AWS Database Blog
Learn how Dream11, the World’s largest fantasy sports platform, scale their social network with Amazon Neptune and Amazon ElastiCache
This is a guest post co-written by Bharat Kumar, Graph Databases Lead at Dream11.
Dream11, the flagship brand of Dream Sports, is the world’s largest fantasy sports platform, with more than 100 million users. We have infused the latest technologies of analytics, machine learning, social networks, and media technologies to enhance user experience. Dream11 is the epitome of India’s sports technology revolution.
Dream11 hosts thousands of contests every day across multiple live sporting events. We have built several social features in the app, as our users love to know what their fellow sports fans do on the platform. They also love to banter on the live matches, the contests they participate in and how their teams are performing. High popularity of these features can be gauged by looking at the user engagement data. These social features are powered by our system named Social Network Service, which went live in 2019. It is used at extremely high throughput by several other downstream services.
The Social Network Service has helped Dream11 evolve as a social sports platform. The service stores the user network graph and serves network-related information required to power the social features. It helps sort and reorder information presented to users in response to their social interactions, likes, and preferences.
This blog post discusses the technical challenges, implementation details, and uses of Dream11’s Social Network Service.
The social network universe in Dream11
Let’s look at the social features in the Dream11 app, after which we discuss how we built a backbone for them.
- Feed – In this newsfeed, users can share rich content and engage with content shared by others through reactions and comments. Automated system generated messages around user achievements are also displayed here. Handling celebrities with millions of followers poses technological challenges for the newsfeed, because for every new post by such celebrities, messages need to be added to the newsfeeds of their millions of followers. We refer to this process as fanning out.
- Profile recommendations – Users are always interested in finding interesting people to follow. That’s what makes the experience of using social networks very rewarding. Our systems proactively recommend interesting users to follow. It analyzes the social graph (particularly the second-degree connections), user interactions, and user behavior to come up with its recommendations.

- Profile – Your profile on any social network is very important. It shows your activities and other attributes, leading to increased trust among users. Dream11 shows followers and followings (list as well as count) on user profiles.

- Groups and chat – Users on the platform can use their connections to form groups and have engaging discussions with them, compare performances, and see the relative standings in a group leaderboard.

- Social in gameplay – Dream11 hosts over 100 different types of contests for every single sports match. One of the factors that encourages users to join a contest is seeing that some of the people they follow (and know) are already in the contest. This awakens the human spirit of competition. Social Butterfly, one of our downstream services, powers this feature by analyzing user connections. When a match begins, users can even filter the leaderboard by people in their network.

Many more engaging features are coming very soon. All these features and services are powered by the Social Network Service.
Requirements of the Social Network Service
The following illustration is a sample representation of what Dream11’s user social graph looks like. It’s a large network graph of millions of users. Dream11’s social platform is a leader-follower type of platform. The graph consists of nodes and edges: each node represents a user in the Dream11 universe, and each edge represents a follow connection from one user to another.
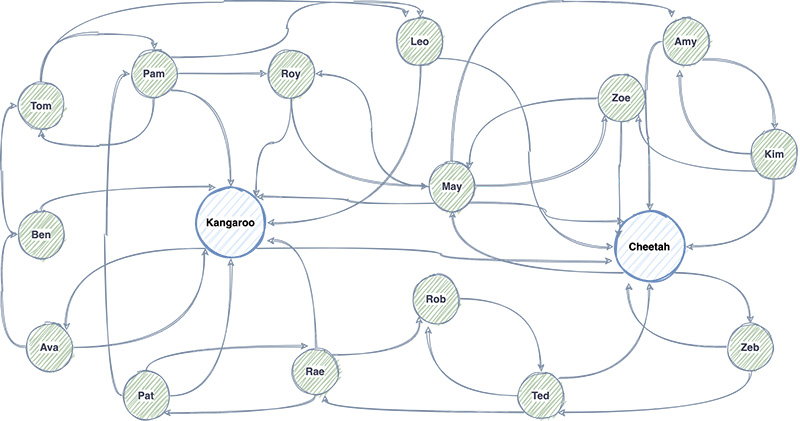
When we launched the social features, we had a hard limit of a maximum 1,000 followers per user, and a user could only follow 1,000 other users. However, due to the popularity of social features, we had to increase the limit to 5,000 in no time.
As these social features started to become popular, we saw a few celebrities emerge within our user network. These users have a large number of followers (such as Kangaroo and Cheetah in the preceding diagram). Inspired by this, we wanted to take it to another level by opening up the network to allow for up to 10 million followers. But that meant creating a system that can handle a large volume of social network data and has robust fault tolerance, fast response times, and everything else that a system needs to succeed at the massive scale of Dream11.
Before we dive into the architecture of the system, let’s review some of the crucial requirements of such a system:
- Fast response times – The microservice would be used by many other microservices in the mesh of services at Dream11. As we discuss later in this post, a few crucial high-throughput APIs require single-digit millisecond latency. Therefore, this service needs to be very fast.
- Fault tolerance and system uptime – We needed a system that can guarantee a great uptime. Because this service would be at the core of all the social networking features, downtime for this service can impact multiple downstream services.
- Large-scale data management – Each user node could have up to 5,000 outgoing follow connections. The data continues to grow as this network grows, so we also need to ensure whatever storage layers we use in this service can scale accordingly.
- Scalability – Dream11 sees a spiky traffic pattern. Our users flock to the apps around match start times, and because we host a multitude of matches across sports, it’s hard to be prepared well in advance. Our system needs to be able to handle scaling up and down as needed within a few minutes.
Social Network Service architecture
In this section, we walk through the architecture of the Social Network Service and how it manages and serves the data while taking care of the previously mentioned requirements.
The following diagram illustrates the architecture and its components.

Graph database: Storing the social graph
Graph databases become a natural choice for a persistent storage layer when planning to implement social features. They efficiently enable social graph traversals that are required for queries such as friends in common, friends of friends, clusters of friends, and the shortest path between a pair of nodes. Traditional relational databases or even NoSQL document databases can fail to answer these queries in a reasonable time.
Amazon Neptune graph database
We decided to use Amazon Neptune, a fully managed graph database service from AWS. Dream11 infrastructure is powered by AWS, so Amazon Neptune was a natural candidate. However, due to our highly data-driven approach to selecting any technology component at Dream11, we did rigorous Load / Stress POC with different types of Graph Databases, and Neptune came out as the clear winner. Neptune uses Gremlin as the querying language for Labeled Property Graphs (LPG), which are powered by Apache TinkerPop, a standard graph computing framework popular in the open-source community. This makes it easy to hire skilled experts.
Neptune is a completely managed service running within the VPC, so the overhead for maintaining a self-hosted database is eliminated. We had used other reliable database services from AWS like Amazon Aurora MySQL-Compatible Edition, so we were confident that high availability, scalability, and performance wouldn’t be an issue with Neptune. And I’m happy to say it has proven right.
Graph database schema
We employed an LPG to implement our use case. It comprises two types of entities: nodes and edges, as showcased in the following schema. Each entity is differentiated by labels; for example, two types of edges are in the following schema: a follow edge and a block edge. What the follow edge represents is fairly apparent; however, the block edge indicates that a user has blocked another user. This functionality is available on the platform to avoid harassment of any kind.
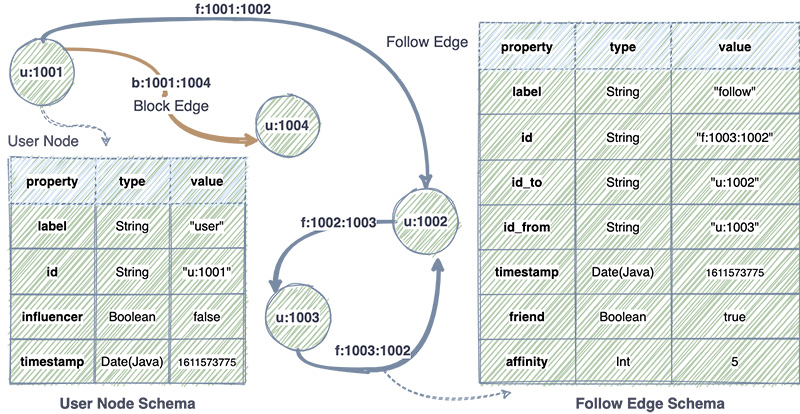
The schema indicates the various properties an entity holds. Although it may be fairly clear what each property represents, let’s take a closer look at some of them:
- Edge IDs – Edge IDs are of the format
f:<follower_user_id>:<following_user_id>. Neptune smartly indexes the properties of an entity. The nomenclature we follow for edge IDs helps us check for the existence of a relationship between any two nodes in the fastest possible manner, avoiding any traversal in the graph. So, answering questions like “Does Sam follow Tim?” or “Has John blocked Ravi?” is just checking for the existence of the respective edges because we know the edge IDs to look for. - Influencer – We also maintain a few additional properties like influencer on the user nodes. This property is marked as true when our algorithms realize that the user is showing influential behavior in our social network.
- Friend – The friend property on follow edges is set to true for the follow edge pair between two user nodes, if they follow each other. This helps us find strong connections in the graph.
- Affinity –The affinity property stores a score: the higher the affinity, the stronger the connection between two people. Affinity gets computed by algorithms developed by our Data Science team. It considers several factors, including but not limited to interactions between the corresponding users, common contests played together, and participation in groups and chats.
Bootstrapping the graph
We started building the Social Network Service in Dream11 and we already had a user base of over 70 million users. It made sense to add all the user nodes corresponding to all the existing users into the graph. Neptune has a bulk loader to load large amounts of data into the database instance. We use it a lot when we do our testing and development. However, as with any platform, not all users necessarily participate in all the features. We decided to add users organically when they perform qualifying events; for example, when a user follows another user. When such an event happens, only then do we add the respective nodes, if not already present in the graph. See the following example Java code snippet:
We’ve used the gremlin-driver, which is a maven dependency maintained by Apache TinkerPop. The traversal functions in the preceding code are from this library itself. The fold, unfold, and coalesce functions are quite helpful while writing such complex operations or queries. To explore Gremlin more, see the book PRACTICAL GREMLIN by Kelvin R. Lawrence.
Amazon ElastiCache for Redis and Apache Kafka
Although Neptune does a fantastic job of maintaining our massive graph, for some of the queries seeking to retrieve information about the graph, other types of non-graph databases may be better suited. It may sound counterintuitive! We explain what we mean shortly.
We implemented this solution with the help of Amazon ElastiCache for Redis and Apache Kafka.
Amazon ElastiCache for Redis
Why did we choose ElastiCache for Redis? Two words: Sorted sets. The major reason to go with Redis is sorted sets. We can never stop praising how awesome sorted sets are. Because Redis has a fine implementation of sorted sets, there isn’t a better caching store in comparison. ElastiCache provides a well-managed Redis out of the box, making it easy to maintain a Redis cluster within your VPC. Therefore, it was the obvious choice.
Graph databases in general, and Neptune in particular, are adept at graph traversals. That’s what they were created for! But when millions of entities are to be touched in real time, millions of times every day, it can take a toll on performance. There could be a more efficient way to provide this functionality.
The Social Network Service serves a lot of data through various API. A few of them have really high throughput requirements, and all of those are reads. Writes aren’t much of a challenge in our use case. The following API calls are where the challenge lies:
- Count of followers and followings
- List of followers and followings
These appear to be very basic calls, but computing this data is non-trivial even for performant graph databases like Neptune, because this data isn’t available as key-value pairs to be retrieved in milliseconds. It needs to be computed every single time. Let’s look at an example: The celebrity user Cheetah has 10 million followers. The general expectation from List APIs is that they should support pagination. Now suppose there’s a requirement to get the user_id of all the followers from the 9 millionth to 9.1 millionth for user Cheetah. For that, we run a Gremlin range query like the following:
In a relational database, it’s easy to skip the first 9 million rows, but in graph databases, the concept of order isn’t manifested in the way information is organized on the disk. Therefore, a query like this means that the traversal has to traverse through the first 9 million “in” edges (or follower edges) just to be able to skip them, and only then can it fetch the data in the specified range.
A similar process happens when trying to get counts. For example, returning a count of all the followers of our celebrity user Cheetah means traversing through all 10 million followers and then getting a total count.
Both queries have a run time complexity of O(n). This is, of course, not optimal at run time. Graph databases work best for most other types of queries on graph data, but for the queries we discussed that involve listing and counting at a massive scale, we needed an expert in key-value pairs. Here is where Redis comes in. But why Redis and not any other key-value datastore?
Redis and sorted sets
As described by Redis.io, “Redis sorted sets are, similarly to Redis sets, non-repeating collections of strings. The difference is that every member of a sorted set is associated with a score. These scores are used to make the sorted set ordered, from the smallest to the greatest score. While members are unique, scores may be repeated.”
We have two sorted sets per user node: one each for a list of followers and a list of following.

As shown in the schema, keys for sorted sets of followers have the format followers_<user_id>, and the values are lists of tuples. A tuple consists of (<user_id, affinity_score>).
Sorted sets in Redis solve all the issues presented earlier with graph databases:
- Pagination – The List APIs can now be served by the
ZRANGEoperation on sorted sets. It has a time complexity ofO(log(N)+M), with N being the number of elements in the sorted set and M the number of elements returned. This changes the seek time to fetch a range effectively fromO(N)toO(log(N)). - Sorting by affinity – By default, the
ZRANGEoperation provides lists of followers in order sorted by the scores associated with each follower. This score field in sorted sets stores the affinity property of the follow edges. - Counts – This involves the
ZCARDoperation, which provides cardinality of sorted sets. It has a time complexity ofO(1), compared toO(N)in a graph database.
Therefore, Redis truly saves the day by making up for what graph databases are not designed for.
Apache Kafka and consumers
We use Apache Kafka to keep our ElastiCache for Redis cluster in sync with graph data in Neptune.
We send events into Kafka corresponding to changes in Neptune. The consumers that consume events from the Kafka broker are Java Applications running on Amazon Elastic Compute Cloud (Amazon EC2) instances.
In our system, in case of any issues, we can run the sync operation even at the individual user level to sync all the Neptune data to Redis for that user. In case of a fresh start or Redis cluster failure, consumers also help populate the data into the Redis cache in bulk. However, this is less likely to happen because we’ve employed a Multi-AZ deployment strategy for our Redis cluster, which has regular snapshotting. The sync between Neptune and Redis is done asynchronously. Whenever a change in the data occurs in Neptune, a message noting that change is posted to Kafka. Kafka consumers read that message and update Redis.
We have one more Kafka topic that maintains all the events published when any changes occur in the graph data in Neptune. It’s used to build and maintain a data store in Amazon Redshift for all our analytics use cases. You can also use Neptune Streams to get events corresponding to the changed data for syncing information to other data stores.
Application layer and performance
Our application layer API is written in Java, and we use Vert.x as our framework. Our application resides in EC2 instances, and they’re behind an Elastic Load Balancer to load balance the incoming requests. Our test stack consisted of one Neptune writer and five Neptune read replicas of size db.r5.12xlarge each, an ElastiCache for Redis cluster of 10 shards, two replicas per shard of size cache.m5.12xlarge each, and 100 EC2 instances at the application layer.
We conducted load tests to ensure that the service scales well and supports all our current and future requirements of single-digit millisecond latencies. We achieved an amazing throughput of 50 million requests per minute with our stack, at a latency of just 1.5 milliseconds! The best part is that this scales horizontally to a potentially much larger throughput when needed. In near future, as Dream11 scales to more than a billion edges in our social network graph, we’ll be ready to easily handle that scale.
Conclusion
Neptune is a graph database purpose-built for the kind of traversals that are often needed in social platforms. ElastiCache for Redis is purpose-built database for queries that need sorted sets, as well as list & count retrievals. All these kinds of queries are common whether you’re building a full-fledged social network or adding significant social features in your existing app.
Dream11’s Social Network Service architecture has been designed with scalable, reliable and highly available purpose-built databases for different types of queries. This has enabled Dream11 to scale its social sports platform and reach its true potential to serve more than 100 million fantasy sports users.
About the authors
 Bharat Kumar is a Director for Backend Engineering at Dream11, and leads Dream11’s Social Sports Platform. His interest areas include solving problems of scale, graph databases, micro-services architecture, and entrepreneurship.
Bharat Kumar is a Director for Backend Engineering at Dream11, and leads Dream11’s Social Sports Platform. His interest areas include solving problems of scale, graph databases, micro-services architecture, and entrepreneurship.
Find him on LinkedIn.
 Girish Dilip Patil is a Principal Architect for SuperApps at AWS, based in Singapore. He focuses on applications of Cloud, AI, Big Data, Media and Graph technologies. He is passionate about innovations in business models brought about by digital technologies. He advised SuperApp customers of AWS active in domains of Ride Sharing, Food & Grocery Delivery, E-Commerce, Social, Gaming.
Girish Dilip Patil is a Principal Architect for SuperApps at AWS, based in Singapore. He focuses on applications of Cloud, AI, Big Data, Media and Graph technologies. He is passionate about innovations in business models brought about by digital technologies. He advised SuperApp customers of AWS active in domains of Ride Sharing, Food & Grocery Delivery, E-Commerce, Social, Gaming.