AWS Compute Blog
Building leaderboard functionality with serverless data analytics
February 12, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more.
This series is about building serverless solutions in streaming data workloads. The application example used in this series is Alleycat, which allows bike racers to compete with each other virtually on home exercise bikes.
Part 1 explains the application’s functionality, how to deploy to your AWS account, and provides an architectural review. Part 2 compares different ways to ingest streaming data into Amazon Kinesis Data Streams and shows how to optimize shard capacity. Part 3 uses Amazon Kinesis Data Firehose with AWS Lambda to implement the all-time rankings functionality.
This post walks through the leaderboard functionality in the application. This solution uses Kinesis Data Streams, Lambda, and Amazon DynamoDB to provide both real-time and historical rankings.
To set up the example, visit the GitHub repo and follow the instructions in the README.md file. Note that this walkthrough uses services that are not covered by the AWS Free Tier and incur cost.
Overview of leaderboards in Alleycat
Alleycat races are 5 minutes long and run continuously throughout the day for each class. Competitors select a class type and automatically join the current race by choosing Start Race. There are up to 1,000 competitors per race. To track performance, there are two types of leaderboard in Alleycat: Race results for completed races and the Realtime rankings for active races.

- The user selects a completed race from the dropdown to a leaderboard ranking of results. This table is not real time and only reflects historical results.
- The user selects the Here now option to see live results for all competitors in the current virtual race for the chosen class.
Architecture overview
The backend microservice supporting these features is located in the 1-streaming-kds directory in the GitHub repo. It uses the following architecture:

- The tumbling window function receives results every second from Kinesis Data Streams. This function aggregates metrics and saves the latest results to the application’s DynamoDB table.
- DynamoDB Streams invoke the publishing Lambda function every time an item is changed in the table. This reformats the message and publishes to the application’s IoT topic in AWS IoT Core to update the frontend.
- The final results function is an additional consumer on Kinesis Data Streams. It filters for only the last result in each competitor’s race and publishes the results to the DynamoDB table.
- The frontend calls an Amazon API Gateway endpoint to fetch the historical results for completed races via a Lambda function.
Configuring the tumbling window function
This Lambda function aggregates data from the Kinesis stream and stores the result in the DynamoDB table:

This function receives batches of 1,000 messages per invocation. The messages may contain results for multiple races and competitors. The function groups the results by race and racer ID and then flattens the data structure. It writes an item to the DynamoDB table in this format:
{
"PK": "race-5403307",
"SK": "results",
"ts": 1620992324960,
"results": "{\"0\":167.04,\"1\":136,\"2\":109.52,\"3\":167.14,\"4\":129.69,\"5\":164.97,\"6\":149.86,\"7\":123.6,\"8\":154.29,\"9\":89.1,\"10\":137.41,\"11\":124.8,\"12\":131.89,\"13\":117.18,\"14\":143.52,\"15\":95.04,\"16\":109.34,\"17\":157.38,\"18\":81.62,\"19\":165.76,\"20\":181.78,\"21\":140.65,\"22\":112.35,\"23\":112.1,\"24\":148.4,\"25\":141.75,\"26\":173.24,\"27\":131.72,\"28\":133.77,\"29\":118.44}",
"GSI": 2
}
This transformation significantly reduces the number of writes to the DynamoDB table per function invocation. Each time a write occurs, this triggers the publishing process and notifies the frontend via the IoT topic.
DynamoDB can handle almost any number of writes to the table. You can set up to 40,000 write capacity units with default limits and can request even higher limits via an AWS Support ticket. However, you may want to limit the throughput to reduce the WCU cost.
The tumbling window feature of Lambda allows invocations from a streaming source to pass state between invocations. You can specify a window interval of up to 15 minutes. During the window, a state is passed from one invocation to the next, until a final invocation at the end of the window. Alleycat uses this feature to buffer aggregated results and only write the output at the end of the tumbling window:
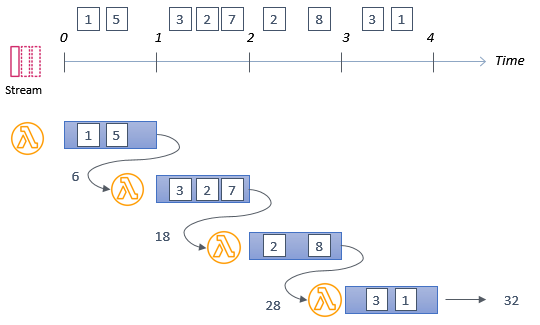
For a tumbling window period of 5 seconds, this means that the Lambda function is invoked multiple times, passing an intermediate state from invocation to invocation. Once the window ends, it then writes the final aggregated result to DynamoDB. The tradeoff in this solution is that it reduces the number of real-time notifications to the frontend since these are published from the table’s stream. This increases the latency of live results in the frontend application.

Implementing tumbling windows in Lambda functions
The template.yaml file describes the tumbling Lambda function. The event definition specifies the tumbling window duration in the TumblingWindowInSeconds attribute:
TumblingWindowFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: tumblingFunction/
Handler: app.handler
Runtime: nodejs14.x
Timeout: 15
MemorySize: 256
Environment:
Variables:
DDB_TABLE: !Ref DynamoDBtableName
Policies:
DynamoDBCrudPolicy:
TableName: !Ref DynamoDBtableName
Events:
Stream:
Type: Kinesis
Properties:
Stream: !Sub "arn:aws:kinesis:${AWS::Region}:${AWS::AccountId}:stream/${KinesisStreamName}"
BatchSize: 1000
StartingPosition: TRIM_HORIZON
TumblingWindowInSeconds: 15
When you enable tumbling windows, the function’s event payload contains several new attributes:
{
"Records": [
{
...
}
],
"shardId": "shardId-000000000000",
"eventSourceARN": "arn:aws:kinesis:us-east-2:123456789012:stream/alleycat",
"window": {
"start": "2021-05-05T18:51:00Z",
"end": "2021-05-05T18:51:15Z"
},
"state": {},
"isFinalInvokeForWindow": false,
"isWindowTerminatedEarly": false
}
These include:
- Window start and end: The beginning and ending timestamps for the current tumbling window.
- State: An object containing the state returned from the previous invocation, which is initially empty in a new window. The state object can contain up to 1 MB of data.
- isFinalInvokeForWindow: Indicates if this is the last invocation for the current window. This only occurs once per window period.
- isWindowTerminatedEarly: A window ends early if the state exceeds the maximum allowed size of 1 MB.
The event handler in app.js uses tumbling windows if they are defined in the AWS SAM template:
// Main Lambda handler
exports.handler = async (event) => {
// Retrieve existing state passed during tumbling window
let state = event.state || {}
// Process the results from event
let jsonRecords = getRecordsFromPayload(event)
jsonRecords.map((record) => raceMap[record.raceId] = record.classId)
state = getResultsByRaceId(state, jsonRecords)
// If tumbling window is not configured, save and exit
if (event.window === undefined) {
return await saveCurrentRaces(state)
}
// If tumbling window is configured, save to DynamoDB on the
// final invocation in the window
if (event.isFinalInvokeForWindow) {
await saveCurrentRaces(state)
} else {
return { state }
}
}
The final results function and API
The final results function filters for the last event in each competitor’s race, which contains the final score. The function writes each score to the DynamoDB table. Since there may be many write events per invocation, this function uses the Promise.all construct in Node.js to complete the database operations in parallel:
const saveFinalScores = async (raceResults) => {
let paramsArr = []
raceResults.map((result) => {
paramsArr.push({
TableName : process.env.DDB_TABLE,
Item: {
PK: `race-${result.raceId}`,
SK: `racer-${result.racerId}`,
GSI: result.output,
ts: Date.now()
}
})
})
// Save to DDB in parallel
await Promise.all(paramsArr.map((params) => documentClient.put (params).promise()))
}
Using this approach, each call to documentClient.put is made without waiting for a response from the SDK. The call returns a Promise object, which is in a pending state until the database operation returns with a status. Promise.all waits for all promises to resolve or reject before code execution continues. Comparing the serial and concurrent approach, this reduces the overall time for multiple database writes. The tradeoff is that it increases the number of writes to DynamoDB and the number of WCUs consumed.

For a large number of put operations to DynamoDB, you can also use the DocumentClient’s batchWrite operation. This delegates to the underlying DynamoDB BatchWriteItem operation in the AWS SDK and can accept up to 25 separate put requests in a single call. To handle more than 25, you can make multiple batchWrite requests and still use the parallelized invocation method shown above.
The DynamoDB table maintains a list of race results with one item per racer per race:

The frontend calls an API Gateway endpoint that invokes the getLeaderboard function. This function uses the DocumentClient’s query API to return results for a selected race, sorted by a global secondary index containing the final score:
const AWS = require('aws-sdk')
AWS.config.region = process.env.AWS_REGION
const documentClient = new AWS.DynamoDB.DocumentClient()
// Main Lambda handler
exports.handler = async (event) => {
const classId = parseInt(event.queryStringParameters.classId)
const params = {
TableName: process.env.DDB_TABLE,
IndexName: 'GSI_PK_Index',
KeyConditionExpression: 'PK = :ID',
ExpressionAttributeValues: {
':ID': `class-${classId}`
},
ScanIndexForward: false,
Limit: 1000
}
const result = await documentClient.query(params).promise()
return result.Items
}
By default, this returns the top 1,000 places by using the Limit parameter. You can customize this or use pagination to implement fetching large result sets more efficiently.
Conclusion
In this post, I explain the all-time leaderboard logic in the Alleycat application. This is an asynchronous, eventually consistent process that checks batches of incoming records for new personal best records. This uses Kinesis Data Firehose to provide a zero-administration way to deliver and process large batches of records continuously.
This post shows the architecture in Alleycat and how this is defined in AWS SAM. Finally, I walk through how to build a data transformation Lambda function that decodes a payload and returns records back to Kinesis.
Part 5 discusses how to troubleshoot issues in Alleycat and how to monitor streaming applications generally.
For more serverless learning resources, visit Serverless Land.