AWS Compute Blog
Building serverless applications with streaming data: Part 3
February 12, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more.
This series is about building serverless solutions in streaming data workloads. These are traditionally challenging to build, since data can be streamed from thousands or even millions of devices continuously. The application example used in this series is Alleycat, which allows bike racers to compete with each other virtually on home exercise bikes.
Part 1 explains the application’s functionality, how to deploy to your AWS account, and provides an architectural review. Part 2 compares different ways to ingest streaming data into Amazon Kinesis Data Streams and shows how to optimize shard capacity.
In this post, I explain how the all-time rankings functionality is implemented. This uses Amazon Kinesis Data Firehose to deliver hundreds of thousands of data points for processing by AWS Lambda functions.
To set up the example, visit the GitHub repo and follow the instructions in the README.md file. Note that this walkthrough uses services that are not covered by the AWS Free Tier and incur cost.
Overview of real time rankings in Alleycat
In the example scenario, there are 40,000 users and up to 1,000 competitors may race at any given time. While a competitor is racing, there is a real time rankings display that shows their performance in the selected class:

The racer can select Here now to compare against racers in the current virtual race. Alternatively, selecting All time compares their performance against the best performance of all races who have ever competed in the race. The rankings board is dynamic and shows the rankings for the current second on the display for the local racer:
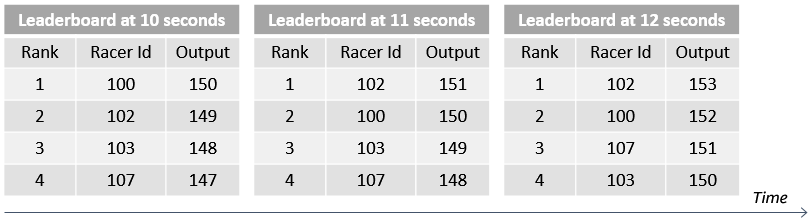
In Alleycat, races occur every five minutes continuously, and the all-time data is gathered from races that are completed. For this to work, the application must do the following:
- Continuously aggregate race data from each of the six exercise classes and deliver to an Amazon S3 bucket.
- Compare the incoming race data with the personal best records for every competitor in the same class.
- If the current performance is a record, update the all-time best records dataset.
- Compress the dataset, since there are thousands of racers, each with 5 minutes of personal racing history.
The resulting dataset contains second-by-second personal records for every racer in a selected race. This is saved in the application’s history bucket in S3 and loaded by the Alleycat front end before the beginning of each race:
// From Home.vue's loadRealtimeHistory method
// Load gz from S3 history bucket, unzip and parse to JSON
const URL = `https://${this.$appConfig.historyBucket}.s3.${this.$appConfig.region}.amazonaws.com/class-${this.selectedClassId}.gz`
const response = await axios.get(URL, { responseType: 'arraybuffer' })
const buffer = Buffer.from(response.data, 'base64')
const dezipped = await gunzip(buffer)
const history = JSON.parse(dezipped.toString())
Architecture overview
The backend microservice handling this feature is located in the 2-streaming-kdf directory in the GitHub repo. It uses the following architecture:

- Amazon Kinesis Data Firehose is a consumer of Kinesis Data Streams. Records are delivered from the application’s main stream as they arrive.
- Kinesis Data Firehose invokes a data transformation Lambda function. This calculates the output for each racer’s data points and returns the modified records to Kinesis.
- Kinesis Data Firehose delivers batches of records to an S3 bucket.
- When objects are written to the S3 bucket, this event triggers the S3 processor Lambda function. This compares incoming racer performance with historical records.
- The Lambda function saves the new all-time records in a compressed format to the application’s history bucket in S3.
The process happens continuously providing that new records are delivered to the application’s main Kinesis stream.
Using Kinesis Data Firehose
Kinesis Data Firehose can consume records from Kinesis Data Streams, or directly from the AWS SDK, AWS IoT Core, and other data producers. In Alleycat, there are multiple consumers that process incoming data, so Kinesis Data Firehose is configured as a consumer on the main stream.
The process of updating historical records is not a real-time process in Alleycat. Processing individual racer messages and comparing against all-time records is possible but would be computationally more complex. In practice, only a few incoming data points are all-time records. As a result, Alleycat asynchronously processes batches of records to find and update all-time records. The process is eventually consistent and the tradeoff is latency. There may be up to 1 minute between recording a personal record and updating the historical dataset in S3.
Kinesis Data Firehose provides several key functions for this process. First, it batches groups of messages based upon the batching hints provided in the AWS Serverless Application Model (AWS SAM) template. This application buffers records for up to 60 seconds or until 1 MB of records are available, whichever is reached first. You can adjust these settings and batch for up to 900 seconds or 128 MB of data. Note that these settings are hints and not absolute – the service can dynamically adjust these if data delivery falls behind data writing in the stream. As a result, hints should be treated as guidance and the actual settings may change.
Kinesis Data Firehose also enables data compression before delivery in various common formats. Since the S3 delivery bucket is an intermediary storage location in this application, using data compression reduces the storage cost. Kinesis can also encrypt data before delivery but this feature is not used in Alleycat. Finally, Kinesis Data Firehose can transform the incoming records by invoking a Lambda function. This enables the application to calculate the racer’s output before delivering the records.
The configuration for Kinesis Data Firehose, the S3 buckets, and the Lambda function is located in the template.yaml file in the GitHub repo. This AWS SAM template shows how to define the complete integration:
DeliveryStream:
Type: AWS::KinesisFirehose::DeliveryStream
DependsOn:
- DeliveryStreamPolicy
Properties:
DeliveryStreamName: "alleycat-data-firehose"
DeliveryStreamType: "KinesisStreamAsSource"
KinesisStreamSourceConfiguration:
KinesisStreamARN: !Sub "arn:aws:kinesis:${AWS::Region}:${AWS::AccountId}:stream/${KinesisStreamName}"
RoleARN: !GetAtt DeliveryStreamRole.Arn
ExtendedS3DestinationConfiguration:
BucketARN: !GetAtt DeliveryBucket.Arn
BufferingHints:
SizeInMBs: 1
IntervalInSeconds: 60
CloudWatchLoggingOptions:
Enabled: true
LogGroupName: "/aws/kinesisfirehose/alleycat-firehose"
LogStreamName: "S3Delivery"
CompressionFormat: "GZIP"
EncryptionConfiguration:
NoEncryptionConfig: "NoEncryption"
Prefix: ""
RoleARN: !GetAtt DeliveryStreamRole.Arn
ProcessingConfiguration:
Enabled: true
Processors:
- Type: "Lambda"
Parameters:
- ParameterName: "LambdaArn"
ParameterValue: !GetAtt FirehoseProcessFunction.Arn
Once Kinesis Data Firehose is set up, there is no ongoing administration. The service scales automatically to adjust to the amount of the data available in the application’s Kinesis data stream.
How the Lambda data transformer works
Kinesis Data Firehose buffers up to 3 MB before invoking the data transformation function (you can configure this setting with the ProcessingConfiguration API). The service delivers records as a JSON array:
{
"invocationId": "d8ce3cc6-abcd-407a-abcd-d9bc2ce58e72",
"sourceKinesisStreamArn": "arn:aws:kinesis:us-east-2:012345678912:stream/alleycat",
"deliveryStreamArn": "arn:aws:firehose:us-east-2:012345678912:deliverystream/alleycat-firehose",
"region": "us-east-2",
"records": [
{
"recordId": "49617596128959546022271021234567...",
"approximateArrivalTimestamp": 1619185789847,
"data": "eyJ1dWlkIjoiYjM0MGQzMGYtjI1Yi00YWM4LThjY2QtM2ZhNThiMWZmZjNlIiwiZXZlbnQiOiJ1cGRhdGUiLCJkZXZpY2VUaW1lc3RhbXiOjE2MTkxODU3ODk3NUsInNlY29uZCI6MwicmFjZUlkIjoxNjE5MTg1NjIwMj1LCJuYW1lIjoiSHViZXJ0IiwicmFjZXJJZCI6MSwiY2xhc3NJZCI6MSwiY2FkZW5jZSI6ODAsInJlc2lzdGFuY2UiOjc4fQ==",
"kinesisRecordMetadata": {
"sequenceNumber": "49617596128959546022271020452",
"subsequenceNumber": 0,
"partitionKey": "1619185789798",
"shardId": "shardId-000000000000",
"approximateArrivalTimestamp": 1619185789847
}
},
...
The payload contains metadata about the invocation and data source and each record contains a recordId and a base64 encoded data attribute. The Lambda function can then decode and modify the data attribute for each record as needed. The Lambda function must finally return a JSON array of the same length as the incoming event.records array, with the following attributes:
- recordId: this must match the incoming recordId, so Kinesis can map the modified data payload back to the original record.
- result: this must be “Ok”, “Dropped”, or “ProcessingFailed”. “Dropped” means that the function has intentionally removed a payload from processing. Any records with “ProcessingFailed” are delivered to the S3 bucket in a folder called processing-failed. This includes metadata indicating the number of delivery attempts, the timestamp of the last attempt, and the Lambda function’s ARN.
- data: the returned data payload must be base64 encoded and the modified record must be within the 1 MB limit per record.
The transformer function in Alleycat shows how to implement this process in Node.js:
exports.handler = (event) => {
const output = event.records.map((record) => {
// Extract JSON record from base64 data
const buffer = Buffer.from(record.data, "base64").toString()
const jsonRecord = JSON.parse(buffer)
// Add calculated field
jsonRecord.output = ((jsonRecord.cadence + 35) * (jsonRecord.resistance + 65)) / 100
// Convert back to base64 + add a newline
const dataBuffer = Buffer.from(JSON.stringify(jsonRecord) + "\n", "utf8").toString("base64")
return {
recordId: record.recordId,
result: "Ok",
data: dataBuffer,
}
})
console.log(`{ recordsTotal: ${output.length} }`)
return { records: output }
}
If you are processing the data in downstream services in JSON format, adding a newline at the end of the data buffer for each record can simplify the import process.
The data transformation Lambda function can run for up to 5 minutes and can use other AWS services for data processing. The Kinesis Data Firehose service scales up the Lambda function automatically if traffic increases, up to 5 outstanding invocations per shard (or 10 if the destination is Splunk).
Processing the Kinesis Data Firehose output
Kinesis Data Firehose puts a series of objects in the intermediary S3 bucket. Each put event invokes the S3 processor Lambda function. This function compares each data point to historical best performance, per racer ID, per class ID, at the same second of the race.
Data points that do not beat existing records are discarded. Otherwise, the function merges new historical records into the dataset and saves the result into the final S3 history bucket. This object is compressed in gzip format and contains the history for a single class ID.
When the frontend downloads this dataset from the S3 bucket, it decompresses the object. The resulting JSON structure shows personal output records per racer ID for each second of the race. The frontend uses this data to update the leaderboard on the local device during each second of the active race.

Conclusion
In this post, I explain the all-time leaderboard logic in the Alleycat application. This is an asynchronous, eventually consistent process that checks batches of incoming records for new personal records. This uses Kinesis Data Firehose to provide a zero-administration way to deliver and process large batches of records continuously.
This post shows the architecture in Alleycat and how this is defined in AWS SAM. Finally, I walk through how to build a data transformation Lambda function that correctly decodes a payload and returns records back to Kinesis.
Part 4 show how to combine Kinesis with Amazon DynamoDB to support queries for streaming data. Alleycat uses this architecture to provide real-time rankings for competitors in the same virtual race.
For more serverless learning resources, visit Serverless Land.