AWS for Industries
How Financial Institutions can Select the Appropriate Controls to Protect Sensitive Data
In a previous blog post, we discussed how financial institutions can approve AWS services for highly confidential data. One of the questions we hear from customers is: What are the recommended patterns for data protection of highly confidential data? Many financial services institutions have existing data classification and handling policies that dictate the required encryption for each classification level. Because such policies are often overly prescriptive, based on on-premises data protection capabilities, some customers need to go through prolonged risk acceptance processes to get approval to protect data in the cloud in a way that is different from (but not less secure than) what their on-premises-centric policies may state. Other customers decide to revisit their existing data classification policies and adapt it for cloud. Our CISO, Stephen Schmidt, recommends using intentional data policies in his top 10 most important cloud security tips. Intentional data policies take into consideration the fact that data comes in various degrees of sensitivity, and you might have data that falls in all of the different levels of sensitivity and confidentiality. Because of this, intentional data policies focus on an appropriate mix of preventative and detective controls to match data sensitivity appropriately.
Irrespective of your data classification policies, the purpose of this blog post is to provide a recommended, repeatable approach that you can use to select the appropriate data protection controls for your use case. The approach and considerations discussed in this blog have been developed based on collective experiences from our financial services customers when working with sensitive data on AWS. In order to help you understand how this guidance can apply to a specific use case, we will walk you through a customer’s journey of determining the appropriate mechanisms to properly protect their highly confidential data. Let’s begin by discussing an example customer’s high-level workload and data handling requirements.
A financial service customer’s data science team needed to leverage datasets with varying degrees of sensitivity, including highly confidential data, in order to train machine learning models. Amazon S3 and AWS Key Management Service were reviewed and approved for data storage with server-side encryption. As part of the machine learning workflow, the data scientists also needed to label these datasets using Amazon SageMaker Ground Truth, a managed service enabling human and automated labeling capabilities. Because data had to be moved across multiple internal systems before being stored in Amazon S3 and it would be accessed by human labelers with no authorization to share data, the customer’s data handling policy required the data to be also client-side encrypted as an additional layer of protection. The customer needed to enable Ground Truth and provide human labelers access to these encrypted datasets, while mitigating risk associated with users other than authorized labelers having access to confidential data. The customer also wanted to ensure that the proposed solution would be cost effective, highly scalable, and minimize unnecessary data movement.
Throughout this blog, we will reference back to this use case as we provide guidance to help you understand how it was applied.
Getting Started with a Threat Model
In order to determine the most appropriate data protection method for your use case, we recommend starting with a threat model to clearly understand the risks and identify the specific threat scenarios that need to be addressed. Threat modeling provides a structured analysis of potential security failures and identifies mitigations to address them. You start by decomposing the workload and identifying all of the key assets that you are trying to protect. You then use an architecture diagram to identify data flow and trust boundaries. Once the workload is understood you focus on what could go wrong. You can use frameworks such as STRIDE to help identify specific threats such as spoofing, tampering, repudiation, information disclosure, denial of service, and elevation of privilege. After threat scenarios are identified, you define mitigations for each threat scenario along with a testing and validation strategy. We also recommend the output be used to maintain an up-to-date register of potential threats. Prioritize your threats and adapt your security controls to prevent, detect, and respond. Revisit and maintain this in the context of the evolving security landscape.
Tip: An effective first step when threat modeling is making sure all stakeholders involved have a clear understanding of the cloud shared responsibility model.
Let’s take a look back at the use case we described earlier and some of the threat scenarios identified when the threat model was performed:
- Threat 1: Unauthorized user may access sensitive data as it’s being processed by SageMaker Ground Truth as the data must be decrypted in order to be usable by the service.
- Threat 2: Unauthorized user may access sensitive unlabeled and labeled data in the S3 buckets.
- Threat 3: Human labelers may leak sensitive data as they require temporary visibility to clear-text data.
In addition to keeping the threat scenarios in mind when identifying the appropriate encryption and access controls, we also recommend keeping in mind your organization’s control objectives. A control objective addresses how risk is going to be effectively mitigated and it provides a specific target against which to evaluate the effectiveness of your controls. Reach out to your governance, risk, and compliance teams as they may already have control objectives documented based on your existing audits such as SOX and SOC 1 and/or alignment with industry standards.
A relevant example of a control objective is AWS Control Objective 4 included in the AWS SOC 1 Report: Controls provide reasonable assurance that data handling between the customer’s point of initiation to an AWS storage location is secured and mapped accurately. Your organization may have a similar control objective but adapted for your organization. And to address that control objective, the shared responsibility model will apply as you will rely on both the AWS controls in place as well as the data protection controls you choose to implement.
By using this approach, you are able to work backwards from both your company’s compliance objectives and the specific threats identified within your threat model to select the appropriate data protection controls including encryption. In the next section, we will review some of the AWS encryption capabilities and features available to customers.
Evaluate AWS Encryption Capabilities and Features
As you evaluate the following capabilities, keep in mind the shared responsibility model, and the threat scenarios and control objectives discussed previously to determine the appropriate encryption method best suited for your use case.
Server-side Encryption
For majority of AWS workloads, we recommend leveraging a given service’s server-side encryption capabilities runs on AWS KMS. AWS KMS allows customers to manage the lifecycle of encryption keys and control how they are used by their applications and AWS services. Allowing encryption keys to be generated and used in the FIPS 140-2 validated hardware security modules (HSMs) in AWS KMS is the best practice and most cost-effective option. The use of FIPS 140-2 validated modules as well as controls AWS KMS has in place to logically secure access to customer master keys (CMK) is verified by third-party auditors and can be assessed by customers within the AWS SOC reports.
For AWS customers who want added flexibility for key generation and storage, AWS KMS allows them to either import their own key material into AWS KMS and keep a copy in their on-premises HSM, or generate and store keys in dedicated AWS CloudHSM instances under their control. For each of these key material generation and storage options, you can control all the permissions to use keys from any of their applications or AWS services. In addition, every use of a key or modification to its policy is logged to AWS CloudTrail for auditing purposes; this logging is validated by third-party auditors within the AWS SOC reports. This level of control and audit over key management is one of the tools organizations can use to address regulatory requirements for using encryption as a data privacy mechanism.
There are several features and capabilities that make server-side encryption implementation with AWS KMS unique as compared to similar implementations on premises, which may explain why financial services customers chose this option for majority of workloads on AWS. Let’s review some of these unique capabilities.
Key Policies
Key policies are the primary way to control access to in AWS KMS. Each CMK has a key policy attached to it that defines permissions on the use and management of the key. To access an encrypted resource, the identity making the request (i.e., principal) needs to have permissions to both (1) access the encrypted resource, as well as (2) use the encryption key that protects the resource. If a principal does not have the necessary permissions for both of those actions, the request to use the encrypted resource or data will be denied. Unlike some on-premises implementations of server-side encryption, this two-level access control in AWS KMS greatly improves the intentionality and discretion of data access.
From within the key policy, you can choose to delegate permissions management to IAM policies in your account that refer specifically to the key as a resource condition. This capability enables you to incorporate the auditing of key-related permissions into the auditing of all the other IAM policies you already manage.
Least Privilege / Separation of Duties
Key policies and/or IAM policies also allow you to define granular permissions to CMKs to enforce the principle of least privilege. For example, you can allow an application within a data pipeline to encrypt sensitive data being ingested from a source system but not decrypt it. Additionally, AWS allows you to separate the usage permissions from administration permissions associated with the key. This means that a data scientist may have permissions to perform cryptographic functions but not manipulate the key policy, and similarly, a key admin can manage the key policy but not have the necessary permissions to use the key. KMS key policies provide the required flexibility to model permissions based on your operating model and enforce compliance with the principle of least privilege and separation of duties.
Key Grants
Key policies and/or IAM policies work best for relatively static assignments of permissions. For more granular programmatic permissions management, you can use grants. Grants are useful when you want to define scoped-down, temporary permissions for principals to use your CMK. With grants, you can set granular conditions (“constraints”) based on key encryption context metadata that must be included in both the encrypt and decrypt requests. You can also specify a specific principal that can “retire” the grant once the encrypted resource should no longer be able to be decrypted.
Network Controls
Applications within Amazon Virtual Private Cloud (Amazon VPC) or on-premises can connect directly to AWS KMS through a private VPC endpoint instead of connecting over the internet. VPC endpoints enable private connection between a customer’s VPC and AWS services using private IP addresses. Furthermore, when you create an endpoint, you can attach a policy that controls the use of the endpoint to access only specific AWS resources, such as specific KMS keys within your AWS account. Similarly, by using resource-based policies, customers can restrict access to their resources to only allow access from VPC endpoints. For example, within a KMS key or IAM policy, you can restrict access to a given CMK only through your VPC endpoint. You can similarly restrict access to a KMS key from within a specified IP range, such as on-premises data center. This ensures that any API request to use the CMK originates only from your network.
Client-side Encryption
In some cases, such as in our customer example discussed previously, you may have a requirement to encrypt the data using client-side encryption based on the data handling requirements or the application-specific threat model. Third-party technologies such as Transparent Data Encryption (TDE) from Microsoft or Oracle make it easy to achieve such requirements for relational databases such as Amazon RDS for SQL Server and Amazon RDS for Oracle. Similarly, services such as Amazon EMR natively support client-side encryption of data in Amazon S3. To assist with some client-side encryption use cases, AWS offers tools like the AWS Encryption SDK (ESDK) to simplify the application level encryption and decryption of data using whichever key management service you choose. AWS KMS can be used as the source of keys for client-side encryption use cases to simplify permissions management, but it is not required.
Selecting the Appropriate Data Protection Controls
Now that you have a deeper understanding of the available AWS encryption capabilities, you are well positioned to choose the data protection method that is best suited to address your threat scenarios and meet your control objectives. In our hypothetical customer example, the customer implemented multiple layers of data protection controls as part of a defense in depth strategy. First, all S3 buckets were configured with server-side encryption using a CMK. AWS KMS is seamlessly integrated with Amazon S3 and encryption with a CMK can be easily enforced at the bucket level with the Amazon S3 default encryption option.
Secondly, because some of the data was classified as highly confidential, the ingested unlabeled data was also client-side encrypted under a different CMK in AWS KMS to further protect against future configuration errors on the S3 bucket policies protecting the other data. The customer encountered a challenge when trying to make the client-side encrypted data available for use within SageMaker Ground Truth, as there was no way to configure SageMaker Ground Truth to recognize and decrypt the data it pulled from the customer’s bucket locally within the service. Realizing that in most managed systems you have to operate on clear-text data at some point, the goal was to minimize where and for how long unencrypted data exists. The customer addressed this requirement by creating an intermediary microservice in AWS Lambda that fetches client-side encrypted sensitive data from the source S3 bucket, decrypts it, and stores it in a temporary S3 bucket, which is server-side encrypted with CMKs that are different than the ones used by the source bucket. Human labelers could then access the data in that bucket via SageMaker Ground Truth because the AWS identities used by the service in the context of the human labelers had permissions to use the CMKs for decryption. After the labeling action was complete, dataset was then copied to the final S3 bucket using client-side encryption managed by a different Lambda function.
In addition to limiting the storage of highly confidential data with server-side encryption to a short time period in a temporary bucket, the customer also implemented a check to make sure that data in the temporary buckets (without client-side encryption) was purged upon job completion. Furthermore, no human access to these temporary buckets was granted; only the IAM role assumed after the labelers authenticated to the SageMaker Ground Truth service had the ability to access the bucket and use the bucket-specific CMK for decryption. The customer was able to create a cost-effective, event-driven architecture using AWS Lambda with just in time decryption/encryption capabilities. These controls allowed the customer to ensure that labeled sensitive data in the destination S3 bucket had the same security properties as unlabeled sensitive data in the source S3 bucket.
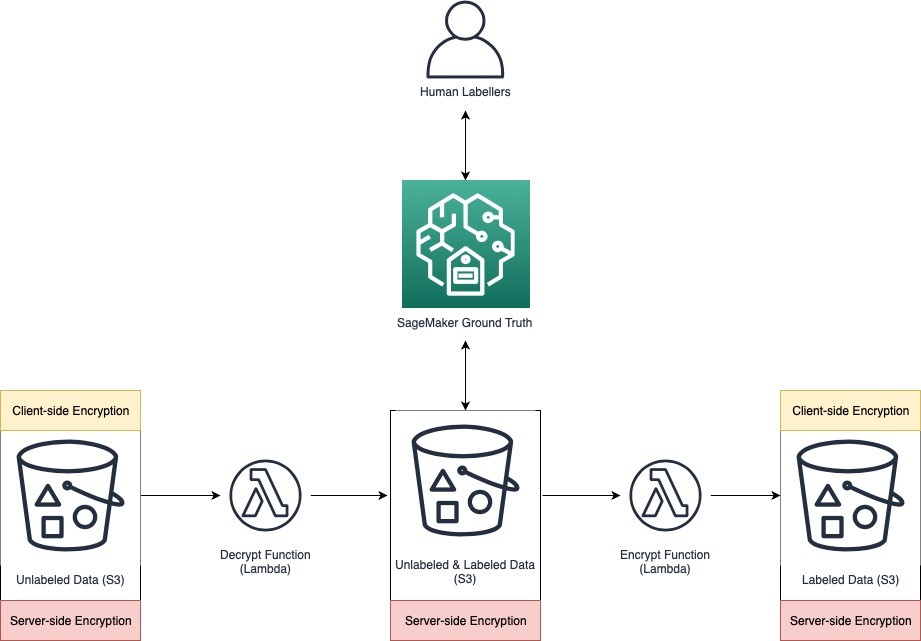
Let’s examine in detail how the three threat scenarios outlined earlier have been mitigated with this solution. When documenting the threat mitigations, we will do so with the shared responsibility model in mind, including controls implemented by the customer and by AWS.
Threat 1: Unauthorized user may access sensitive data as it’s being processed by SageMaker Ground Truth as the data must be decrypted in order to be usable by the service
You are able to rely on AWS controls already in place to address this threat. First, AWS does not access or use customer content without your permission. Furthermore, AWS has implemented a breadth of controls that have been verified by third-party auditors and can be assessed by customers within our SOC reports to address the risk of unauthorized access to your content. These controls include but are not limited to enforcing the principle of least privilege, logging and monitoring of access attempts, access reviews, personnel background checks, and others.
Threat 2: Unauthorized user may access sensitive unlabeled and labeled data in the S3 buckets
The customer needed to address the threat of unauthorized access to sensitive data in S3 buckets by AWS operators, from their own employees or bad actors. Controls are implemented by both AWS and the customer to address this. From AWS’s side of the shared responsibility model, in addition to controls outlined in the previous paragraph, customer data is stored in Amazon S3 in a highly distributed manner, such that no single person with access to an underlying system can locate and reconstruct customer data in any meaningful way. Data is fragmented and the fragments are distributed across multiple hosts within the system. In addition, the S3 encryption capabilities provide customers another layer of protection, minimizing the components that handle unencrypted data. As a result, the Amazon S3 API is the only interface for retrieving meaningful customer data from Amazon S3. The Amazon S3 API provides customers with full control of access policies for their Amazon S3 content.
On the customer side of the shared responsibility model, this threat can be minimized through use of server and client-side encryption, least privilege IAM and KMS key policies, and additional preventive and detective controls. As mentioned previously, server-side encryption was ubiquitously enforced by the customer on all buckets using the Amazon S3 default encryption feature. Data in the source bucket (unlabeled data) and final bucket (labeled data) was also encrypted client side as part of a defense in depth strategy. Data in the temp bucket was temporarily stored with server-side encryption only and several additional mitigating controls were implemented. First, human users can only access the data in the temp bucket using SageMaker Ground Truth service. An IAM role is assigned to SageMaker Ground Truth labeling jobs by the customer, which grants the service permission to decrypt the data and render it in the SageMaker Ground Truth UI. This IAM role is configured with a trust policy that allows only the SageMaker Ground Truth service to assume it. The workers who label the data do not have access to the temporary bucket directly. Additionally, all objects are deleted from the temporary bucket once the labeling job has completed.
Threat 3: Human labelers may leak sensitive data as they require temporary viability to clear-text data
This threat is addressed primarily by controls implemented by the customer. Ground Truth provides the ability for admins to restrict the type of workforce that can be used to label the jobs. Careful selection of the labeling service and workforce ensures that sensitive data is only processed by trusted individuals. Labeling services, such as those offered through the AWS Marketplace, provide workforces that are screened and in some cases certified to deal with sensitive types of data. Using IAM condition keys, the customer’s admin restricted all Ground Truth jobs to a private workforce only. Furthermore, for highly confidential data which should only be visible by limited individuals, the customer was able to further scope down the private workforce to a private work team, and use IAM policies to restrict the labeling job to an approved team within the organization. To limit the possibility of data exfiltration during the labeling process, the customer further restricted access to Ground Truth portal from their corporate IPs.
In the earlier example, our customer was able to leverage AWS encryption services and features, including server-side and client-side encryption options, least privilege, and additional mitigating controls, to help them meet their organization’s objectives to protect sensitive data with a cost effective and highly scalable architecture. You can use a similar approach to assess the threat scenarios within your specific workloads and define organizational control objectives in order to select the most appropriate controls for your data.
Key Takeaways
Work Backwards from Your Threats and Control Objectives
Work backwards from both your company’s compliance objectives and the specific threats identified within your threat model in order to determine the right encryption method for your use case. By working backwards, you’ll be able to assess both the AWS controls already in place as well as select the AWS encryption capabilities necessary to address your security and compliance objectives. When doing this exercise, customers can leverage one or multiple AWS audit reports available for download in AWS Artifact to understand the controls implemented by AWS and tested for operating effectiveness by third-party auditors. This customer chose the AWS SOC 2 report because it is a globally accepted audit often leveraged by financial services customers.
Reduce or Eliminate the Need for Direct Human Access to Data
Wherever possible, use automated pipelines, minimizing any unnecessary human access to reduce the risk of mishandling or modification and human error when handling sensitive data. For example, access to sensitive data can be restricted to the application IAM role in accordance with least privilege best practices, including well-scoped identity and resource-based policies.
Use Temporary Credentials
Use AWS temporary credentials as a mechanism to limit access to resources, including access to keys in AWS KMS. For example, customers can use IAM roles to delegate access to users, applications, or services that don’t normally have access to your AWS resources. A role can be assigned to a federated user who signs in by using an external identity provider instead of signing in directly using an AWS IAM identity. You can use AWS IAM or AWS Single Sign-On to federate your workforce into AWS accounts and business applications. A key benefit of IAM roles over IAM users is that a role does not have long-term credentials such as a password or access keys associated with it. Instead, when you assume a role, the AWS Security Token Service (AWS STS) issues you temporary security credentials for your role session. The security credentials vended by AWS STS expire and renew automatically every hour.
Scope Down Permissions
When you create access policies, follow the best practice of granting least privilege, or granting only the permissions required to perform a task. Determine the different personas that require access to resources within your application and for what purpose, and scope down permissions appropriately so they can perform only those tasks. Access to resources including keys in AWS KMS can further be scoped-down with conditions such as network location (e.g., IP CIDR range or specific VPC) as we described previously. Please refer to the following blog for additional sample IAM role trust policies such as limiting access from corporate IP range or to a special identifier.
Encryption as Part of Your Security Strategy
Encryption is a critical component of a defense in depth strategy. Financial services customers employ encryption to mitigate the risk of disclosure, alteration of sensitive information, or unauthorized access. AWS KMS allows customers to manage the lifecycle of encryption keys and control how they are used by their applications and AWS services. Using encryption, you can enforce tighter controls for your encrypted resources and because AWS KMS API calls are logged in CloudTrail, you can get more insight into the usage of your keys from an audit perspective. Please refer to the AWS Key Management Service Best Practices whitepaper for additional recommendations on implementing a well-architected encryption strategy.
—
Connect with us to learn more about how AWS can grow your Financial Services.