AWS DevOps & Developer Productivity Blog
Transforming DevOps at Broadridge on AWS
with Tom Koukourdelis (Broadridge – Vice President, Head of Global Cloud Platform Development and Engineering), Sreedhar Reddy (Broadridge – Vice President, Enterprise Cloud Architecture)
We have seen large enterprises in all industry segments meaningfully utilizing AWS to build new capabilities and deliver business value. While doing so, enterprises have to balance existing systems, processes, tools, and culture while innovating at pace with industry disruptors. Broadridge Financial Solutions, Inc. (NYSE: BR) is no exception. Broadridge is a $4 billion global FinTech leader and a leading provider of investor communications and technology-driven solutions to banks, broker-dealers, asset and wealth managers, and corporate issuers.
This blog post explores how we adopted AWS at scale while being secured and compliant, as well as delivering a high degree of productivity for our builders on AWS. It also describes the steps we took to create technical (a cloud solution as a foundation based on AWS) and procedural (organizational) capabilities by leveraging AWS cloud adoption constructs. The improvement in our builder productivity and agility directly contributes to rolling out differentiated business capabilities addressing our customer needs in a timely manner. In this post, we share real-life learnings and takeaways to adopt AWS at scale, transform business and application team experiences, and deliver customer delight.
Background
At Broadridge we have number of distributed and mainframe systems supporting multiple financial services domains and sub-domains such as post trade, proxy communications, financial and regulatory reporting, portfolio management, and financial operations. The majority of these systems were built and deployed years ago at on-premises data centers all over the US and abroad.
Builder personas at Broadridge are diverse in terms of location, culture, and the technology stack they use to build and support applications (we use a number of front-end JS frameworks; .NET; Java; ColdFusion for web development; ORMs for data entity relational mapping; IBM MQ; Apache Camel for messaging; databases like SQL, Oracle, Sybase, and other open source stacks for transaction management; databases, and batch processing on virtualized and bare metal instances). With more than 200 on-premises distributed applications and mainframe systems across front-, mid-, and back-office ecosystems, we wanted to leverage AWS to improve efficiency and build agility, and to reduce costs. The ability to reach customers at new geographies, reduced time to market, and opportunities to build new business competencies were key parameters as well.
Broadridge’s core tenents for cloud adoption
When AWS adoption within Broadridge attained a critical mass (known as the Foundation stage of adoption), the business and technology leadership teams defined our posture of cloud adoption and shared them with teams across the organization using the following tenets. Enterprises looking to adopt AWS at scale should define similar tenets fit for their organizations in plain language understandable by everyone across the board.
- Iterate: Understanding that we cannot disrupt ongoing initiatives, small and iterative approach of moving workloads to cloud in waves— rinse and repeat— was to be adopted. Staying away from long-drawn, capital-intensive big bangs were to be avoided.
- Fully automate: Starting from infrastructure deployment to application build, test, and release, we decided early on that automation and no-touch deployment are the right approach both to leverage cloud capabilities and to fuel a shift toward a matured DevOps culture.
- Trust but verify only exceptions: Security and regulatory compliance are paramount for an organization like Broadridge. Guardrails (such as service control policies, managed AWS Config rules, multi-account strategy) and controls (such as PCI, NIST control frameworks) are iteratively developed to baseline every AWS account and AWS resource deployed. Manual security verification of workloads isn’t needed unless an exception is raised. Defense in depth (distancing attack surface from sensitive data and resources using multi-layered security) strategies were to be applied.
- Go fast; re-hosting is acceptable: Not every workload needs to go through years of rewriting and refactoring before it is deemed suitable for the cloud. Minor tweaking (light touch re-platforming) to go fast (such as on-premises Oracle to RDS for Oracle) is acceptable.
- Timeliness and small wins are key: Organizations spend large sums of capital to completely rewrite applications and by the time they are done, the business goal and customer expectation will have changed. That leads to material dissatisfaction with customers. We wanted to avoid that by setting small, measurable targets.
- Cloud fluency: Investment in training and upskilling builders and leaders across the organization (developers, infra-ops, sec-ops, managers, salesforce, HR, and executive leadership) were to be to made to build fluency on the cloud.
The first milestone
The first milestone in our adoption journey was synonymous with Project stage of adoption and had the following characteristics.
A controlled sprawl of shadow IT
We first gave small teams with little to no exposure to critical business functions (such as customer data and SLA-oriented workloads) sandboxes to test out proofs of concepts (PoC) on AWS. We created the cloud sandboxes with least privilege, and added additional privileges upon request after verification. During this time, our key AWS usage characteristics were:
- Manual AWS account setup with least privilege
- Manual IAM role creation with role boundaries and authentication and authorization from the existing enterprise Active Directory
- Integration with existing Security Information and Event Management (SIEM) tools to audit role sprawl and config changes
- Proofs of concepts only
- Account tagging for chargeback and tracking purposes
- No automated build, test, deploy, or integration with existing delivery pipeline
- Small and definitive timeframes for PoCs with defined goals
A typical AWS environment at this stage will resemble that shown in the following diagram:

As shown above, at this time the corporate assets were connected to a highly restrictive AWS environment through VPN. The access to the AWS environment were setup based on AWS Identity primitives or IAM roles mapped to and federated with the on-premises Active Directory. There was a single VPC setup for a sandbox account with no egress to the internet. There were no customer data hosted on this AWS environment and the AWS environment was connected with our SIEM of choice.
Early adopters became first educators and mentors
Members of the first teams to carry out proofs of concept on AWS shared learnings with each other and with the leadership team within Broadridge. This helped build communities of practices (CoPs) over time. Initial CoPs established were for networking and security, and were later extended to various practices like Terraform, Chef, and Jenkins.
Tech PMO team within Broadridge as the quasi-central cloud team
Ownership is vital no matter how small the effort and insignificant the impact of risky experimentation. The ownership of account setup, role creation, integration with on-premises AD and SIEM, and oversight to ensure that the experimentation does not pose any risk to the brand led us to build a central cloud team with experienced AWS and infrastructure practitioners. This team created a process for cloud migration with first manual guardrails of allowed and disallowed actions, manual interventions, and checkpoints built in every step.
At this stage, a representative pattern of work products across teams resembles what is shown below.
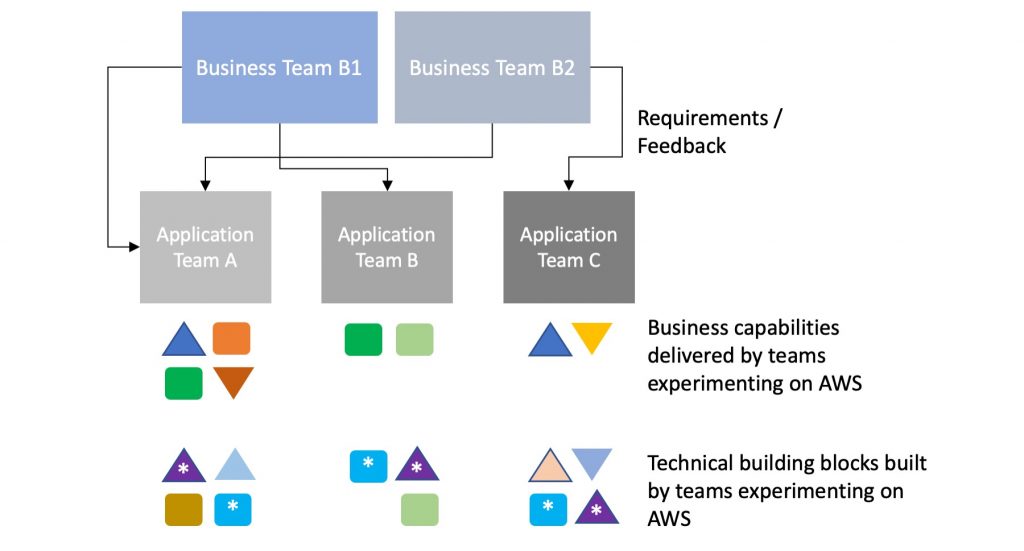
As the diagram suggests, individual application teams built overlapping—and, in many cases, identical—technical building blocks across the teams. This was acceptable as the teams were experimenting and running PoCs on AWS. In an actual production application delivery, the blocks marked with a * would be considered technical and functional waste—that is, undifferentiated lift which increases the cost of doing business.
The second milestone
In hindsight, this is perhaps the most important milestone in our cloud adoption journey. This step was marked with following key characteristics:
- Every new team doing PoCs are rebuilding the same building blocks: This includes networking (VPCs and security groups), identity primitives (account, roles, and policies), monitoring (Amazon CloudWatch setup and custom metrics), and compute (images with org-mandated security patches).
- The teams usually asking the same first fundamental questions: These include questions such as: What is an ideal CIDR block range? How do we integrate with SIEM? How do we spin up web servers on Amazon EC2? How do we secure access to data? How do we setup workload monitoring?
- Security reviews rarely finding new security gaps but adding time to the process: A central security group as part of the central cloud team reviewed every new account request and every new service usage request without finding new security gaps when the application team used the baseline guardrails.
- Manual effort is spent on tagging, chargeback, and other approvals: A portion of the application PoC/minimum viable product (MVP) lifecycle was spent on housekeeping. While housekeeping was necessary, the effort spent was undifferentiated.
The follow diagram represents the efforts for every team during the first phase.
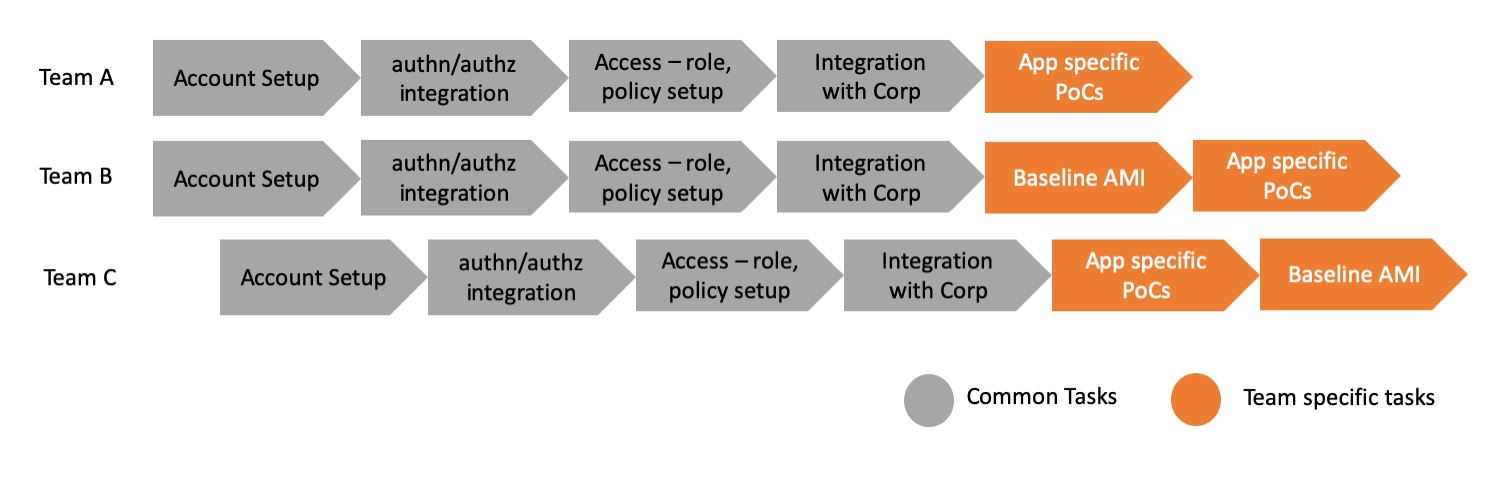
As shown above, every application team spent effort on building nearly the same capabilities before they could begin developing their team specific application functionalities and assets. The common blocks of work are undifferentiated and leads to spending effort which also varies depending on the efficiency of the team.
During this step, learnings from the PoCs led us to establish the tenets shared earlier in this post. To address the learnings, Broadridge established a cloud platform team. The cloud platform team, also referred to as the cloud enablement engine (CEE), is a team of builders who create the foundational building blocks on AWS that address common infrastructure, security, monitoring, auditing, and break-glass controls. At the same time, we established a cloud business office (CBO) as a liaison between the application and business teams and the CEE. CBO exists to manage and prioritize foundational requirements from multiple application teams as they go online on AWS and helps create the product backlog for CEE.
Cloud Enablement Engine Responsibilities:
- Build out foundational building blocks utilizing AWS multi-account strategy
- Build security guardrails, compliance controls, infrastructure as code automation, auditing and monitoring controls
- Implement cloud platform backlog that funnel from CBO as common asks from app teams
- Work with our AWS team to understand service roadmap, future releases, and provide feedback
Cloud Business Office Responsibilities:
- Identify and prioritize repeating technical building blocks that cuts across multiple teams
- Establish acceptable architecture patterns based on application use cases
- Manage cloud programs to ensure CEE deliverables and business expectations align
- Identify skilling needs, budget, and track spend
- Contribute to the cloud platform backlog
- Work with AWS team to understand service roadmap, future releases, and provide feedback
These teams were set up to scale AWS adoption, put building blocks into the hands of the applications teams, and ultimately deliver differentiated capabilities to Broadridge’s business teams and end customers. The following diagram translates the relationship and modus operandi among the teams:
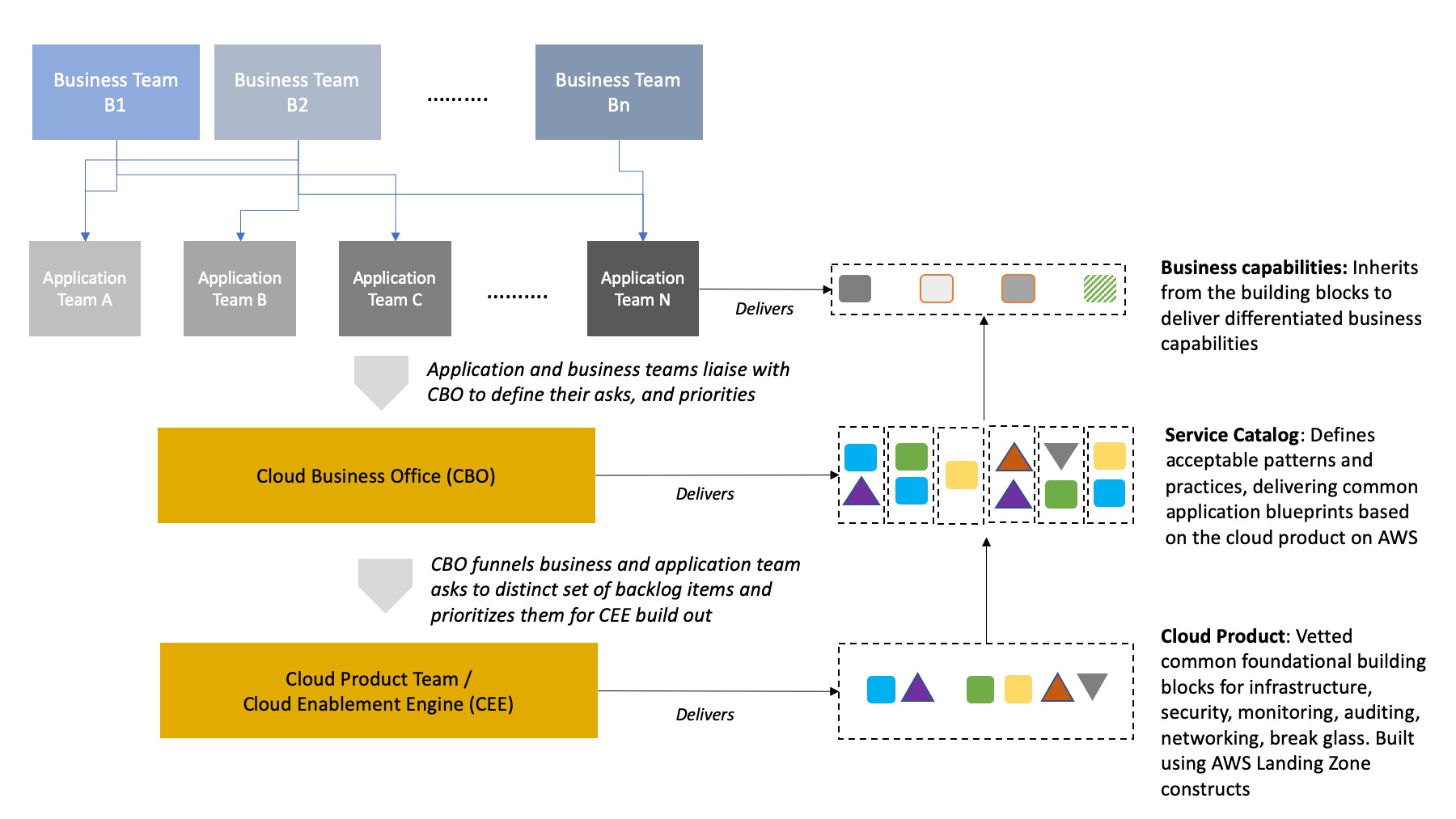
Upon establishing the conceptual working model, the CBO and CEE teams looked at solutions from AWS to enable them to achieve the working model quickly. The starting point was AWS Landing Zone (ALZ). ALZ is an AWS solution based on the AWS multi-account strategy. It is a set of vetted constructs and best practices that we use as mechanisms to accelerate AWS adoption.
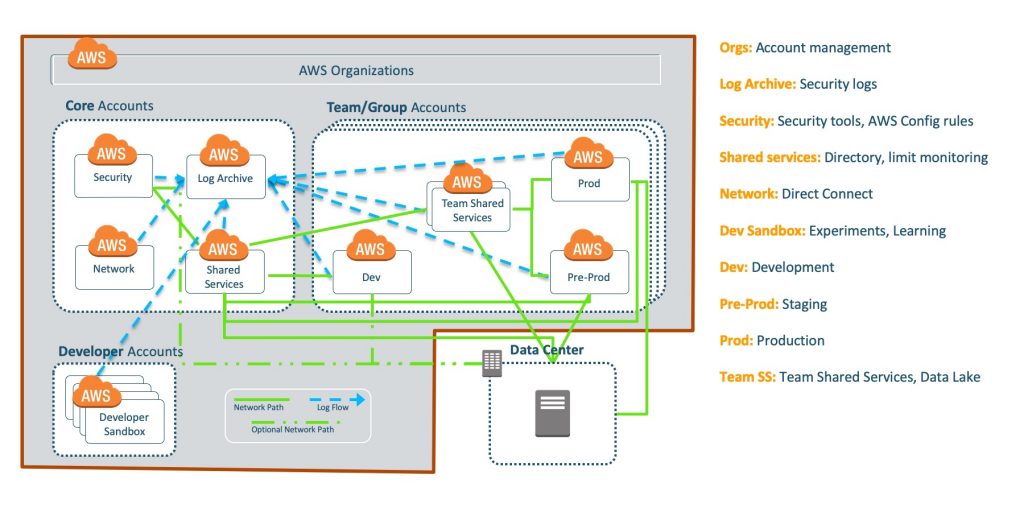
The multi-account strategy employs best practices around separation of concerns, reduction of blast radius, account setup based on Software Development Life Cycle (SDLC) phases, and base operational roles for auditing, monitoring, security, and compliance, as shown in the above diagram. This strategy defines the need for having centralized shared or core accounts, which works as the master account for monitoring, governance, security, and auditing. A number of AWS services like Amazon GuardDuty, AWS Security Hub, and AWS Config configurations are set in these centralized accounts. Spoke or child accounts are vended as per a team’s requirement which are spun up with these governance, monitoring, and security defaults connected to the centralized account for log capturing, threat detection, configuration management, and security management.
The third milestone
The third milestone is synonymous with the Foundation stage of adoption
Using the ALZ construct, our CEE team developed a core set of principles to be used by every application team. Based on our core tenets, the CEE team built out an entry point (a web-based UI workflow application). This web UI was the entry point for any application team requesting an environment within AWS for experimentation or to begin the application development life cycle. Simplistically, the web UI sat on top of an automation engine built using APIs from AWS, ALZ components (Account Vending Machine, Shared Services Account, Logging Account, Security Account, default security groups, default IAM roles, and AD groups), and Terraform based code. The CBO team helped establish the common architecture patterns that was codified into this engine.

An Angular based web UI is the starting point for application team to request for the AWS accounts. The web UI entry point asks a number of questions validating the type of account requested along with its intended purpose, ingress/egress requirements, high availability and disaster recovery requirements, business unit for charge back and ownership purposes. Once all information is entered, it sends out a notification based on a preset organization dispatch matrix rule. Upon receiving the request, the approver has the option to approve it or asks further clarification question. Once satisfactorily answered the approver approves the account vending request and a Terraform code is kicked in to create the default account.
When an account is created through this process, the following defaults are set up for a secure environment for development, testing, and staging. Similar guardrails are deployed in the production accounts as well.
- Creates a new account under an existing AWS Organizational Unit (OU) based on the input parameters. Tags the chargeback codes, custom tags, and also integrates the resources with existing CMDB
- Connects the new account to the master shared services and logging account as per the AWS Landing Zone constructs
- Integrates with the CloudWatch event bus as a sender account
- Runs
stsAssumeRolecommands on the new account to create infosec cross-account roles - Defines actions, conditions, role limits, and account policies
- Creates environment variables related to the account in the parameter store within AWS Systems Manager
- Connects the new account to TrendMicro for AV purposes
- Attaches the default VPC of the new account to an existing AWS Transit Gateway
- Generates a Splunk key for the account to store in the Splunk KV store
- Uses AWS APIs to attach Enterprise support to the new account
- Creates or amends a new AD group based on the IAM role
- Integrates as an Amazon Macie member account
- Enables AWS Security Hub for the account by running an
enable-security-hubcall - Sets up Chef runner for the new account
- Runs account setting lock procedures to set Amazon S3 public settings, EBS default encryption setting
- Enable firewall by setting AWS WAF rules for the account
- Integrates the newly created account with CloudHealth and Dome9
Deploying all these guardrails in any new accounts removes the need for manual setup and intervention. This gives application developers the needed freedom to stop worrying about infrastructure and access provisioning while giving them a higher speed to value.
Using these technical and procedural cloud adoption constructs, we have been able to reduce application onboarding time. This has led to quicker delivery of business capability with the application teams focusing only on what differentiates their business rather than repeatedly building undifferentiated work products. This has also led to creation of mature building blocks over time for use of the application teams. Using these building blocks the teams are also modernizing applications by iteratively replacing old application blocks.
Conclusion
In summary, we are able to deliver better business outcomes and differentiated customer experience by:
- Building common asks as reusable and automated enterprise assets and improving the overall enterprise-wide maturity by indexing on and growing these assets.
- Depending on an experienced team to deliver baseline operational controls and guardrails.
- Improving their security posture with higher-level and managed AWS security services instead of rebuilding everything from the ground up.
- Using the Cloud Business Office to improve funneling of common asks. This helps the next team on AWS to benefit from a readily available set of approved services and application blueprints.
We will continue to build on and maturing these reusable building blocks by using AWS services and new feature releases.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.