AWS Database Blog
Migrate Your Procedural SQL Code with the AWS Schema Conversion Tool
Database administrators and developers rely on relational databases to store data for applications. As Forbes noted in 2016, the development of open source offerings for database management systems like PostgreSQL is causing a growing number of enterprises to migrate to lower-cost solutions for their data storage. The move to the cloud often provides an excellent opportunity to make such a change.
If your system contains a lot of business logic in the database, it can be quite a large task to translate between SQL dialects line by line. Fortunately, Amazon Web Services offers the AWS Schema Conversion Tool (AWS SCT), a standalone application with a project-based user interface that does the heavy lifting of translating SQL dialects for you.
Using AWS SCT
This post demonstrates how easy it is to migrate procedural code from Oracle to PostgreSQL using AWS SCT. It includes how to spot the differences between the two dialects and how to modify the code when needed. You can use AWS SCT to generate a high-level overview of the effort required to convert an Oracle database to Amazon RDS for PostgreSQL. In the example, the tool is running on Windows, but it can run on a number of different operating systems. To download AWS SCT, see Installing and Updating the AWS Schema Conversion Tool. For general information about the tool, start with What Is the AWS Schema Conversion Tool?
The example uses an Oracle database on Amazon EC2 and the well-known SCOTT/TIGER database as a starting point. Three stored procedures are added to demonstrate how AWS SCT handles common dialect translations. For information about installing the base SCOTT schema objects, see the Oracle FAQ wiki. You can download additional Oracle procedures and the translated PostgreSQL examples from this repository.
Prerequisites
The example in this post requires the following:
- A source Oracle database with SCOTT schema objects installed
- Three additional stored procedures:
Procedure Source file emp_by_job oracle-emp-by-job.sql get_emp_info oracle-get-emp-info.sql employee_report oracle-employee-report.sql - Target Amazon RDS for PostgreSQL database
- AWS SCT installed
Generate an assessment report
Typically, the first step in a migration is to understand its feasibility and the effort it will require. You can use AWS SCT to generate a high-level overview of the work ahead. In this example, open the context (right-click) menu for the SCOTT schema, and choose Create Report. The assessment report provides a high-level summary of how much of the schema can be converted automatically from Oracle to PostgreSQL, and the work that will be left after conversion.
The following screenshot shows the results of the assessment.

The good news is that in this case, AWS SCT can convert all the database storage objects and two-thirds of the database code objects. That leaves only the remaining one-third of the database code objects to be reviewed and adjusted manually.
Convert the schema
It’s easy to use AWS SCT to convert your Oracle schema. In the left panel in the tool, open the context (right-click) menu for the Oracle SCOTT schema, and choose Convert Schema to examine the code changes in detail.

The working dialog box with a progress bar appears for a few minutes during the conversion.

Automatic conversion
In this example, two of the procedures (SCOTT.EMP_BY_JOB and SCOTT.GET_EMP_INFO) convert without additional changes to PostgreSQL dialect PL/pgSQL. Many of the familiar Oracle constructs like REFCURSOR and IN/OUT parameters have a clear 1:1 mapping between PL/SQL and PL/pgSQL.
Example 1: emp_by_job
The emp_by_job function converts easily between the two dialects because they are largely similar.

Note the following key differences between the two dialects:
- In PostgreSQL, all PL/pgSQL code is stored as a function and must return something either through an
OUTparameter or through aRETURNclause. - All code in the statement section of a function must be enclosed in quotes.For better readability, PostgreSQL provides a handy quoting method called “dollar-quoting.” The content is enclosed by a dollar sign ($), followed by an optional “tag” of zero or more characters, and then another dollar sign; for example:
$BODY$<enclosing content>$BODY$ = ‘<enclosing content>’ - The language must be declared explicitly as part of the function declaration. This is because the standard PostgreSQL distribution supports additional languages like PL/Tcl, PL/Perl, and PL/Python, in addition to PL/pgSQL.
AWS SCT automatically translates the differences between the two dialects.
Example 2: get_emp_info
The second function, get_emp_info, also converts easily and translates data types and SQL functions between PL/SQL and PL/pgSQL.

Data types
The NUMBER data type is translated to DOUBLE PRECISION, and the VARCHAR2 parameters are transformed to TEXT. For the complete data type reference for PostgreSQL, see the PostgreSQL documentation.
The emp_number and years_svc parameter values are translated from NUMBER to DOUBLE PRECISION, which may require some thought. The DOUBLE PRECISION value works in this case, but there is also an advantage to using smaller datatypes. DOUBLE PRECISION stores 8 bytes whereas SMALLINT and INTEGER store 2 bytes and 4 bytes respectively. In a production scenario, you may choose to lower at least the years_svc value to a SMALLINT because it’s unlikely that years of service will exceed 32,767 years.
The TEXT value for the remaining parameters requires no change because in PostgreSQL, TEXT and VARCHAR (character varying) perform equivalently. There is no inherent advantage of one or the other because under the hood, they are both a varlena (variable length array).
Functions
When you use AWS SCT to convert your schema, the tool adds another schema to your target database instance: it’s called the extension pack schema, and its name is based on the source database. The schema implements common system functions of the source database that are used when writing your converted schema to your target database. For more information about extension packs, see The AWS Schema Conversion Tool Extension Pack and AWS Services for Databases.
When the Oracle stored procedure was converted to PostgreSQL, there were native equivalent functions for FLOOR and ABS, and so the syntax for those remained the same. To replicate the functionality of the MONTHS_BETWEEN and SYSDATE functions from Oracle, the helper schema aws_oracle_ext is referenced with the same functions residing in that schema on the PostgreSQL target.
Actions required before conversion
The AWS SCT assessment report describes any challenges that you might encounter during conversion. One of the procedures (SCOTT.EMPLOYEE_REPORT) has associated actions that must be performed prior to conversion.
The information in the following screenshot tells you that you have an imperfect object resolution. In this case, in the recursive SQL, there’s a reference to t.level that should actually be t.the_level based on the alias assigned to it.

 There are two notable things about this conversion:
There are two notable things about this conversion:
- The
START WITH… CONNECT BYOracle construct is easily translated to theWITH RECURSIVEsyntax used by PostgreSQL. - You can edit this code inline before you apply it to the database.
In AWS SCT, you can modify the code and change any items that require adjusting. In the following screenshot, the reference to t.level has been changed to t.the_level. In addition, some of the text in the function body was rearranged to make it more readable for the screen capture.
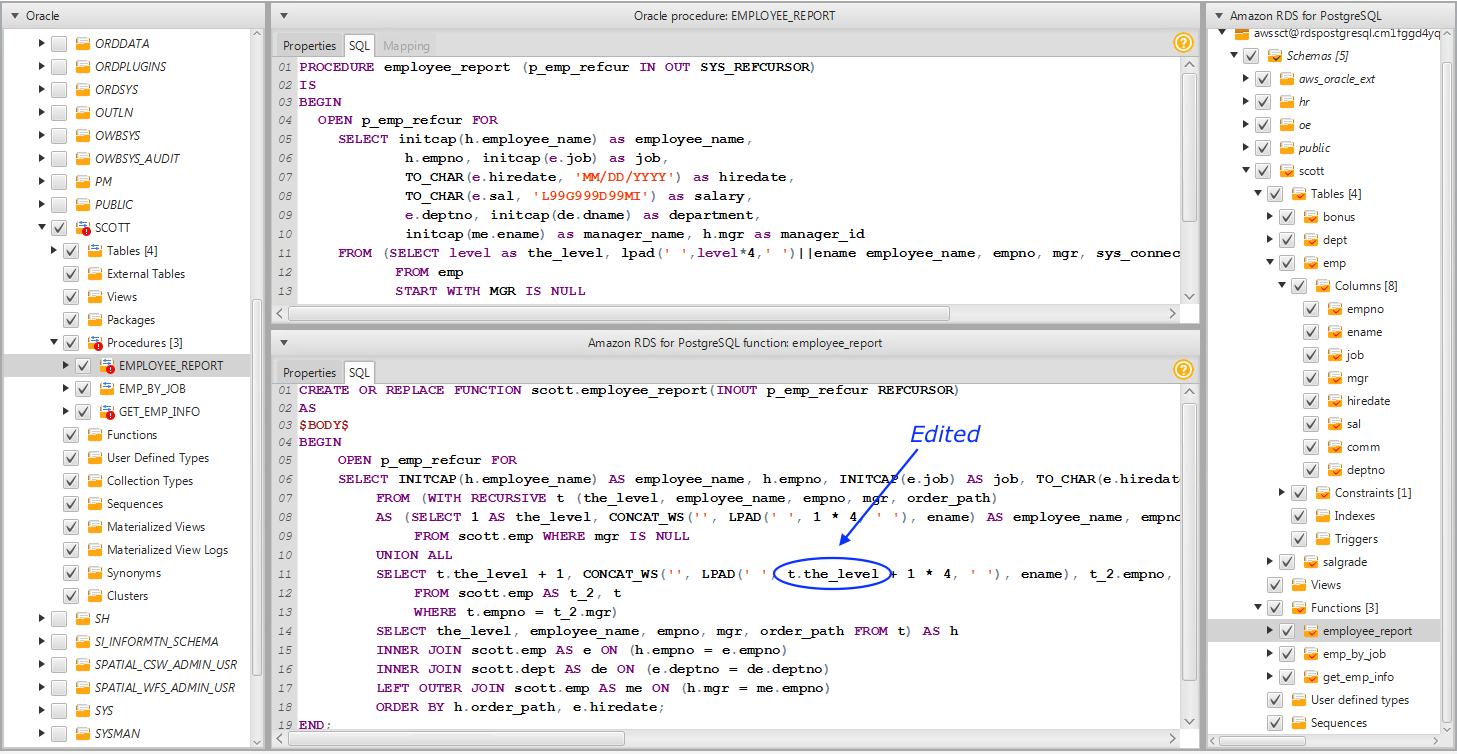
You can also replace the function completely with something different if you want. The following image shows a replacement function that uses a return statement instead of an INOUT parameter.

Apply edits to the database
After making all the changes you need, open the context (right–click) menu for the schema, and choose Apply to database.

AWS SCT writes your database storage objects and database code objects with any edits you made to the target database instance.
Test the functions on the target database
Testing the functions in PostgreSQL is a little simpler than testing their Oracle counterparts.
scott.emp_by_job
PostgreSQL is not a two-phase commit engine by default. Retrieving the results requires a transaction to keep the REFCURSOR open long enough to fetch the rows.
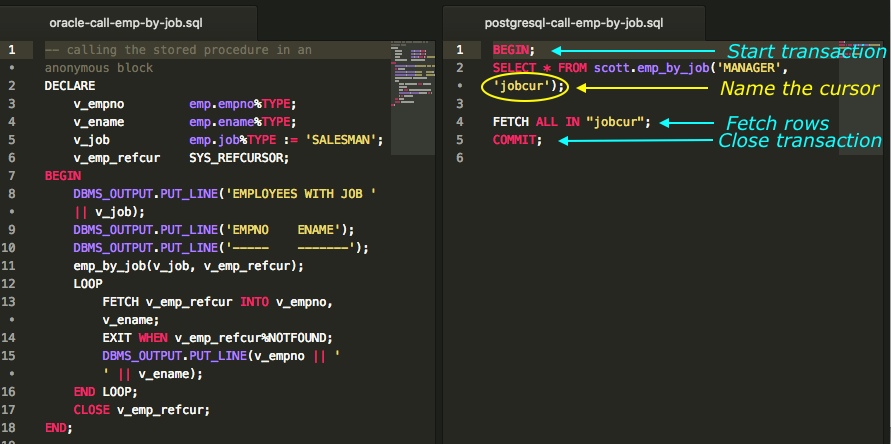
It’s not required that you pass a name in for the REFCURSOR parameter, but if you don’t, the PostgreSQL engine assigns a name to it. The name is something like “<unnamed portal 1>,” where the number “1” increments with each call.
A better option is to provide a name as a single quoted string for the REFCURSOR yourself. In the subsequent fetch call, you can then use that same name in a double-quoted string.
The full testing block for a function that returns a REFCURSOR includes four basic parts:
- Start the transaction
- Call the function, including a name for the
REFCURSOR - Fetch the rows
- Commit the transaction
The output of the REFCURSOR goes to your screen (query tool) just like any other SELECT statement. There’s no need to prepare variables or use looping constructs and print statements.
scott.get_emp_info
Testing the function get_emp_info is a simple one line call that supplies only the emp_number.

The output of the hire_date, emp_name, and years_svc goes to your screen (query tool) as three columns of output just like any other SELECT statement. There’s no need to prepare variables or use looping constructs and print statements.
scott.employee_report
The employee_report function returns a REFCURSOR just as the emp_by_job function does. The call is similar and very short because it doesn’t have to include variable declarations for all the return values, loop constructs, or print statements.

Summary
As you move to the cloud, having a scalable, cost-effective, and fully managed service like Amazon RDS for PostgreSQL can provide a great incentive for moving to an open source engine. With the AWS Schema Conversion Tool, migrating to an open source engine is simpler and less daunting than before.
Recent updates to AWS SCT and AWS DMS make it easier to perform complex migrations between SQL dialects. For more information about recent changes to AWS SCT, see the AWS DMS Release Notes.
About the Author
 Wendy Neu has worked as a Data Architect with Amazon since January 2015. Prior to joining Amazon, she worked as a consultant in Cincinnati, OH helping customers integrate and manage their data from different unrelated data sources.
Wendy Neu has worked as a Data Architect with Amazon since January 2015. Prior to joining Amazon, she worked as a consultant in Cincinnati, OH helping customers integrate and manage their data from different unrelated data sources.