IAM Roles for EMRFS Requests to Amazon S3.
Use cases enabled by this architecture
The following use cases demonstrate the capabilities this architecture provides.
Managing upgrades and deployments with no downtime and adopting the latest open source release
In a large organization, teams that use the data platform use heterogeneous frameworks and different versions. You can use this architecture to support upgrades with no downtime and offer the latest version of open source frameworks in a short amount of time.
Genie and Amazon EMR are the key components to enable this use case. As the Amazon EMR service team strives to add the latest version of the open source frameworks running on Amazon EMR in a short release cycle, you can keep up with your internal teams’ needs of the latest features of their preferred open source framework.
When a new version of the open source framework is available, you need to test it, add the new supported version and its dependencies to Genie, and move tags in the old cluster to the new one. The new cluster takes new job submissions, and the old cluster concludes jobs it is still running.
Moreover, because Genie centralizes the location of application binaries and its dependencies, upgrading binaries and dependencies in Genie also upgrades any upstream client automatically. Using Genie removes the need for upgrading all upstream clients.
Managing a centralized configuration, job and cluster status, and logging
In a universe of thousands of jobs and multiple clusters, you need to identify where a specific job is running and access logging details quickly. This architecture gives you visibility into jobs running on the data platform, logging of jobs, clusters, and their configurations.
Having programmatic access to the big data platform
This architecture enables a single point of job submissions by using Genie’s REST API. Access to the underlying cluster is abstracted through a set of APIs that enable administration tasks plus submitting jobs to the clusters. A REST API call submits jobs into Genie asynchronously. If accepted, a job-id is returned that you can use to get job status and outputs programmatically via API or web UI. A Genie node sets up the working directory and runs the job on a separate process.
You can also integrate this architecture with continuous integration and continuous delivery (CI/CD) pipelines for big data application and Apache Airflow DAGs.
Enabling scalable client gateways and concurrent job submissions
The Genie node acts as a client gateway (edge node) and can scale horizontally to make sure the client gateway resources used to submit jobs to the data platform meet demand. Moreover, Genie allows the submission of concurrent jobs.
When to use this architecture
This architecture is recommended for organizations that use multiple large, multi-tenant processing clusters instead of transient clusters. It is out of the scope of this post to address when organizations should consider always-on clusters versus transient clusters (you can use an EMR Airflow Operator to spin up Amazon EMR clusters that register with Genie, run a job, and tear them down). You should use Reserved Instances with this architecture. For more information, see Using Reserved Instances.
This architecture is especially recommended for organizations that choose to have a central platform team to administer and maintain a big data platform that supports many internal teams that require thousands of jobs to run concurrently.
This architecture might not make sense for organizations that are not at as large or don’t expect to grow to that scale. The benefits of cluster abstraction and centralized configuration management are ideal in bringing structured access to a potentially chaotic environment of thousands of concurrent workflows and hundreds of teams.
This architecture is also recommended for organizations that support a high percentage of multi-hour or overlapping workflows and heterogeneous frameworks (Apache Spark, Apache Hive, Apache Pig, Apache Hadoop MapReduce, Apache Sqoop, or Presto).
If your organization relies solely on Apache Spark and is aligned with the recommendations discussed previously, this architecture might still apply. For organizations that don’t have the scale to justify the need for centralized REST API for job submission, cluster abstraction, dynamic job routing, or centralized configuration management, Apache Livy plus Amazon EMR might be the appropriate option. Genie has its own scalable infrastructure that acts as the edge client. This means that Genie does not compete with Amazon EMR master instance resources, whereas Apache Livy does.
If the majority of your organization’s workflows are a few short-lived jobs, opting for a serverless processing layer, serverless ad hoc querying layer, or using dedicated transient Amazon EMR clusters per workflow might be more appropriate. If the majority of your organization’s workflows are composed of thousands of short-lived jobs, the architecture still applies because it removes the need to spin up and down clusters.
This architecture is recommended for organizations that require full control of the processing platform to optimize component performance. Moreover, this architecture is recommended for organizations that need to enforce centralized governance on their workflows via CI/CD pipelines.
It is out of the scope of this post to evaluate different orchestration options or the benefits of adopting Airflow as the orchestration layer. When considering adopting an architecture, also consider the existing skillset and time to adopt tooling. The open source nature of Genie may allow you to integrate other orchestration tools. Evaluating that route might be an option if you wish to adopt this architecture with another orchestration tool.
Conclusion
This post presented how to use Apache Airflow, Genie, and Amazon EMR to manage big data workflows. The post described the architecture components, the use cases the architecture supports, and when to use it. The second part of this post deploys a demo environment and walks you through the steps to configure Genie and use the GenieOperator for Apache Airflow.
About the Authors
 Jelez Raditchkov leads the NoSQL AWS Professional Services Practice at AWS. He helps customers realize desired business outcomes by delivering focused guidance in the NoSQL, Graph and Search areas. Previously, he was a Principal Data Lake Architect with AWS Professional Services.
Jelez Raditchkov leads the NoSQL AWS Professional Services Practice at AWS. He helps customers realize desired business outcomes by delivering focused guidance in the NoSQL, Graph and Search areas. Previously, he was a Principal Data Lake Architect with AWS Professional Services.
Audit History
Last reviewed in December 2023 by Ragav Anumasa | Sr. Data Architect