AWS Compute Blog
Optimizing batch processing with custom checkpoints in AWS Lambda
AWS Lambda can process batches of messages from sources like Amazon Kinesis Data Streams or Amazon DynamoDB Streams. In normal operation, the processing function moves from one batch to the next to consume messages from the stream.
However, when an error occurs in one of the items in the batch, this can result in reprocessing some of the same messages in that batch. With the new custom checkpoint feature, there is now much greater control over how you choose to process batches containing failed messages.
This blog post explains the default behavior of batch failures and options available to developers to handle this error state. I also cover how to use this new checkpoint capability and show the benefits of using this feature in your stream processing functions.
Overview
When using a Lambda function to consume messages from a stream, the batch size property controls the maximum number of messages passed in each event.
The stream manages two internal pointers: a checkpoint and a current iterator. The checkpoint is the last known item position that was successfully processed. The current iterator is the position in the stream for the next read operation. In a successful operation, here are two batches processed from a stream with a batch size of 10:

- The first batch delivered to the Lambda function contains items 1–10. The function processes these items without error.
- The checkpoint moves to item 11. The next batch delivered to the Lambda function contains items 11–20.
In default operation, the processing of the entire batch must succeed or fail. If a single item fails processing and the function returns an error, the batch fails. The entire batch is then retried until the maximum retries is reached. This can result in the same failure occurring multiple times and unnecessary processing of individual messages.
You can also enable the BisectBatchOnFunctonError property in the event source mapping. If there is a batch failure, the calling service splits the failed batch into two and retries the half-batches separately. The process continues recursively until there is a single item in a batch or messages are processed successfully. For example, in a batch of 10 messages, where item number 5 is failing, the processing occurs as follows:

- Batch 1 fails. It’s split into batches 2 and 3.
- Batch 2 fails, and batch 3 succeeds. Batch 2 is split into batches 4 and 5.
- Batch 4 fails and batch 5 succeeds. Batch 4 is split into batches 6 and 7.
- Batch 6 fails and batch 7 succeeds.
While this provides a way to process messages in a batch with one failing message, it results in multiple invocations of the function. In this example, message number 4 is processed four times before succeeding.
With the new custom checkpoint feature, you can return the sequence identifier for the failed messages. This provides more precise control over how to choose to continue processing the stream. For example, in a batch of 10 messages where the sixth message fails:
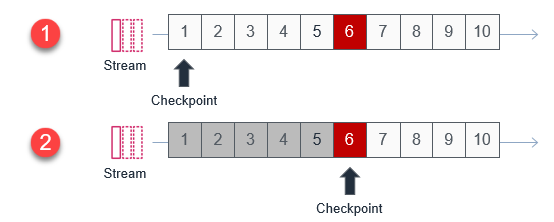
- Lambda processes the batch of messages, items 1–10. The sixth message fails and the function returns the failed sequence identifier.
- The checkpoint in the stream is moved to the position of the failed message. The batch is retried for only messages 6–10.
Existing stream processing behaviors
In the following examples, I use a DynamoDB table with a Lambda function that is invoked by the stream for the table. You can also use a Kinesis data stream if preferred, as the behavior is the same. The event source mapping is set to a batch size of 10 items so all the stream messages are passed in the event to a single Lambda invocation.

I use the following Node.js script to generate batches of 10 items in the table.
const AWS = require('aws-sdk')
AWS.config.update({ region: 'us-east-1' })
const docClient = new AWS.DynamoDB.DocumentClient()
const ddbTable = 'ddbTableName'
const BATCH_SIZE = 10
const createRecords = async () => {
// Create envelope
const params = {
RequestItems: {}
}
params.RequestItems[ddbTable] = []
// Add items to batch and write to DDB
for (let i = 0; i < BATCH_SIZE; i++) {
params.RequestItems[ddbTable].push({
PutRequest: {
Item: {
ID: Date.now() + i
}
}
})
}
await docClient.batchWrite(params).promise()
}
const main = async() => await createRecords()
main()
After running this script, there are 10 items in the DynamoDB table, which are then put into the DynamoDB stream for processing.

The processing Lambda function uses the following code. This contains a constant called FAILED_MESSAGE_NUM to force an error on the message with the corresponding index in the event batch:
exports.handler = async (event) => {
console.log(JSON.stringify(event, null, 2))
console.log('Records: ', event.Records.length)
const FAILED_MESSAGE_NUM = 6
let recordNum = 1
let batchItemFailures = []
event.Records.map((record) => {
const sequenceNumber = record.dynamodb.SequenceNumber
if ( recordNum === FAILED_MESSAGE_NUM ) {
console.log('Error! ', sequenceNumber)
throw new Error('kaboom')
}
console.log('Success: ', sequenceNumber)
recordNum++
})
}
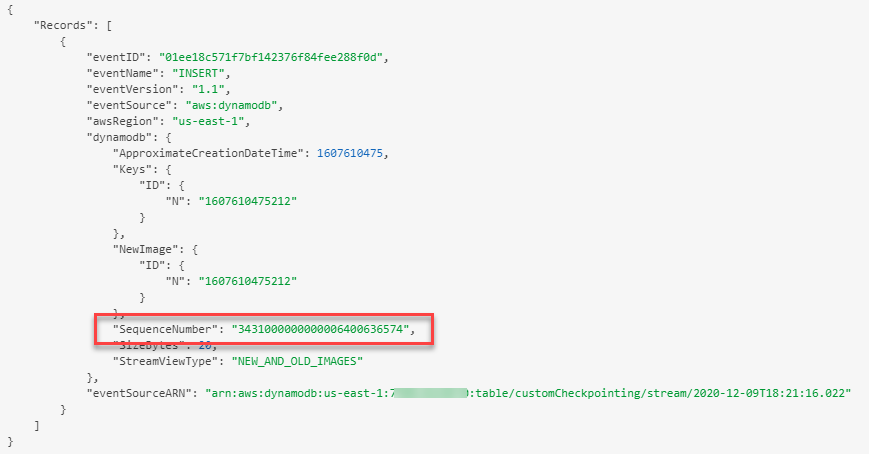
The code uses the DynamoDB item’s sequence number, which is provided in each record of the stream event:
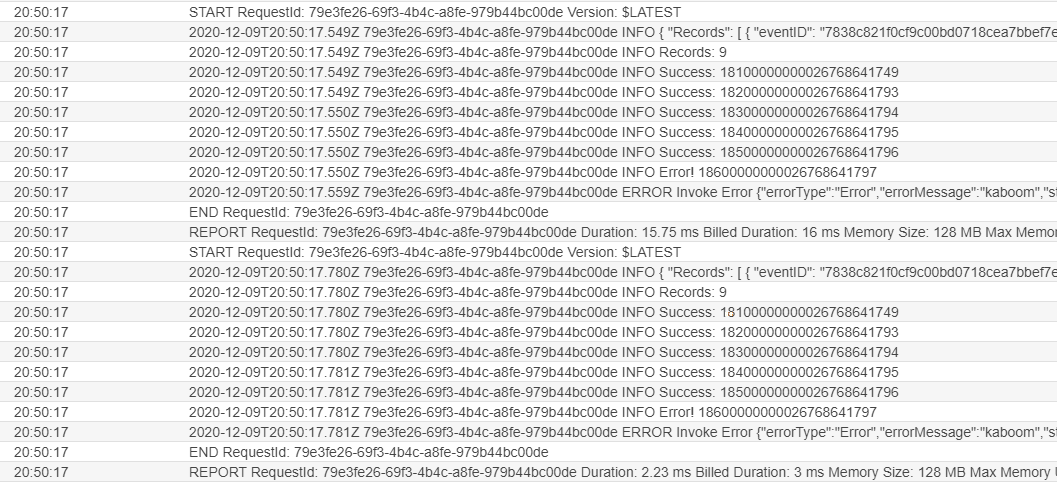
In the default configuration of the event source mapping, the failure of message 6 causes the whole batch to fail. The entire batch is then retried multiple times. This appears in the CloudWatch Logs for the function:
Next, I enable the bisect-on-error feature in the function’s event trigger. The first invocation fails as before but this causes two subsequent invocations with batches of five messages. The original batch is bisected. These batches complete processing successfully.

Configuring a custom checkpoint
Finally, I enable the custom checkpoint feature. This is configured in the Lambda function console by selecting the “Report batch item failures” check box in the DynamoDB trigger:

I update the processing Lambda function with the following code:
exports.handler = async (event) => {
console.log(JSON.stringify(event, null, 2))
console.log('Records: ', event.Records.length)
const FAILED_MESSAGE_NUM = 4
let recordNum = 1
let sequenceNumber = 0
try {
event.Records.map((record) => {
sequenceNumber = record.dynamodb.SequenceNumber
if ( recordNum === FAILED_MESSAGE_NUM ) {
throw new Error('kaboom')
}
console.log('Success: ', sequenceNumber)
recordNum++
})
} catch (err) {
// Return failed sequence number to the caller
console.log('Failure: ', sequenceNumber)
return { "batchItemFailures": [ {"itemIdentifier": sequenceNumber} ] }
}
}
In this version of the code, the processing of each message is wrapped in a try…catch block. When processing fails, the function stops processing any remaining messages. It returns the sequence number of the failed message in a JSON object:
{
"batchItemFailures": [
{
"itemIdentifier": sequenceNumber
}
]
}
The calling service then updates the checkpoint value with the sequence number provided. If the batchItemFailures array is empty, the caller assumes all messages have been processed correctly. If the batchItemFailures array contains multiple items, the lowest sequence number is used as the checkpoint.
In this example, I also modify the FAILED_MESSAGE_NUM constant to 4 in the Lambda function. This causes the fourth message in every batch to throw an error. After adding 10 items to the DynamoDB table, the CloudWatch log for the processing function shows:
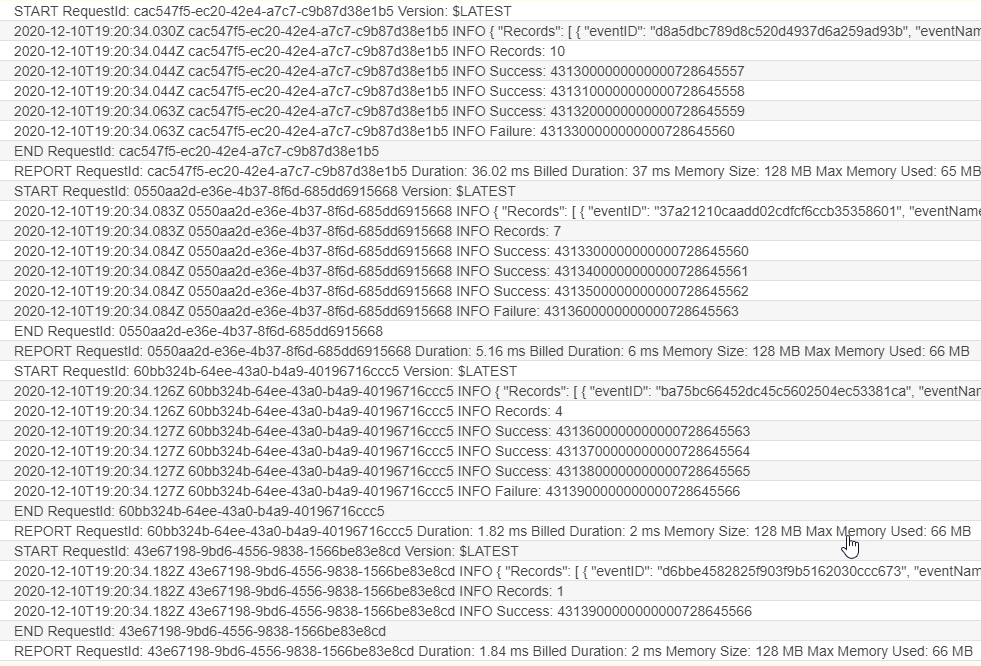
This is how the stream of 10 messages has been processed using the custom checkpoint:

- In the first invocation, all 10 messages are in the batch. The fourth message throws an error. The function returns this position as the checkpoint.
- In the second invocation, messages 4–10 are in the batch. Message 7 throws an error and its sequence number is returned as the checkpoint.
- In the third invocation, the batch contains messages 7–10. Message 10 throws an error and its sequence number is now the returned checkpoint.
- The final invocation contains only message 10, which is successfully processed.
Using this approach, subsequent invocations do not receive messages that have been successfully processed previously.
Conclusion
The default behavior for stream processing in Lambda functions enables entire batches of messages to succeed or fail. You can also use batch bisecting functionality to retry batches iteratively if a single message fails. Now with custom checkpoints, you have more control over handling failed messages.
This post explains the three different processing modes and shows example code for handling failed messages. Depending upon your use-case, you can choose the appropriate mode for your workload. This can help reduce unnecessary Lambda invocations and prevent reprocessing of the same messages in batches containing failures.
To learn more about how to use this feature, read the developer documentation for DynamoDB and Kinesis Streams. To learn more about building with serverless technology, visit Serverless Land.