AWS Big Data Blog
Persist and analyze metadata in a transient Amazon MWAA environment
Customers can harness sophisticated orchestration capabilities through the open-source tool Apache Airflow. Airflow can be installed on Amazon EC2 instances or can be dockerized and deployed as a container on AWS container services. Alternatively, customers can also opt to leverage Amazon Managed Workflows for Apache Airflow (MWAA).
Amazon MWAA is a fully managed service that enables customers to focus more of their efforts on high-impact activities such as programmatically authoring data pipelines and workflows, as opposed to maintaining or scaling the underlying infrastructure. Amazon MWAA offers auto-scaling capabilities where it can respond to surges in demand by scaling the number of Airflow workers out and back in.
With Amazon MWAA, there are no upfront commitments and you only pay for what you use based on instance uptime, additional auto-scaling capacity, and storage of the Airflow back-end metadata database. This database is provisioned and managed by Amazon MWAA and contains the necessary metadata to support the Airflow application. It hosts key data points such as historical execution times for tasks and workflows and is valuable in understanding trends and behaviour of your data pipelines over time. Although the Airflow console does provide a series of visualisations that help you analyse these datasets, these are siloed from other Amazon MWAA environments you might have running, as well as the rest of your business data.
Data platforms encompass multiple environments. Typically, non-production environments are not subject to the same orchestration demands and schedule as those of production environments. In most instances, these non-production environments are idle outside of business hours and can be spun down to realise further cost-efficiencies. Unfortunately, terminating Amazon MWAA instances results in the purging of that critical metadata.
In this post, we discuss how to export, persist and analyse Airflow metadata in Amazon S3 enabling you to run and perform pipeline monitoring and analysis. In doing so, you can spin down Airflow instances without losing operational metadata.
Benefits of Airflow metadata
Persisting the metadata in the data lake enables customers to perform pipeline monitoring and analysis in a more meaningful manner:
- Airflow operational logs can be joined and analysed across environments
- Trend analysis can be conducted to explore how data pipelines are performing over time, what specific stages are taking the most time, and how is performance effected as data scales
- Airflow operational data can be joined with business data for improved record level lineage and audit capabilities
These insights can help customers understand the performance of their pipelines over time and guide focus towards which processes need to be optimised.
The technique described below to extract metadata is applicable to any Airflow deployment type, but we will focus on Amazon MWAA in this blog.
Solution Overview
The below diagram illustrates the solution architecture. Please note, Amazon QuickSight is NOT included as part of the CloudFormation stack and is not covered in this tutorial. It has been placed in the diagram to illustrate that metadata can be visualised using a business intelligence tool.
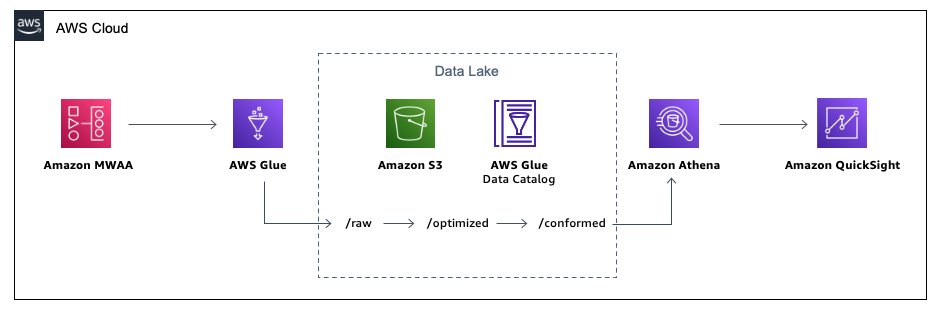
As part of this tutorial, you will be performing the below high-level tasks:
- Run CloudFormation stack to create all necessary resources
- Trigger Airflow DAGs to perform sample ETL workload and generate operational metadata in back-end database
- Trigger Airflow DAG to export operational metadata into Amazon S3
- Perform analysis with Amazon Athena
This post comes with an AWS CloudFormation stack that automatically provisions the necessary AWS resources and infrastructure, including an active Amazon MWAA instance, for this solution. The entire code is available in the GitHub repository.
The Amazon MWAA instance will already have three directed-acyclic graphs (DAGs) imported:
- glue-etl – This ETL workflow leverages AWS Glue to perform transformation logic on a CSV file (customer_activity.csv). This file will be loaded as part of the CloudFormation template into the
s3://<DataBucket>/raw/prefix.
The first task glue_csv_to_parquet converts the ‘raw’ data to parquet format and stores the data in location s3://<DataBucket>/optimised/. By converting the data in parquet format, you can achieve faster query performance and lower query costs.
The second task glue_transform runs an aggregation over the newly created parquet format and stores the aggregated data in location s3://<DataBucket>/conformed/.
- db_export_dag – This DAG consists of one task, export_db, which exports the data from the back-end Airflow database into Amazon S3 in the location
s3://<DataBucket>/export/.
Please note that you may experience time-out issues when extracting large amounts of data. On busy Airflow instances, our recommendation will be to set up frequent extracts in small chunks.
- run-simple-dag – This DAG does not perform any data transformation or manipulation. It is used in this blog for the purposes of populating the back-end Airflow database with sufficient operational data.
Prerequisites
To implement the solution outlined in this blog, you will need following :
- An AWS Account.
- Basic understanding of Apache Airflow , Amazon Athena, Amazon Simple Storage Service (Amazon S3) , AWS Glue, Amazon Managed Workflows for Apache Airflow (MWAA) and AWS Cloud Formation.
Steps to run a data pipeline using Amazon MWAA and saving metadata to s3:
- Choose Launch Stack:

- Choose Next.

- For Stack name, enter a name for your stack.

- Choose Next.
- Keep the default settings on the ‘Configure stack options’ page, and choose Next.
- Acknowledge that the template may create AWS Identity and Access Management (IAM) resources.
- Choose Create stack. The stack can take up to 30 mins to complete.
The CloudFormation template generates the following resources:
-
- VPC infrastructure that uses Public routing over the Internet.
- Amazon S3 buckets required to support Amazon MWAA, detailed below:
- The Data Bucket, refered in this blog as
s3://<DataBucket>, holds the data which will be optimised and transformed for further analytical consumption. This bucket will also hold the data from the Airflow back-end metadata database once extracted. - The Environment Bucket, refered in this blog as
s3://<EnvironmentBucket>, stores your DAGs, as well as any custom plugins, and Python dependencies you may have.
- The Data Bucket, refered in this blog as
- Amazon MWAA environment that’s associated to the
s3://<EnvironmentBucket>/dagslocation. - AWS Glue jobs for data processing and help generate airflow metadata.
- AWS Lambda-backed custom resources to upload to Amazon S3 the sample data, AWS Glue scripts and DAG configuration files,
- AWS Identity and Access Management (IAM) users, roles, and policies.
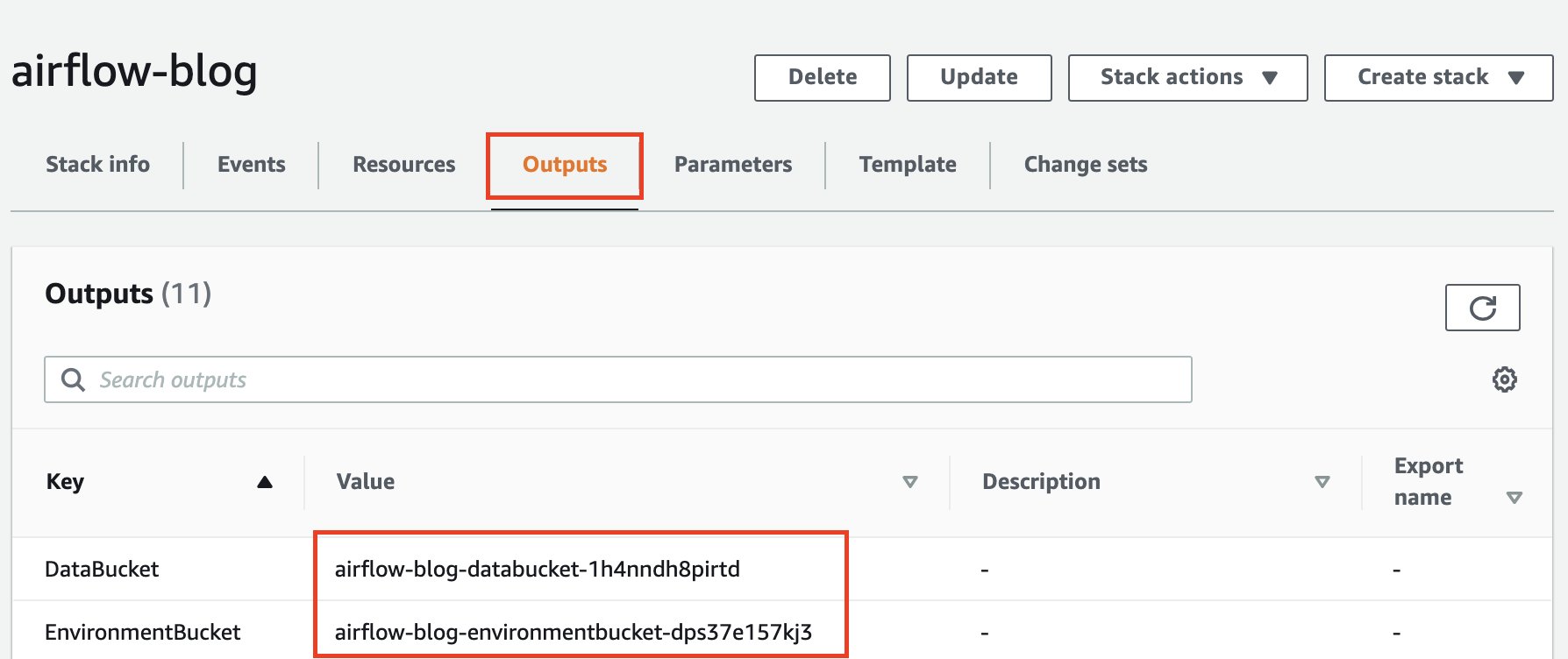
- Once the stack creation is successful, navigate to the Outputs tab of the CloudFormation stack and make note of
DataBucketandEnvironmentBucketname. Store your Apache Airflow Directed Acyclic Graphs (DAGs), custom plugins in aplugins.zipfile, and Python dependencies in arequirements.txtfile.
- Open the Environments page on the Amazon MWAA console.
- Choose the environment created above. (The environment name will include the stack name). Click on Open Airflow UI.

- Choose glue-etl DAG , unpause by clicking the radio button next to the name of the DAG and click on the Play Button on Right hand side to Trigger DAG. It may take up to a minute for DAG to appear.

- Leave Configuration JSON as empty and hit Trigger.

- Choose run-simple-dag DAG, unpause and click on Trigger DAG.
- Once both DAG executions have completed, select the db_export_dag DAG, unpause and click on Trigger DAG. Leave Configuration JSON as empty and hit Trigger.

This step will extract the dag and task metadata to a S3 location. This is a sample list of tables and more tables can be added as required. The exported metadata will be located in s3://<DataBucket>/export/ folder.

Visualise using Amazon QuickSight and Amazon Athena
Amazon Athena is a serverless interactive query service that can be used to run exploratory analysis on data stored in Amazon S3.
If you are using Amazon Athena for the first time, please find the steps here to setup query location. We can use Amazon Athena to explore and analyse the metadata generated from airflow dag runs.
- Navigate to Athena Console and click explore the query editor.
- Hit View Settings.

- Click Manage.

- Replace with
s3://<DataBucket>/logs/athena/. Once completed, return to the query editor. - Before we can perform our pipeline analysis, we need to create the below DDLs. Replace the
<DataBucket>as part of theLOCATIONclause with the parameter value as defined in the CloudFormation stack (noted in Step 8 above). - You can preview the table in the query editor of Amazon Athena.

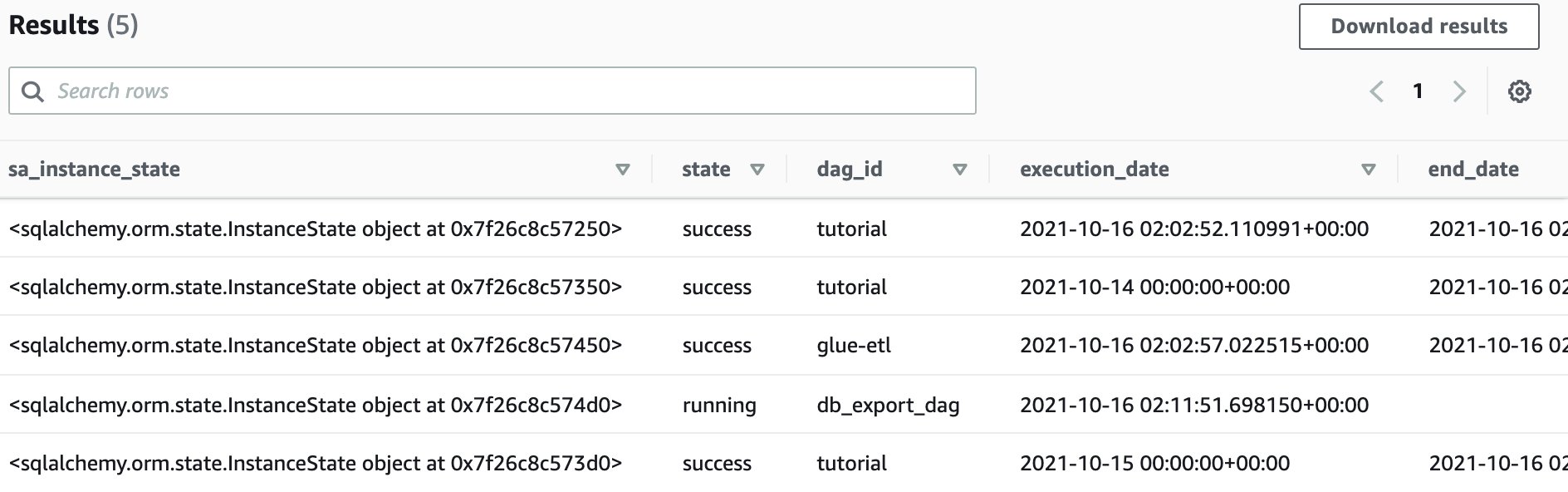
- With the metadata persisted, you can perform pipeline monitoring and derive some powerful insights on the performance of your data pipelines overtime. As an example to illustrate this, execute the below SQL query in Athena.
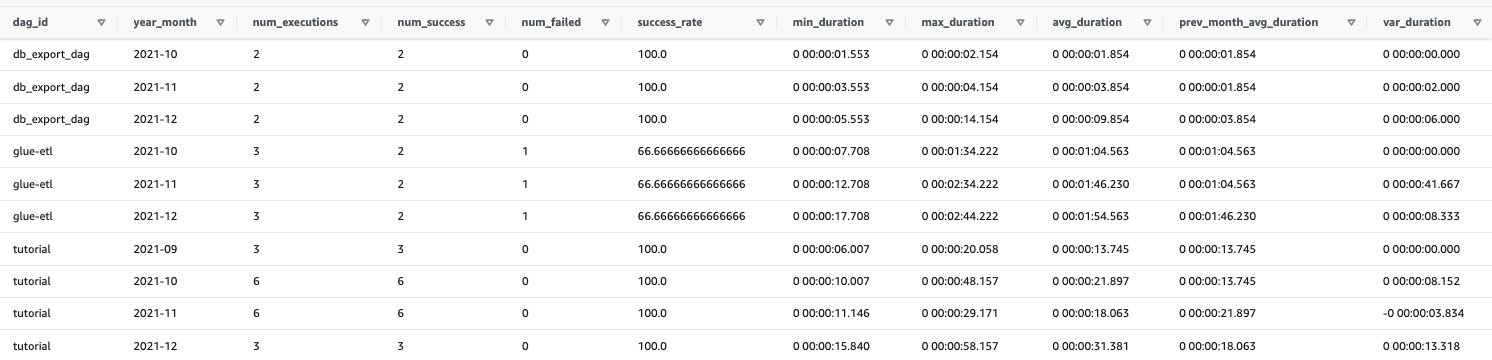
This query returns pertinent metrics at a monthly grain which include number of executions of the DAG in that month, success rate, minimum/maximum/average duration for the month and a variation compared to the previous months average.
Through the below SQL query, you will be able to understand how your data pipelines are performing over time.
- You can also visualize this data using your BI tool of choice. While step by step details of creating a dashboard is not covered in this blog, please refer the below dashboard built on Amazon QuickSight as an example of what can be built based on the metadata extracted above. If you are using Amazon QuickSight for the first time, please find the steps here on how to get started.

Through QuickSight, we can quickly visualise and derive that our data pipelines are completing successfully, but on average are taking a longer time to complete over time.
Clean up the environment
- Navigate to the S3 console and click on the
<DataBucket>noted in step 8 above. - Click on Empty bucket.

- Confirm the selection.
- Repeat this step for bucket
<EnvironmentBucket>(noted in step 8 above) and Empty bucket. - Run the below statements in the query editor to drop the two Amazon Athena tables. Run statements individually.
- On the AWS CloudFormation console, select the stack you created and choose Delete.
Summary
In this post, we presented a solution to further optimise the costs of Amazon MWAA by tearing down instances whilst preserving the metadata. Storing this metadata in your data lake enables you to better perform pipeline monitoring and analysis. This process can be scheduled and orchestrated programatically and is applicable to all Airflow deployments, such as Amazon MWAA, Apache Airflow installed on Amazon EC2, and even on-premises installations of Apache Airflow.
To learn more, please visit Amazon MWAA and Getting Started with Amazon MWAA.
About the Authors
 Praveen Kumar is a Specialist Solution Architect at AWS with expertise in designing, building, and implementing modern data and analytics platforms using cloud-native services. His areas of interests are serverless technology, streaming applications, and modern cloud data warehouses.
Praveen Kumar is a Specialist Solution Architect at AWS with expertise in designing, building, and implementing modern data and analytics platforms using cloud-native services. His areas of interests are serverless technology, streaming applications, and modern cloud data warehouses.
 Avnish Jain is a Specialist Solution Architect in Analytics at AWS with experience designing and implementing scalable, modern data platforms on the cloud for large scale enterprises. He is passionate about helping customers build performant and robust data-driven solutions and realise their data & analytics potential.
Avnish Jain is a Specialist Solution Architect in Analytics at AWS with experience designing and implementing scalable, modern data platforms on the cloud for large scale enterprises. He is passionate about helping customers build performant and robust data-driven solutions and realise their data & analytics potential.