AWS Database Blog
Reduce downtime with Amazon Aurora MySQL database restart time optimizations
When using Amazon Aurora MySQL-Compatible Edition for operating your relational databases in the AWS cloud, one of the key requirements is to verify that it is highly available during planned and unplanned outages. As database administrators, you should perform occasional database maintenance. This can be in the form of database patching, upgrades, database parameter modifications requiring a manual reboot, performing a failover to reduce the time it takes for instance class changes, and so on. All of these actions require downtime as the instance reboots. You can control when some of these database maintenance tasks are applied to your Aurora database resources, making them planned actions.
However, downtime can also be caused by unplanned events such as an unexpected failover due to an underlying hardware fault or database resource throttling, and issues that may cause the mysqld database engine to reboot. Both scenarios, whether planned or unplanned, result in a database restart.
In this post, we discuss new Aurora MySQL optimizations introduced in Aurora MySQL version 3 that allow for reduced downtime and fewer disruptions to your workloads after a restart.
Challenges of database restart
A database restart can be both disruptive and time-consuming. Restarts involve initializing several data structures, validating data in various caches to maintain consistency, and finally opening up the database to process application connections. Due to the variability of time taken at each of the above steps, it is challenging to fully estimate the time for the restart to complete. This is primarily driven by the recovery aspects of a database restart which are subject to the dynamic nature of the workload on the database server at the time of shutdown. For example, if the database is in the middle of long-running transactions and you have binary logs (binlog) enabled in your Aurora MySQL cluster, binlog recovery may add to the overall downtime. For more information, see Recovery from unplanned restarts in the Amazon Aurora User Guide.
During start up, many internal memory components are initialized, the largest one being InnoDB buffer pool initialization. In Aurora MySQL, the InnoDB buffer pool is preconfigured to 75% of the instance memory size by default and the initialization time is proportional to the size of the InnoDB buffer pool. During this initialization phase, the database cannot accept connections, which causes longer downtime during restarts. The new Aurora MySQL optimizations primarily focus on improving the buffer pool initialization process to reduce the database initialization time, which reduces the overall database restart time.
Aurora MySQL database restart time optimizations
New optimizations introduced within Aurora MySQL version 3.05 reduce database downtime that may be caused due to a planned or unplanned restarts. These are one of the first enhancements, and we will continue to evaluate more such opportunities to reduce overall restart times. To dive deep into these improvements, let’s start with a few terms that we associate with restarts:
- Time to reconnect – The time it takes for your application to initiate database connections after it becomes unavailable due to planned or unplanned actions.
- Time to steady state – After connections are re-established with the database, the time it takes for the throughput to climb back to the previous levels before the restart.
- Steady state throughput – This is a measure of the read and write throughput of your database before and after the restart.
The following figure is a graphical description of these terms with throughput on the Y-axis and time on the X-axis. Recovery complete is the time it takes for application connections to reconnect to the database and the time it takes for the database to reach previous throughput levels before the restart.
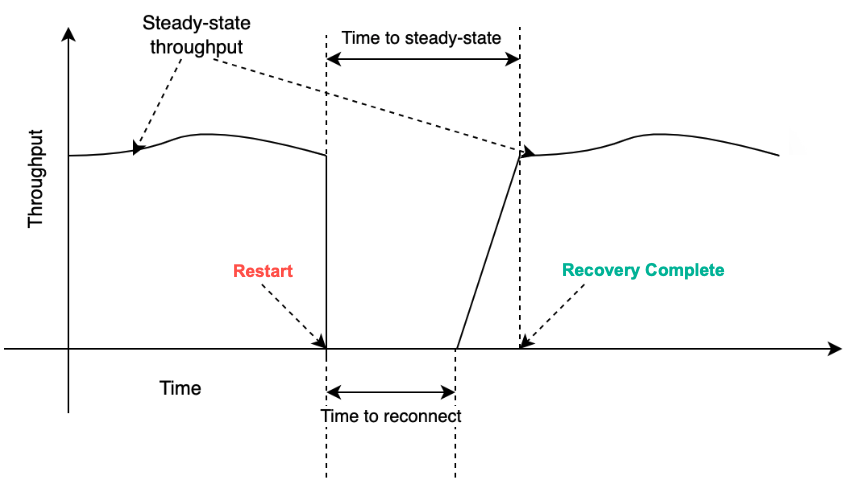
The new Aurora MySQL optimizations have the following goals:
- Improve the time to reconnect
- Keep the difference between time to reconnect and time to steady state as small as possible
- Verify that the steady state throughput isn’t degraded after the restart
The time spent during a database restart can be categorized into several components such as MySQL initialization, buffer pool initialization and validation, binlog and InnoDB recovery. From our analysis of the components that contribute to longer restart times, buffer pool initialization is the top contributor, requiring several seconds to initialize and validate. As discussed above, the InnoDB buffer pool is proportionally large for larger instance classes. This in turn implies a longer buffer pool initialization time which can contribute to longer restart times.
The current implementation of buffer pool in Aurora MySQL employs survivable page cache where each database instance’s page cache is managed in a separate process from the database, which allows the page cache to survive independently of the database. In the unlikely event of a database failure, the page cache remains in memory, which keeps current data pages “warm” in the page cache when the database restarts. Survivable page cache improves performance upon database restart since there is no need for the initial queries to execute additional read I/O operations to “warm up” the cache.
With these optimizations, we have reduced the time it takes to initialize and validate the buffer pool by deferring part of the process to after the database is already online and accepting connections. While some of the buffer pool validation can occur inline with the restart, the essential validation happens before the database starts accepting connections. After careful validation, other non-critical steps have been safely deferred to the first access of a page after the database is already accepting connections. Additionally, we optimized the memory allocation of the locking structures which also contributes to a reduction in the time to reconnect. This reduces the work performed at the time of restart and ultimately lowers the downtime experienced until your database is ready to accept connections. While the actual time to reconnect would be quicker, based on your workload it might take a few additional seconds after the reconnection to complete the remaining validation portions. However, the cumulative time for both time to reconnect and time to steady state would still be less than the earlier mechanism.
The optimizations speed up the overall restart and also keep the restart times consistent across various instance sizes. With the new improvements, you will see overall reduced downtime pertaining to restarts, which in some cases can also prevent failovers in your Aurora cluster as the instance recovery would be much quicker. With the existing benefits of Zero-downtime restart (ZDR), connections to the cluster read/write instance are preserved on a best effort basis.
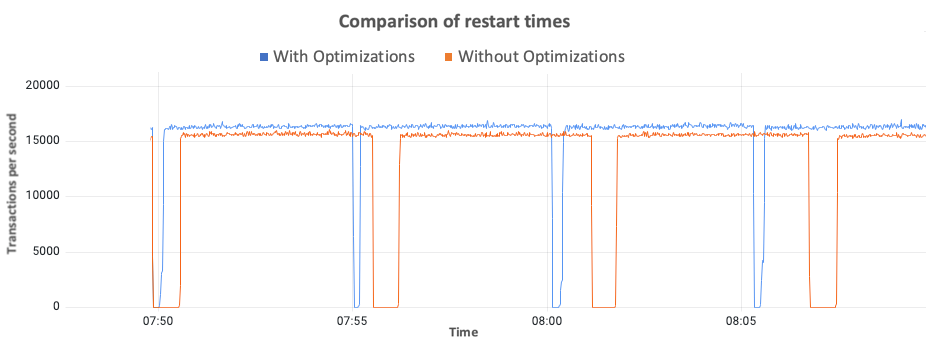
With the database restart optimizations, Aurora MySQL attempts to reduce the gap between the time to reconnect and time to steady state. From our tests, the new optimizations reduce the database restart time by up to 65% versus without optimizations. The following graph compares the time it takes for the database to resume its workload after a restart. The graph is for a db.r5.24xlarge with a read only workload with 64 concurrent threads. The blue line is with the new optimizations, and you can observe that the gap between time to reconnect and time to steady state is much smaller. The red line does not include the new optimizations and takes longer to achieve steady state throughput. In the graph, the difference between transactions per second is within a margin of error to improve readability of the graph and does not imply improved throughput with the latest optimizations on Aurora MySQL.
We observed similar results across multiple synthetic workloads using sysbench with a combination of varying datasets, instance classes, instance sizes, client threads, number of tables, and types of workloads (read, write, or read and write).
The following table shows a comparison of various instance types and the restart times with and without Aurora MySQL optimizations. These results are captured from sysbench tests using a read only workload with 250 tables with 4 million rows. These restart values aren’t absolute and may vary for your workloads.
| Instance type | Without Aurora MySQL optimizations (in seconds) | With Aurora MySQL optimizations
(in seconds) |
Percent improvement |
| db.r5.8xlarge | 10.7 | 5.3 | 50.1% |
| db.r5.12xlarge | 11.6 | 5.4 | 54.5% |
| db.r5.16xlarge | 21.0 | 6.2 | 68.9% |
| db.r5.24xlarge | 35.4 | 6.0 | 83.1% |
Use cases
A database restart can be caused by various reasons. In this section, we discuss the common use cases in which the new optimizations can help your Aurora MySQL database to recover and be available to serve connections faster after a reboot. If you don’t see infrequent restarts on your Aurora database or are happy with the time Aurora MySQL takes to recover, based on our testing, these optimizations shouldn’t alter any existing behavior beyond the reduced time to reconnect. On the other hand, if you occasionally plan maintenance actions resulting in a restart, the new optimizations can help in those scenarios.
Manual reboot
You might need to reboot your DB cluster or some instances within the cluster, usually for maintenance reasons. A manual reboot may also be required to synchronize any modifications when changes are made to static parameters in the custom parameter group attached to your Aurora database. Rebooting a DB instance restarts the database engine process and results in a momentary outage. With the new optimizations, these restart times are minimized.
Failover
If your Aurora cluster consists of one or more replicas, then in case of issues with the primary writer instance, Aurora initiates a failover for one of the reader instances to take over as the primary instance. Typically, failovers in Aurora complete within 30 seconds. This time can be further reduced by employing Amazon RDS Proxy or using the AWS JDBC Driver for MySQL. In case of an automatic or manual failover, a database restart is performed which is improved by the new Aurora MySQL optimizations, thereby reducing the overall downtime. Additionally, from our testing, in some cases, these optimizations can also help prevent failovers as the instance restarts become much quicker than before. As a best practice, test and review your existing failover management practices with the new optimizations to observe how your applications reconnect after a disruption.
Minor version and patch upgrades
As a best practice, we recommend staying up to date on the latest minor versions and patches within a minor version posted in the Aurora MySQL release notes as they include new features and additional security and stability fixes. These upgrades result in a period of instance unavailability as the instances in the cluster get upgraded at the same time. With the new Aurora MySQL optimizations, the downtime during minor and patch upgrades will reduce.
Underlying operating system patch or hardware fault
Your Aurora instances may need to be taken offline if there is an underlying operating system patch to be applied for security issues or if the underlying instance of your database has failures and requires a host replacement. In this case, an unexpected failover may be triggered as discussed earlier and these optimizations reduce the disruption caused due to these actions.
Database engine restart
In some cases, an instance may restart due to various issues such as out of memory conditions and higher replication lag issues. In this case, existing user connections are dropped for the duration of the restart. Aurora MySQL optimizations will reduce the overall downtime in these scenarios as well; however, some exclusions may apply (as covered in the next section).
Key considerations
As of the writing of this blog post, these Aurora MySQL enhancements are available and enabled by default for customers on Aurora MySQL version 3.05 and higher. If you are on a previous version of Aurora MySQL 3, you can perform a minor version upgrade to get to the latest version.
Currently, the reduction to overall restart times with these optimizations are a result of deferring some portions of buffer pool validation to happen after the database is online. These improvements are much more evident on larger instance classes, which consequently have larger buffer pools, such as db.8xlarge, db.12xlarge, db.16xlarge, db.24xlarge. With these optimizations, as the priority is to bring the database online quicker, in some cases, there may be a few seconds of performance impact while the buffer pool validation is happening in the background as connections are being made to the database after a restart.
With several components coming into play at the time of the database restart, these optimizations are directed to reduce the buffer pool validation time and thereby speed up the overall restart times. However, there are several steps performed in the background to maintain transaction consistency and overall database stability as the database is restarting. The times to recover are mostly dynamic due to multiple steps that need to be performed before allowing user connections. Some of the variable factors impacting the restart include cases where you have binary logs enabled and the database is in the middle of a large transaction, which can lead to more data being written in the binary logs and can result in an inconsistent longer binlog recovery. Similarly, another factor is tablespace discovery which can occur if the database has thousands to millions of tables. While these factors will not play a role in most scenarios, in some edge cases they can lead to a few additional seconds of downtime before the database is available for connections. The current design of these optimizations doesn’t improve the time it takes for the database to perform additional recovery steps that are a part of the restart process.
Conclusion
In this post, we explored the new Aurora MySQL optimizations and their benefits. These optimizations provide a lower overall downtime for your workloads when performing planned actions that require a database restart or during unexpected periods of unavailability that involve a database restart. These enhancements are available by default in Aurora MySQL version 3.05 and higher, and no action is required in order to use them.
Get started with Aurora today!
About the Author
 Shagun Arora is a Database Specialist Solutions Architect at Amazon Web Services. She works with customers to design scalable, highly available and secure solutions in the AWS Cloud.
Shagun Arora is a Database Specialist Solutions Architect at Amazon Web Services. She works with customers to design scalable, highly available and secure solutions in the AWS Cloud.