AWS Database Blog
Category: Technical How-to
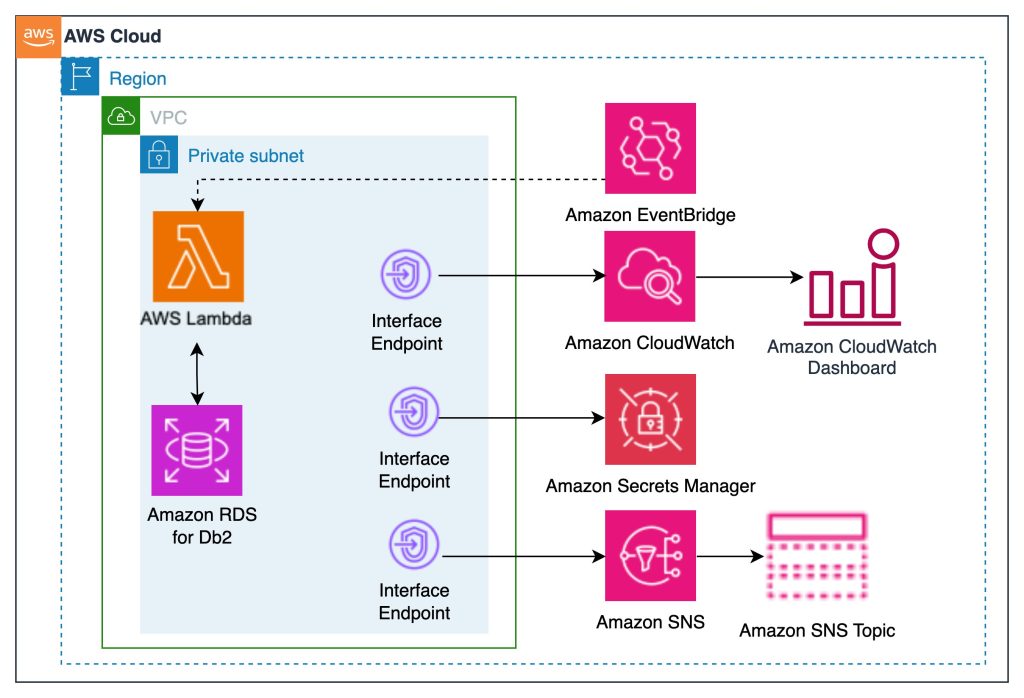
Create monitoring dashboard for Amazon RDS for Db2
In this post, we walk you through deploying an automated Amazon CloudWatch monitoring dashboard for Amazon RDS for Db2. This solution works for both internet-connected (online) and private subnet (air-gapped) environments, requiring no manual console steps.

DSQL SQL Dialect: How Amazon Aurora DSQL differs from single-instance PostgreSQL
This post is for database architects, developers, and DBAs who must evaluate Amazon Aurora DSQL or work with PostgreSQL workloads on a distributed database. Knowing exactly where Amazon Aurora DSQL aligns with standard PostgreSQL and where it diverges helps you to reduce risk and design schemas that perform well from day one. You might find that most existing PostgreSQL applications work with minimal changes.

How Kajabi optimized costs with Amazon Aurora upgrades
In this post, we show you how Kajabi navigated complex Aurora PostgreSQL database upgrades and achieved an 80.53% cost reduction through strategic planning and technical execution. You’ll discover their hybrid approach combining Amazon Aurora blue/green deployments with PostgreSQL native replication. You’ll also learn about their implementation of Aurora I/O-Optimized storage and the key lessons from their journey. Whether you’re managing large-scale databases or planning your own upgrade path, Kajabi’s experience offers valuable insights. You’ll see how to balance performance requirements with cost optimization while maintaining continuous availability.

Best practices and architecture patterns for cross-account sharing in Oracle Database@AWS
In this post, we walk through the available options for sharing Oracle Database@AWS (ODB@AWS) resources across AWS accounts. We also cover common cross-account architecture patterns, along with best practices and key considerations. This helps you design your ODB@AWS architecture across your AWS accounts efficiently.

AWS purpose-built database recovery: A guide to business continuity and disaster recovery strategies
This post addresses recovery challenges in multi-database architectures, focusing on both low-consistency and mission-critical scenarios. We explore practical strategies for implementing resilient recovery mechanisms across Amazon DynamoDB, Amazon Aurora, Amazon Neptune, Amazon OpenSearch Service, and other AWS database services.

Getting started with the Oracle Database@AWS high performance networking
In this post, we explore Oracle Database@AWS high performance networking capabilities and provide a step-by-step guide to help you configure and deploy this feature.

Build resilient Kerberos authentication for Aurora Global Database without joining Active Directory domain
In this post, we show you how to build a multi-Region Kerberos authentication system that matches your Aurora Global Database’s resilience using AWS Directory Service for Microsoft Active Directory (AWS Managed Microsoft AD) with multi-Region replication and a one-way forest trust to your on-premises Active Directory, so your Linux clients can authenticate without joining the AD domain.

Improving storage with additional storage volumes in Amazon RDS for SQL Server
As SQL Server workloads grow on Amazon Relational Database Service (Amazon RDS) for Db2, the 64 TiB storage limit can force architectural issues that constrain business growth and create performance bottlenecks when transaction logs compete with data for I/O resources. The additional storage volumes feature in Amazon RDS for SQL Server solves these challenges. You can use Amazon RDS for SQL Server to attach additional storage volumes beyond the root volume, with each volume having different storage classes and performance characteristics. In this post, you will learn how to use the additional storage volumes feature in Amazon RDS for SQL Server to address these common challenges.

Accelerate database migration to Amazon Aurora DSQL with Kiro and Amazon Bedrock AgentCore
In this post, we walk through the steps to set up the custom migration assistant agent and migrate a PostgreSQL database to Aurora DSQL. We demonstrate how to use natural language prompts to analyze database schemas, generate compatibility reports, apply converted schemas, and manage data replication through AWS DMS. As of this writing, AWS DMS does not support Aurora DSQL as target endpoint. To address this, our solution uses Amazon Simple Storage Service (Amazon S3) and AWS Lambda functions as a bridge to load data into Aurora DSQL.

Options for changing AWS KMS encryption key for Amazon RDS databases
In this post, we review the options for changing the AWS KMS key on your Amazon RDS database instances and on your Amazon RDS and Aurora clusters. We start with the most common approach, which is the snapshot method, and then we include additional options to consider when performing this change on production instances and clusters that can mitigate downtime. Each of the approaches mentioned in this post can be used for cross-account or cross-Region sharing of the instance’s data while migrating it to a new AWS KMS key.