AWS HPC Blog
Checkpointing HPC applications using the Spot Instance two-minute notification from Amazon EC2
Amazon Elastic Compute Cloud (Amazon EC2) offers a wide-range of compute instances at different price points, all designed to match different customer’s needs. You can further optimize cost by choosing Reserved Instances (RIs) and even Spot Instances.
Amazon EC2 offers Spot Instances at up to 90% discount compared to on-demand instance prices, making them attractive to HPC customers. However, they can be reclaimed by Amazon EC2 with a two-minute warning. For an application to effectively use spot, it must have some resiliency to failure.
Checkpoint-restart is a defense mechanism for an application to save a known good (execution) state, and later resume execution from that point.
In this blog post, we will discuss the use of AWS ParallelCluster configuration for creating an HPC cluster on AWS, and Amazon EventBridge to capture the two-minute warning notification to execute checkpoint code on a Spot Instance reclaim. We’ll use Gadget-4, a cosmological N-body, SPH code for demonstrating the methodology.
Installing an HPC cluster using AWS ParallelCluster
The listing that follows shows a ParallelCluster configuration file for deploying an HPC cluster. The head-node is a t2.micro instance and the compute nodes are c5n.2xlarge instances. The cluster size auto-scales from 0 (min) to 16 (max) instances. We disabled simultaneous multithreading on the compute nodes, and allow access to an Amazon S3 bucket. We enabled cluster placement groups for our compute fleet, to take advantage of EFA.
We also used some additional services:
- Amazon FSx for Lustre – a parallel file system mounted on
/lustreand synchronized with an Amazon S3 bucket. - An AWS Identity and Access Management (IAM) policy
AmazonSSMManagedInstanceCorefor AWS Systems Manager (SSM) - Capacity type for requesting the instances:
SPOT
The OnNodeConfigured configuration script will install our application’s dependency packages on the compute instances during start-up, too.
Region: us-east-1
Image:
Os: alinux2
HeadNode:
InstanceType: t2.micro
Networking:
SubnetId: subnet-xxxxxxxxxx
Ssh:
KeyName: keyPairFile
Imds:
ImdsSupport: v2.0
Iam:
AdditionalIamPolicies:
- Policy: arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
Scheduling:
Scheduler: slurm
SlurmQueues:
- Name: compute
ComputeResources:
- Name: c5n2xlarge
InstanceType: c5n.2xlarge
MinCount: 0
MaxCount: 16
DisableSimultaneousMultithreading: true
Efa:
Enabled: true
CapacityType: SPOT
Iam:
S3Access:
- BucketName: s3_bucket_name
CustomActions:
OnNodeConfigured:
Script: s3://s3_bucket_name/on-node-configured.sh
Networking:
SubnetIds:
- subnet-xxxxxxxxxx
PlacementGroup:
Enabled: true
Walkthrough of Gadget-4 HPC application checkpoint code
Download and install Gadget-4 application (for example with GNU C++ compiler, and the Open MPI library provided with ParallelCluster). For better I/O performance, install the code into /lustre.
Gadget-4 has code/mechanism for checkpointing and restart:
- It uses a stop file to end a simulation.
- It writes restart files on stop file presence or periodic interval or at the end of a simulation.
- It can restart the run from a previous checkpoint (if it’s clean), or otherwise start from beginning.
We’re going to show you how the stop file mechanism can be used to gracefully end the simulation with checkpointing when the Amazon EC2 Spot two-minute warning is issued.
Here’s a snippet of the Gadget-4 code. The checkpointing logic is at the beginning or at the end of every timestep where it checks for a stop file, which forces the code to checkpoint and exit gracefully. The simulation begins with Sim.run() being invoked from the C++ main(). Before main() returns, Sim.endrun() does clean-up and calls MPI_Finalize().
/*!
* This function initializes the MPI communication packages, and sets
* cpu-time counters to 0. Then begrun1() is called, which sets up
* the simulation. Then either IC's or restart files are loaded. In
* case of IC's init() is called which prepares the IC's for the run.
* A call to begrun2() finishes the initialization. Finally, run() is
* started, the main simulation loop, which iterates over the timesteps.
*/
int main(int argc, char **argv)
{
...
Sim.begrun2();
Sim.run(); /* main simulation loop */
Sim.endrun(); /* clean up & finalize MPI */
return 0;
}
The sim::run() method executes the Gadget-4 application code (a timestep simulation) and at every timestep it checks for any interruption by calling check_for_interruption_of_run().
/*!
* Main driver routine for advancing the simulation forward in time.
* The loop terminates when the cpu-time limit is reached, when a `stop' file
* is found in the output directory, or when the simulation ends because we
* arrived at TimeMax.
*
* If the simulation is started from initial conditions, an initial domain
* decomposition is performed, the gravitational forces are computed and
* initial hydro forces are calculated.
*/
void sim::run(void)
{
...
/* Check whether we should write a restart file */
if(check_for_interruption_of_run())
return;
...
}
The code flow does various checks to stop the simulation, writes restart files or continues from an earlier checkpoint state. This code checks for a stop file and then writes the restart files.
/*! \brief checks whether the run must interrupted
*
* The run is interrupted either if the stop file is present or,
* if 85% of the CPU time are up. This routine also handles the
* regular writing of restart files. The restart file is also
* written if the restart file is present
*
* \return 1 if the run has to be interrupted, 0 otherwise
*/
int sim::check_for_interruption_of_run(void)
{
/* Check whether we need to interrupt the run */
int stopflag = 0;
if(ThisTask == 0)
{
FILE *fd;
char stopfname[MAXLEN_PATH_EXTRA];
sprintf(stopfname, "%sstop", All.OutputDir);
if((fd = fopen(stopfname, "r"))) /* Is the stop-file present? If yes, interrupt the run. */
{
...
restart Restart{Communicator};
Restart.write(this); /* write restart file */
MPI_Barrier(Communicator);
...
}
Using Amazon EventBridge: Checkpointing Gadget-4 on Amazon EC2 Spot Instances
Amazon EC2 reclaims spot instances with a two-minute warning notification – and we can capture this as an event in Amazon EventBridge. For checkpointing of our HPC application, we’ll use this event as a trigger. The following screenshots (Figures 1-5) describe an EventBridge configuration for capturing the two-minute warning event.
Step 1: Create a rule with basic details such as Name (spot2minTermRule), Event bus, Rule type…
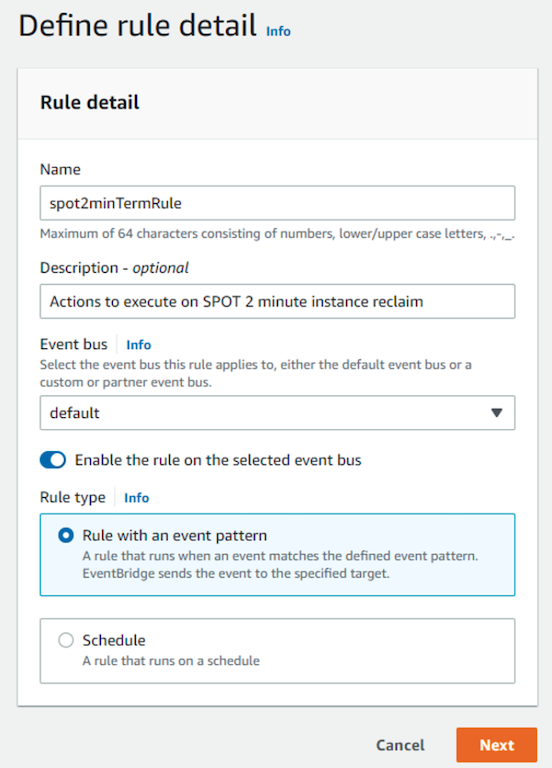
Figure 1: Define an event rule, give it a name, specify rule type.
Step 2: Choose the event pattern. Here we are picking an event pattern from an AWS service.
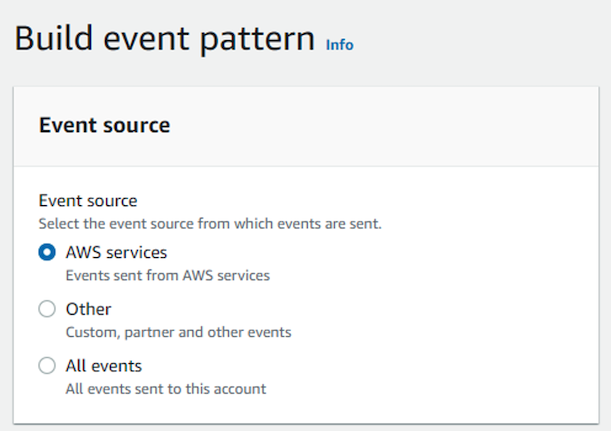
Figure 2: Select the source for the event being created.
Specifically, select the event pattern of interest to us: EC2 Spot Instance Interruption Warning.
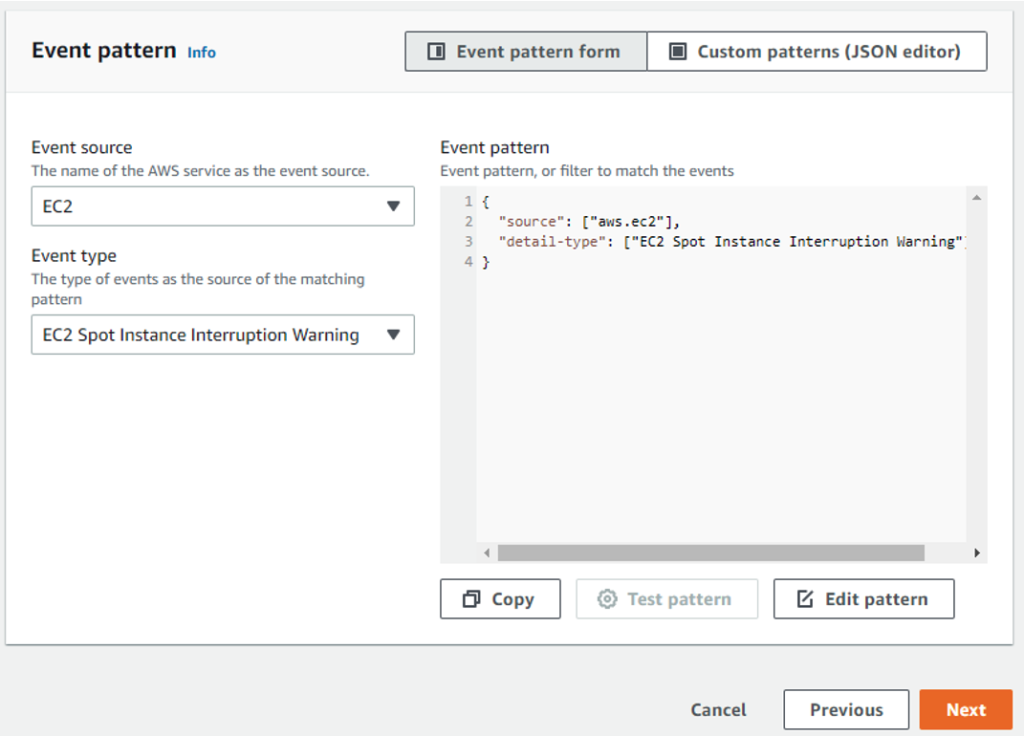
Figure 3: Specify the event pattern… here it is ‘EC2 instance termination warning’ event.
Step 3: Select target and actions to trigger on the event notification.
In this step, you select the target on which some actions are to be performed on an event issued by EventBridge. For our checkpointing use case, we’ll select the target as an AWS service on which an SSM (AWS Systems Manager) run command is executed as a shell script. The target is identified by a key-pair value which in this case is the InstanceId of the head-node of the Gadget-4 HPC cluster.
The shell script (SSM run command) for checkpointing Gadget-4 writes the stop file. You can accomplish these tasks using an IAM role with the appropriate permissions (create a new role or use existing). For this demo, we created and added an IAM policy: AmazonSSMManagedInstanceCore to the head node instance for executing SSM commands.
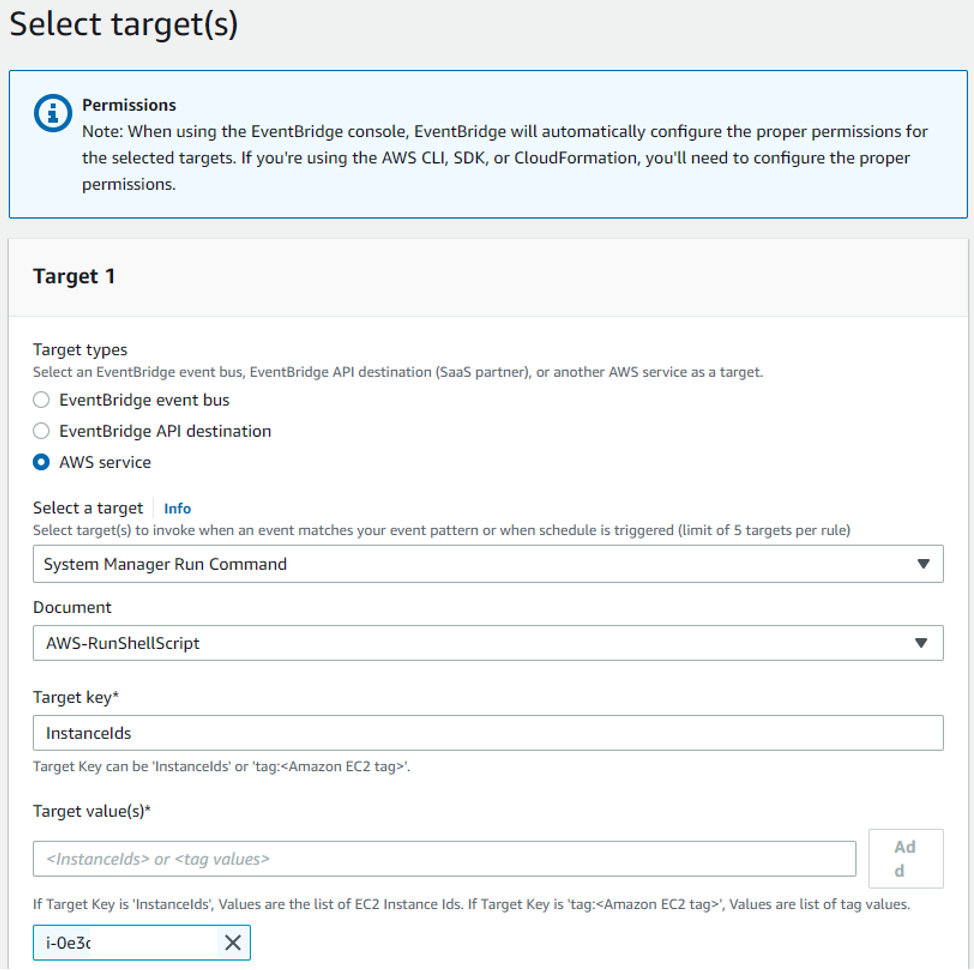
Figure 4: Select a target on which the event rule must be executed. In this case, ‘i-0e3…’
Figure 5: Specify the commands to execute on the target and set permissions using an IAM role.
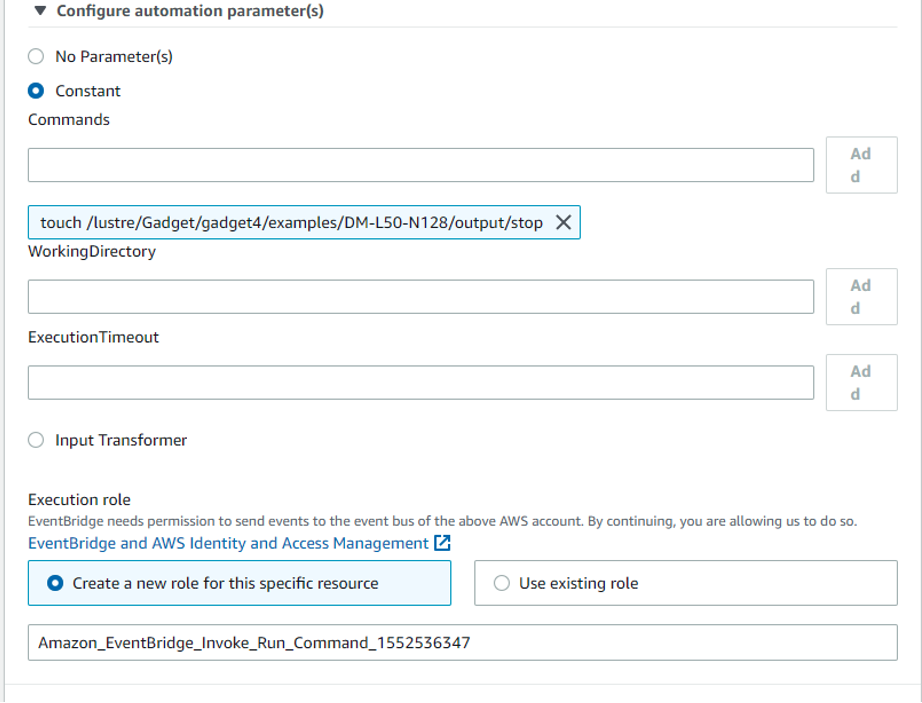
Figure 5: Specify the commands to execute on the target and set permissions using an IAM role.
Steps 4 and 5: Create tags (optional), review the event rule details and create the rule.
Once created, the event rule will be triggered and executed on the specified target.
Setting the wheels in motion
Now that we’ve setup the HPC cluster using AWS ParallelCluster, and have an AWS EventBridge rule with the appropriate permissions and actions, it’s time to test it out!
To simulate reclamation of a Spot Instance in Amazon EC2, we’ll use the AWS Fault Injection Simulator (FIS) tool. Using FIS, Amazon EC2 will reclaim one or more Spot Instances and will raise an EC2 Spot Instance interruption warning event with EventBridge. After that, the event rule spot2minTermRule executes, which creates a stop file in the Gadget-4 output folder to terminate the run with checkpointing.
Figure 6 shows the time taken for creating Gadget-4 restart files on a Lustre parallel filesystem.
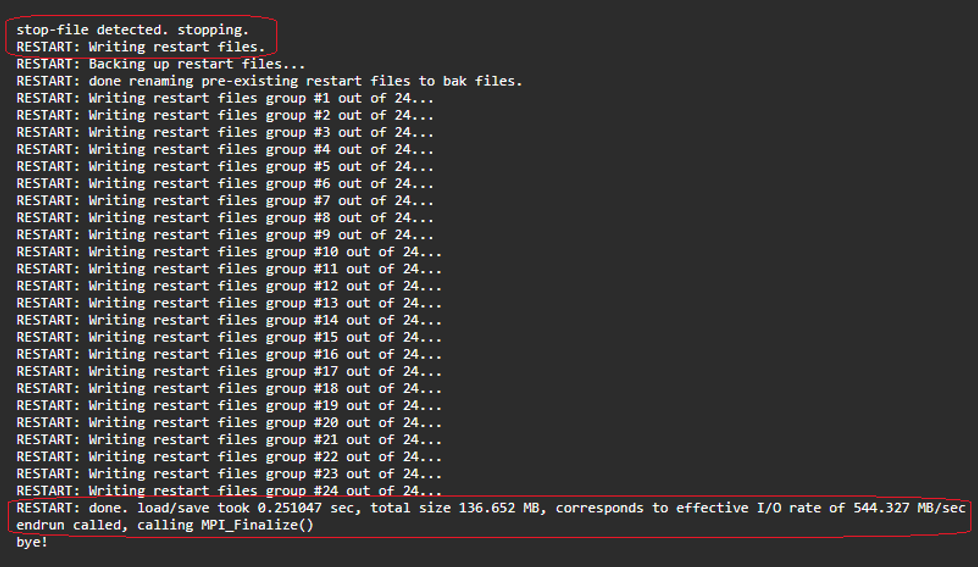
Figure 6: stop-file usage to end Gadget-4 simulation and successfully writing the restart files.
An important point to note is the time required to write the restart files. The snapshot in Figure 6 is for a small workload run on 8 instances of c5n.2xlarge (with 3 MPI ranks per instance participating in the compute and 1 MPI rank doing file I/O). The time for restart file I/O write is ~0.3s (with all MPI ranks writing their restart files to a high-throughput Lustre parallel filesystem simultaneously).
For many situations you might face, this is a practical and useful method for achieving checkpoints (and, later, restarts) for your code. To apply it to your site, you’ll need to adapt it for your specific application.
Some limitations to this checkpointing approach
The approach we’ve just showed you is novel and we make use of the two-minute warning notification of an EC2 Spot Instance reclaim for checkpoint and restart of an HPC simulation. There’s a risk that for larger workloads, this two-minute warning might be too short to create a complete checkpoint.
The time to checkpoint is bounded by the sum of [time to execute one timestep] and [time to write restart files]. Table 1 shows some timing data for a Gadget-4 workload with different grid sizes (small: 128, medium: 256, large: 512) executed on a combination of instance sizes and MPI ranks. For some of these run configurations, checkpoint on a spot instance reclaim wouldn’t succeed.
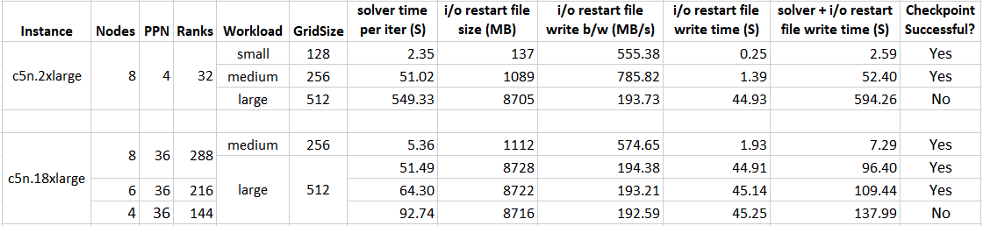
Table 1: For some problem sizes, checkpointing will not complete before spot instance reclaim.
Finally, there’s a limitation in our mechanism because we used the EC2 Spot Instance Interruption Warning event without filtering. Any Spot Instance termination in your account in the same region could be a source of an event, and thus cause the termination of your HPC job.
That means the EventBridge rule is too generic and ultimately needs a more selective filter. In a future post, we’ll tackle this aspect. But – for now – we think the method we showed here is a great proof of concept for a more general case, and could work well for many customers who are running large single-job workloads.
Conclusion: Design choices for checkpointing HPC apps on AWS
Checkpointing-restart is a design choice when writing HPC applications. However, it can unlock the ability to use a greater range of resources, like Amazon EC2 Spot Instances.
From our experience, there are some key design considerations for implementing a checkpoint mechanism in this context:
Use a high throughput parallel file system: For application checkpointing to complete within the two-minute warning of an EC2 instance reclaim, a parallel file system like Amazon FSx for Lustre helps a lot. It doesn’t guarantee a successful checkpoint, but it improves the likelihood compared to other, slower, filesystems which might not allow you to capture all the checkpoint data in time.
Provisioning necessary IAM permissions: On AWS, fine-grained controls in IAM let you grant or revoke permissions for accessing services and resources. You’ll most likely need to create these IAM permissions during setup of the HPC cluster and the event rules in EventBridge.
Application coding requirements: Your application must support checkpointing logic. That means:
- Having restart files written by all MPI ranks (in parallel).
- Initiating the checkpointing task using simple mechanisms like the stop file that Gadget-4 uses.
- Restarting from a clean checkpoint state or time-step 0.
Experimenting and fine-tuning: You may find that the checkpointing workflow doesn’t work first time. That means experimenting to determine the best mechanism. You can fine-tune several variables: the size of restart files your application writes, or the state captured. You can experiment by using a local EBS volume instead of a parallel file system. And you can tweak the number of MPI ranks (and instances) for a given problem size to find a configuration for which checkpointing succeeds within the two-minute notification window.
We’d love to hear from you if you deploy this method, to hear how you’ve refined it for your needs. You can send us feedback at ask-hpc@amazon.com.