AWS Compute Blog
Category: Kinesis Data Streams

Efficiently processing batched data using parallelization in AWS Lambda
This post is written by Anton Aleksandrov, Principal Solutions Architect, AWS Serverless Efficient message processing is crucial when handling large data volumes. By employing batching, distribution, and parallelization techniques, you can optimize the utilization of resources allocated to your AWS Lambda function. This post will demonstrate how to implement parallel data processing within the Lambda function handler, maximizing […]

Serverless ICYMI Q2 2024
Welcome to the 26th edition of the AWS Serverless ICYMI (in case you missed it) quarterly recap. Every quarter, we share all the most recent product launches, feature enhancements, blog posts, webinars, live streams, and other interesting things that you might have missed! In case you missed our last ICYMI, check out what happened last […]

Building well-architected serverless applications: Optimizing application costs
This series of blog posts uses the AWS Well-Architected Tool with the Serverless Lens to help customers build and operate applications using best practices. In each post, I address the serverless-specific questions identified by the Serverless Lens along with the recommended best practices. See the introduction post for a table of contents and explanation of the example application. COST 1. How […]

Building well-architected serverless applications: Optimizing application performance – part 2
This series of blog posts uses the AWS Well-Architected Tool with the Serverless Lens to help customers build and operate applications using best practices. In each post, I address the serverless-specific questions identified by the Serverless Lens along with the recommended best practices. See the introduction post for a table of contents and explanation of the example application. PERF 1. Optimizing […]

Building well-architected serverless applications: Building in resiliency – part 2
This series of blog posts uses the AWS Well-Architected Tool with the Serverless Lens to help customers build and operate applications using best practices. In each post, I address the serverless-specific questions identified by the Serverless Lens along with the recommended best practices. See the introduction post for a table of contents and explanation of the example application. Reliability question REL2: […]

Building well-architected serverless applications: Building in resiliency – part 1
This series of blog posts uses the AWS Well-Architected Tool with the Serverless Lens to help customers build and operate applications using best practices. In each post, I address the serverless-specific questions identified by the Serverless Lens along with the recommended best practices. See the introduction post for a table of contents and explanation of the example application. Reliability question REL2: […]

Building well-architected serverless applications: Regulating inbound request rates – part 2
This series of blog posts uses the AWS Well-Architected Tool with the Serverless Lens to help customers build and operate applications using best practices. In each post, I address the serverless-specific questions identified by the Serverless Lens along with the recommended best practices. See the introduction post for a table of contents and explanation of the example application. Reliability question REL1: […]
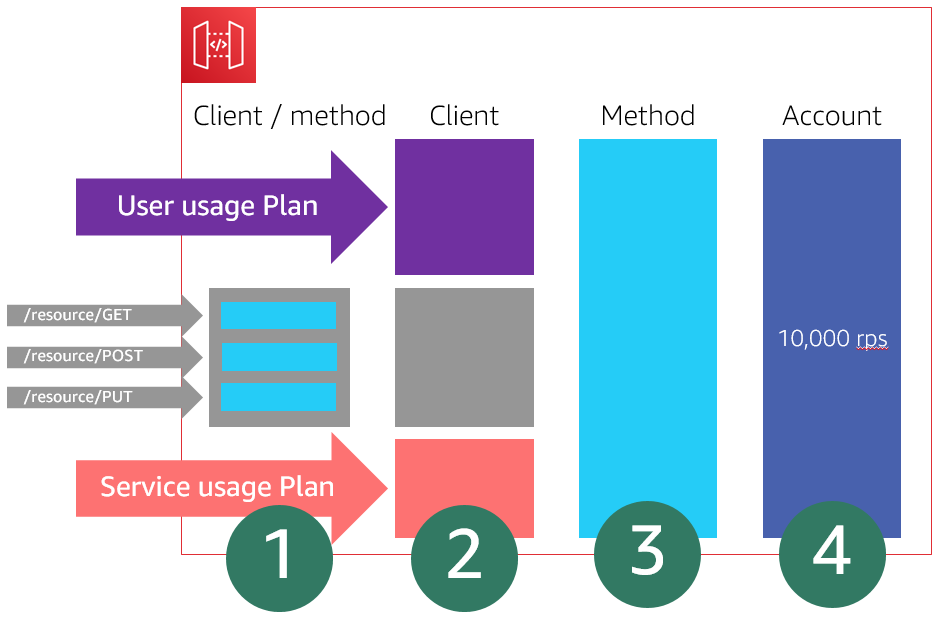
Building well-architected serverless applications: Regulating inbound request rates – part 1
This series of blog posts uses the AWS Well-Architected Tool with the Serverless Lens to help customers build and operate applications using best practices. In each post, I address the serverless-specific questions identified by the Serverless Lens along with the recommended best practices. See the introduction post for a table of contents and explanation of the example application. Reliability question REL1: […]
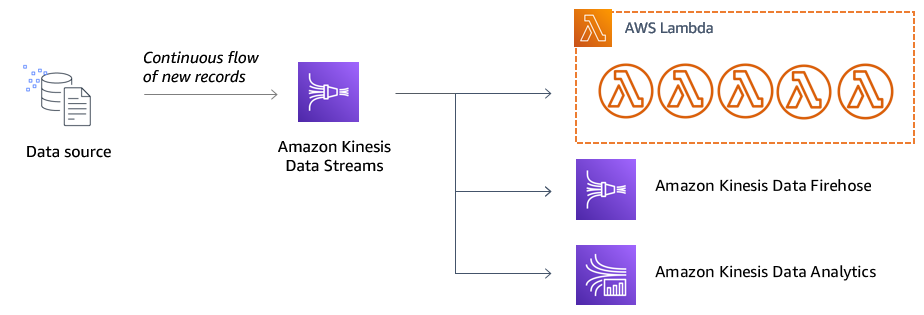
Understanding data streaming concepts for serverless applications
In this post, I introduce some of the core streaming concepts for serverless applications. I explain some of the benefits of streaming architectures and how Kinesis works with producers and consumers. I compare different ways to ingest data, how streams are composed of shards, and how partition keys determine which shard is used. Finally, I explain the payload formats at the different stages of a streaming workload, how message ordering works with shards, and why idempotency is important to handle.

Monitoring and troubleshooting serverless data analytics applications
In this post, I show how the existing settings in the Alleycat application are not sufficient for handling the expected amount of traffic. I walk through the metrics visualizations for Kinesis Data Streams, Lambda, and DynamoDB to find which quotas should be increased.