AWS Big Data Blog
Use MSK Connect for managed MirrorMaker 2 deployment with IAM authentication
January 2026: This post was reviewed and updated for accuracy. MSK Connect configurations required for cross-account and same-account replication have been added to show different use cases.
March 2025: This post was reviewed and updated for accuracy. MSK Replicator now makes it easier to set up cross-Region and same-Region replication without running MirrorMaker 2. Read AWS News Blog to learn more.
In this post, we show how to use MSK Connect for MirrorMaker 2 deployment with AWS Identity and Access Management (IAM) authentication. We create an MSK Connect custom plugin and IAM role, and then replicate the data between two existing Amazon Managed Streaming for Apache Kafka (Amazon MSK) clusters. The goal is to have replication successfully running between two MSK clusters that are using IAM as an authentication mechanism. It’s important to note that although we’re using IAM authentication in this solution, this can be accomplished using no authentication for the MSK authentication mechanism.
Solution overview
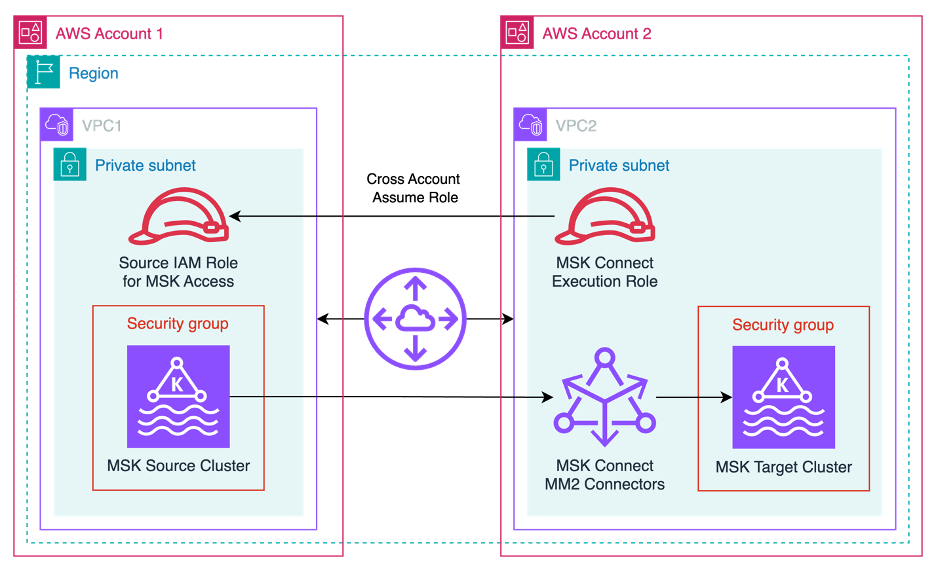
This solution can help Amazon MSK users run MirrorMaker 2 on MSK Connect, which eases the administrative and operational burden because the service handles the underlying resources, enabling you to focus on the connectors and data to ensure correctness. The following diagram illustrates the solution architecture.

Apache Kafka is an open-source platform for streaming data. You can use it to build building various workloads like IoT connectivity, data analytic pipelines, or event-based architectures.
Kafka Connect is a component of Apache Kafka that provides a framework to stream data between systems like databases, object stores, and even other Kafka clusters, into and out of Kafka. Connectors are the executable applications that you can deploy on top of the Kafka Connect framework to stream data into or out of Kafka.
MirrorMaker is the cross-cluster data mirroring mechanism that Apache Kafka provides to replicate data between two clusters. You can deploy this mirroring process as a connector in the Kafka Connect framework to improve the scalability, monitoring, and availability of the mirroring application. Replication between two clusters is a common scenario when needing to improve data availability, migrate to a new cluster, aggregate data from edge clusters into a central cluster, copy data between Regions, and more. In KIP-382, MirrorMaker 2 (MM2) is documented with all the available configurations, design patterns, and deployment options available to users. It’s worthwhile to familiarize yourself with the configurations because there are many options that can impact your unique needs.
MSK Connect is a managed Kafka Connect service that allows you to deploy Kafka connectors into your environment with seamless integrations with AWS services like IAM, Amazon MSK, and Amazon CloudWatch.
In the following sections, we walk you through the steps to configure this solution:
- Setup network connectivity
- Create an IAM policy and role.
- Create a custom plugin.
- Create connectors.
Setup network connectivity
MM2 consumes data from source Kafka cluster and sends data to the target Kafka cluster. The source and target clusters could be in different regions or accounts. For geographically distributes clusters, it is better to consume from remote cluster and produce to local cluster. Hence it is recommended practice to create MM2 connectors in the VPC of the target cluster and ensure connectivity between the connectors and source cluster. Refer to multiple connectivity option at Access from within AWS but outside cluster’s VPC.
For the solution in this blog, the clusters are in same region and different VPC. Choose subnets and security group of MM2 connectors to be same that of target cluster. Ensure that the ingress rule of security group allows connectivity from self (same security group) on port 9098.

The source cluster security group should allow ingress from MM2 connectors on port 9098.
Create an IAM policy and role for authentication
IAM helps users securely control access to AWS resources. In this step, we create the MSK Connect execution role and IAM policy such that:
- MSK Connect can assume the created role (see the following trust policy example)
- MSK Connect is authorized to create topics, publishing events, and so on
A common mistake made when creating an IAM role and policy needed for common Kafka tasks (publishing to a topic, listing topics) is to assume that the AWS managed policy AmazonMSKFullAccess (arn:aws:iam::aws:policy/AmazonMSKFullAccess) will suffice for permissions. This policy supports the creation of the cluster within the AWS account infrastructure and grants access to the components that make up the cluster anatomy like Amazon Elastic Compute Cloud (Amazon EC2), Amazon Virtual Private Cloud (Amazon VPC), logs, and kafka:*. There is no managed policy for a Kafka administrator to have full access on the cluster itself.
The following is an example of a policy (referred as KafkaAdminFullAccess from here) with both full Kafka and Amazon MSK access:
After you create the KafkaAdminFullAccess policy, create a role and attach the policy to it. Additionally attach arn:aws:iam::aws:policy/CloudWatchLogsFullAccess policy to enable CloudWatch logging.
You need one statement in the role’s Trust relationships tab to allow Kafka Connect to assume this role.
For cross-account authentication with MSK Connect, an additional role is required in the source AWS account which includes a trust policy to allow the MSK Connect execution role to assume the cross account role. For MSK clusters in the same account, only the MSK Connect execution IAM role is required, with access permissions to both source and target MSK cluster.
Now we’re ready to deploy MirrorMaker 2.
Create a custom plugin
MSK Connect custom plugins accept a file or folder with a .jar or .zip ending. For this step, create a dummy folder or file and compress it. Then upload the .zip object to your Amazon Simple Storage Service (Amazon S3) bucket:
mkdir mm2
zip mm2.zip mm2
aws s3 cp mm2.zip s3://mytestbucket/Because Kafka and subsequently Kafka Connect have MirrorMaker libraries built in, you don’t need to add additional JAR files for this functionality. MSK Connect has a prerequisite that a custom plugin needs to be present at connector creation, so we have to create an empty one just for reference. It doesn’t matter what the contents of the file are or what the folder contains, as long as there is an object in Amazon S3 that is accessible to MSK Connect, so MSK Connect has access to MM2 classes.
On the Amazon MSK console, follow the steps to create a custom plugin from the .zip file created above. Enter the object’s Amazon S3 URI and for this post, and name the plugin Mirror-Maker-2.

Create connectors
You need to create three connectors for a successful mirroring:
MirrorSourceConnector– To mirror topics data, configurations and ACLs.MirrorHeartbeatConnector– To monitor connectivity and latency between clusters.MirrorCheckpointConnector– To mirror and translate consumer group offsets.
Complete the following steps for each connector:
- On the Amazon MSK console, choose Create connector.
- For Connector name, enter the name of your first connector.

- Select the target MSK cluster that the data is mirrored to as a destination.
- Choose IAM as the authentication mechanism.

- Pass the necessary config into the connector (see below for configurations for each connector)
Connector config files are JSON-formatted config maps for the Kafka Connect framework to use in passing configurations to the executable JAR. When using the MSK Connect console, we must convert the config file from a JSON config file to single-lined key=value file.
You need to change some values within the configs for deployment, namely bootstrap.server, sasl.jaas.config , tasks.max and replication.factor. Note the placeholders in the following code for all three configs.
The sasl.jaas.config configurations are required to configure the correct IAM authentication for your specific cluster setup. This configures the aws-msk-iam-auth Java library for authentication to MSK. In MSK Connect, this library uses the MSK Connect execution IAM role by default. The format for the entry is:
For cross-account use cases, the aws-msk-iam-auth library allows configuring awsRoleArn=”(Your source account’s IAM role ARN)” which instructs the library to use the MSK Connect execution role to assume the source account’s IAM role specified in the role ARN. This requires a cross-account trust policy to be established between the MSK Connect execution role and the source account’s IAM role. This configuration is only needed for the source cluster, if MSK Connect is running in the same account as the target cluster, and the MSK Connect execution role has access to the target cluster.
For all single-account use cases (such as, cluster-to-cluster replication in one account), no additional arguments are required as the execution role can be use to access both MSK clusters. Note that MSK Replicator can also be used for this use case, and is generally preferred to MirrorMaker2.
The following code is for MirrorHeartBeatConnector using a cross-account setup, assuming a role in the source account:
The following code is for MirrorCheckpointConnector using a cross-account setup, assuming a role in the source account:
The following code is for MirrorSourceConnector using a cross-account setup, assuming a role in the source account:
A general guideline for the number of tasks for a MirrorSourceConnector is one task per up to 10 partitions to be mirrored. For example, if a Kafka cluster has 15 topics with 12 partitions each for a total partition count of 180 partitions, we deploy at least 18 tasks for mirroring the workload. Exceeding the recommended number of tasks for the source connector may lead to offsets that aren’t translated (negative consumer group offsets). For more information about this issue and its workarounds, refer to MM2 may not sync partition offsets correctly.
- For the heartbeat and checkpoint connectors, use provisioned scale with one worker, because there is only one task running for each of them.
- For the source connector, we set the maximum number of workers to the value decided for the
tasks.maxproperty. Note that we use the defaults of the auto scaling threshold settings for now.
- Although it’s possible to pass custom worker configurations, let’s leave the default option selected.

- In the Access permissions section, we use the IAM role that we created earlier that has a trust relationship with
kafkaconnect.amazonaws.comandkafka-cluster:*permissions. Warning signs display above and below the drop-down menu. These are to remind you that IAM roles and attached policies is a common reason why connectors fail. If you never get any log output upon connector creation, that is a good indicator of an improperly configured IAM role or policy permission problem.

On the bottom of this page is a warning box telling us not to use the aptly named AWSServiceRoleForKafkaConnect role. This is an AWS managed service role that MSK Connect needs to perform critical, behind-the-scenes functions upon connector creation. For more information, refer to Using Service-Linked Roles for MSK Connect.
- Choose Next. Depending on the authorization mechanism chosen when aligning the connector with a specific cluster (we chose IAM), the options in the Security section are preset and unchangeable. If no authentication was chosen and your cluster allows plaintext communication, that option is available under Encryption – in transit.

- Choose your preferred logging destination for MSK Connect logs. For this post, I select Deliver to Amazon CloudWatch Logs and choose the log group ARN for my MSK Connect logs.

- Review your connector settings and choose Create connector.
A message appears indicating either a successful start to the creation process or immediate failure. You can now navigate to the Log groups page on the CloudWatch console and wait for the log stream to appear. The CloudWatch logs indicate when connectors are successful or have failed faster than on the Amazon MSK console. You can see a log stream in your chosen log group get created within a few minutes after you create your connector. If your log stream never appears, this is an indicator that there was a misconfiguration in your connector config or IAM role and it won’t work.

The configuration above will use DefaultReplicationPolicy and add “source.” prefix to the topic replicated from source cluster to target cluster. For example, a topic with name MirrorMakerTest will be replicated to source.MirrorMakerTest topic on the target cluster. Kafka Connect added IdentityReplicationPolicy in version 3.0.0 which ensures that topics on source cluster are replicated to the topics on target cluster with same name. MSK Connect uses Kafka Connect 2.7.1 which does not yet support IdentityReplicationPolicy.
Verify that the connector launched successfully
In this section, we walk through two confirmation steps to determine a successful launch.
Check the log stream
Open the log stream that your connector is writing to. In the log, you can check if the connector has successfully launched and is publishing data to the cluster. In the following screenshot, we can confirm data is being published. 
Mirror data
The second step is to create a producer to send data to the source cluster. We use the console producer and consumer that Kafka ships with. You can follow Step 1 from the Apache Kafka quickstart.
- On a client machine that can access Amazon MSK, download Kafka from https://kafka.apache.org/downloads and extract it:
tar -xzf kafka_2.13-3.1.0.tgz cd kafka_2.13-3.1.0
- Download the latest stable JAR for IAM authentication from the repository. As of this writing, it is 2.1.0:
cd libs/
wget https://repo1.maven.org/maven2/software/amazon/msk/aws-msk-iam-auth/2.1.0/aws-msk-iam-auth-2.1.0.jar- Next, we need to create our client.properties file that defines our connection properties for the clients. For instructions, refer to Configure clients for IAM access control. Copy the following example of the client.properties file:
security.protocol=SASL_SSL sasl.mechanism=AWS_MSK_IAM sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required; sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandle
You can place this properties file anywhere on your machine. For ease of use and simple referencing, I place mine inside kafka_2.13-3.1.0/bin.
After we create the client.properties file and place the JAR in the libs directory, we’re ready to create the topic for our replication test.
- Define shell variables for bootstrap broker string of the source and target clusters for IAM access. Go to source cluster details and View client information. Copy the connection string for IAM access. The string will have broker from each Availability Zone. For example: broker1:9098,broker2:9098,broker3:9098
export sourceClusterBSS=<Source cluster broker for IAM access>
export targetclusterBSS=<Target cluster broker for IAM access>
- From the bin folder, run the kafka-topics.sh script:
./kafka-topics.sh --bootstrap-server $sourceClusterBSS --create --topic MirrorMakerTest --replication-factor 2 --partitions 1 --command-config client.propertiesThe details of the command are as follows:
–bootstrap-server – Your bootstrap broker string of the source cluster for IAM access.
–topic – The topic name you want to create.
–create – The action for the script to perform.
–replication-factor – The replication factor for the topic.
–partitions – Total number of partitions to create for the topic.
–command-config – Additional configurations needed for successful running. Here is where we pass in the client.properties file we created in the previous step.
- We can list all the topics to see that it was successfully created:
./kafka-topics.sh --bootstrap-server $sourceClusterBSS --list --command-config client.properties
The preceding step calls list to show all topics available on the cluster. We can run this same command on our target cluster to see if MirrorMaker has replicated the topic.
./kafka-topics.sh --bootstrap-server $targetclusterBSS --list --command-config client.properties
When the topic is mirrored with the default replication policy, it will have a source. prefixed to it. You should see a topic source.MirrorMakerTest on the target cluster. With our topic created, let’s start the consumer. This consumer is consuming from the target cluster.
- For our topic, we consume from source.MirrorMakerTest as shown in the following code:
./kafka-console-consumer.sh --bootstrap-server $targetclusterBSS --topic source.MirrorMakerTest --consumer.config client.propertiesThe details of the code are as follows:
–bootstrap-server – Your target MSK bootstrap servers
–topic – The mirrored topic
–consumer.config – Where we pass in our client.properties file again to instruct the client how to authenticate to the MSK cluster
After this step is successful, it leaves a consumer running all the time on the console until we either close the client connection or close our terminal session. You won’t see any messages flowing yet because we haven’t started producing to the source topic on the source cluster.
- Open a new terminal window, leaving the consumer open, and start the producer:
./kafka-console-producer.sh --bootstrap-server $sourceClusterBSS --topic MirrorMakerTest --producer.config client.propertiesThe details of the code are as follows:
–bootstrap-server – The source MSK bootstrap servers
–topic – The topic we’re producing to
–producer.config – The client.properties file indicating which IAM authentication properties to use
After this is successful, the console returns >, which indicates that it’s ready to produce what we type. Let’s produce some messages, as shown in the following screenshot. After each message, press Enter to have the client produce to the topic.

Switching back to the consumer’s terminal window, you should see the same messages being replicated and now showing on your console’s output.

Clean up
We can close the client connections now by pressing Ctrl+C to close the connections or by simply closing the terminal windows.
Delete the three connectors from Amazon MSK console by selecting them from the list of connectors and choosing Delete.
Delete the source cluster topic first, then the target cluster topic. We can delete the topics on both clusters by running the following code:
./kafka-topics.sh --bootstrap-server $sourceClusterBSS --delete --topic MirrorMakerTest --command-config client.properties
./kafka-topics.sh --bootstrap-server $targetClusterBSS --delete --topic source.MirrorMakerTest --command-config client.properties
Conclusion
In this post, we showed how to use MSK Connect for MM2 deployment with IAM authentication. We successfully deployed the Amazon MSK custom plugin, and created the MM2 connector along with the accompanying IAM role. Then we deployed the MM2 connector onto our MSK Connect instances and watched as data was replicated successfully between two MSK clusters.
Using MSK Connect to deploy MM2 eases the administrative and operational burden of Kafka Connect and MM2, because the service handles the underlying resources, enabling you to focus on the connectors and data. The solution removes the need to have a dedicated infrastructure of a Kafka Connect cluster hosted on Amazon services like Amazon Elastic Compute Cloud (Amazon EC2), AWS Fargate, or Amazon EKS. The solution also automatically scales the resources for you (if configured to do so), which eliminates the need for the administers to check if the resources are scaling to meet demand. Additionally, using the Amazon managed service MSK Connect allows for easier compliance and security adherence for Kafka teams.
However, as outlined above, you need to complete several steps to setup MM2 on MSK Connect.
- You need to setup network connectivity using connectivity options mentioned at Access from within AWS but outside cluster’s VPC
- Create custom connector plugin
- Create 3 connectors with elaborate configurations.
- You need to estimate correct number of task.max or setup auto-scaling policy for source connector. Exceeding the recommended number of tasks for the source connector may lead to offsets that aren’t translated (negative consumer group offsets). For more information about this issue and its workarounds, refer to MM2 may not sync partition offsets correctly.
- You need to monitor the connectors to ensure that they are scaling to handle the workload on source cluster.
However, Amazon MSK Replicator provides an easier alternative that addresses these challenges. With MSK Replicator, you can reliably set up cross-Region and same-Region replication between MSK clusters. You can use MSK Replicator with both provisioned and serverless MSK cluster types. MSK Replicator provides automatic asynchronous replication across MSK clusters, eliminating the need to write custom plugin and configuration, manage infrastructure, or setup cross-region networking. MSK Replicator automatically scales the underlying resources so that you can replicate data on-demand without having to monitor or scale capacity. Amazon MSK Replicator is the preferred approach to run replication of data across MSK Clusters.
If you have any feedback or questions, please leave a comment.
About the Authors
 Tanner Pratt is a Practice Manager at Amazon Web Services. Tanner is leading a team of consultants focusing on Amazon streaming services like Managed Streaming for Apache Kafka, Kinesis Data Streams/Firehose and Kinesis Data Analytics.
Tanner Pratt is a Practice Manager at Amazon Web Services. Tanner is leading a team of consultants focusing on Amazon streaming services like Managed Streaming for Apache Kafka, Kinesis Data Streams/Firehose and Kinesis Data Analytics.
 Ed Berezitsky is a Senior Data Architect at Amazon Web Services.Ed helps customers design and implement solutions using streaming technologies, and specializes on Amazon MSK and Apache Kafka.
Ed Berezitsky is a Senior Data Architect at Amazon Web Services.Ed helps customers design and implement solutions using streaming technologies, and specializes on Amazon MSK and Apache Kafka.
 Akshaya Rawat is a Solutions Architect at AWS. He works from New Delhi, India, for large startup customers of India to architect and build resilient, scalable systems in the cloud. He has more than 20 years of experience in multiple engineering roles.
Akshaya Rawat is a Solutions Architect at AWS. He works from New Delhi, India, for large startup customers of India to architect and build resilient, scalable systems in the cloud. He has more than 20 years of experience in multiple engineering roles.