AWS for M&E Blog
Fox Digital Media Archive & Fox Media Services: Leveraging innovation in AWS to capitalize on an evolving media landscape
Guest post by Al Rundle (21st Century Fox, V.P. Media Applications & Engineering) and Jaime Valenzuela (21st Century Fox, Director of Software Development)
Introduction:
At 83 years, 20th Century Fox is one of the oldest movie and television studios. With those 83 years comes a long history of leading and participating in Media and Entertainment innovations and standards to continue to drive the industry forward as well as a healthy archive of valuable content. Those 83 years also come with maintaining and supporting a daunting number of legacy media formats, systems and workflows. The rapidly evolving media landscape is exponentially increasing in complexity, scale, and most importantly, opportunity. A studio’s ability to adopt an agile framework in order to innovate through iteration and purpose is no longer simply an advantage, but a requirement. Migrating from traditional on-premise, heavy iron, data centers and workflows to serverless infrastructure utilizing lightweight microservices, cloud native applications, and flexible architecture is the new standard for Media and Entertainment. Amazon’s astonishing rate of positive disruption and commitment to the Media and Entertainment Industry has created a rich arsenal of products and services that foster innovation across 20th Century Fox. By partnering with AWS, 20th Century Fox has embraced these challenges and is leveraging our consumer’s increased expectations for quality and access to our content to redefine how we master, archive, transform, package and deliver our content.
The 20th Century Fox Digital Media Archive was founded in an era where public cloud computing and storage was expensive and viewed as unsecure. On-premise LTO storage and “Enterprise” workflow solutions and databases were the standard. Even with all of the costs associated with the initial capital investment, continuous maintenance and support, power and cooling, and highly specialized software development and engineering staff, the highest costs to the Digital Media Archive were a byproduct of this rigid infrastructure that resulted in lost innovation and technical debt. This, coupled with the unstable cooling and power conditions of our data center and the costs of a traditional geo-separated Disaster Recovery with no other value or opportunity, all signaled a need for something more flexible that was iteratively innovating in a way we could align with in order to transition the software, workflows and infrastructure that support our business.
The 20th Century Fox Digital Media Archive and Fox Media Services departments are supported by the same software development and engineering team. Two and a half years ago, we started with a Proof of Concept utilizing S3, EC2, and Docker to develop and deploy an internal application for the purpose of generating industry standard MovieLabs packages. The success of this POC lead to the creation of a cloud hosted Home Entertainment chapter metadata and thumbnail archive with a full set of APIs. With these POCs, we had just scratched the surface and with our eye on Amazon’s continuous advancements with container services, SQL and NoSQL databases, serverless functions and workflows, and dropping storage prices, it quickly became clear that AWS was a prime partner and we began to define our strategy.
- Re-think our existing passive Disaster Recovery strategy by re-writing our Digital Media Archive to be cloud native with functional on-prem and cloud storage.
- Develop serverless and cloud native workflows and microservices to replace our rigid on-prem workflow software.
- Utilize Terraform to deploy and maintain consistent infrastructure in all environments.
- Replace expensive and support heavy on-prem databases.
- Architect a new platform that empowers our application administrators to map APIs and dynamically generate webforms to create and expand workflows without the need of software development for each feature request.
Below we will detail how 20th Century Fox Digital Media Archive and Fox Media Services is using internal innovation and AWS to execute this strategy.
Leveraging Microservices to Orchestrate Serverless Media Workflows in AWS
AWS has contributed many innovations in serverless application architecture that facilitates microservice deployment and use. Because it is easy to deploy serverless hyper-focused Lambda functions, applications now have to integrate and orchestrate many service calls to complete a job. Our software development team at 20th Century Fox Digital Media Archive continues to iteratively develop a suite of applications to stream line the creation of webforms (Stencil) and the orchestration of microservice calls with AWS Step Functions (Tube) to process, package, deliver, archive, and restore our content. Our Stencil application allows the mapping of JSON data fields to webform elements like textboxes, dropdowns, checkboxes, etc. via point and click. These webforms are rendered as part of a workflow where a user needs to provide data to run a job. Our media workflows are defined as a sequence of steps that can be executed by a computer or a human and are created and configured in Tube as a pipeline. These applications are deployed to AWS using Docker containers and managed through ECR.

Figure 1. Workflow Management High Level Architecture
MEDIA WORKFLOWS
A media workflow in our facility is a series of steps that are carried out to catalog, transform, package, and/or deliver media. These workflows are then optimized for ease of use and throughput into a pipeline. Jobs are instances of pipelines that are performed to a specific version of a given title. There are hundreds of jobs running in our facility 24/7 to keep up with business demands.
MICROSERVICES
To optimize our media workflows we implemented a solution (Tube) to create, modify, and manage different pipelines. Pipelines use AWS Step Functions to invoke reusable and scalable microservices through REST API calls in a specific order to aggregate and transform any data necessary to execute a given job.
With hyper-focused AWS Lambda Functions, we decoupled a great deal of functionality from specific applications. We have two microservice categories that are available to be orchestrated in parallel or in series. The first group provide technical or title metadata required to identify and transform media correctly – aspect ratios, framerates, language codes, audio configurations etc. They retrieve the data from individual DynamoDB collections and they are used to cascade necessary information to another service or display in a form for user selection. The second group performs common functionality like string manipulation, file naming, timecode calculations, framerate conversions etc. By leveraging these microservices in our workflows, we can minimize the amount of operator data entry by looking up or deriving as much data as possible. This allows our Operations staff to focus on the quality of our content and ensure we are meeting business requirements and timelines. To facilitate the Operator’s ability to do their job effectively and efficiently, various webforms for data entry and dashboaring are required.
USER INPUT
Microservices using Lambda Functions and API Gateway provide scalability and flexibility, but they demand more development work when users need to interact or provide required data as input to the pipeline. Each of our pipelines needs users to enter data and interact with webforms that are unique to the workflow. This data is consumed and used as input in a REST call. To avoid having to code specific webforms for each pipeline, we developed Stencil, a NodeJS solution that generates webforms programmatically. Stencil allows administrator users to map webform elements – i.e. textboxes, dropdowns or checkboxes – to a variable in a given REST API input. Administrators perform this mapping via a simple point and click process and are able to assign input validation, layout and styling. Figure 2. Instances of these programmatically generated webforms are presented to operators when executing a job in a pipeline. Figure 3.

Figure 2. API variables mapped to UI elements

Figure 3. Programmatically rendered webform
Creating the ability for application administrators to perform what traditionally required ongoing software development feature requests and support has provided many advantages. Just as our workflow solutions free our Operators to focus on what they do best, Stencil frees our Software Development team from trivial tasks and allows them to focus on the strategic goals of the Studio. By empowering the application administrator to map APIs, create webforms, and generate workflows, a technical resource intimately familiar with the day-to-day business needs can implement new workflows and features. As a result, the time to market for highly valuable enhancements is significantly reduced for most use cases.
ORCHESTRATION
Our media workflows contain tasks that run for unknown periods of time. One of the challenges to combine microservices with Stencils and manage the data flow in the execution of Step Functions is having to wait for operators to fill out forms when required, and to allow for long running processes to execute without timing out. Our Tube NodeJS application keeps track of the state of each task for every job running across any and all pipelines. It stores the status and result of any Step Function in a pipeline throughout its execution. Tube has mechanisms to present users with a stencil-generated webform and wait for input. It also has the ability to submit long running tasks into Simple Queues and wait for the result to comeback to continue the Step Function execution. State and results are presented to operators in a dashboard for all running jobs. Operators also have the ability to search the final state of any past pipeline executions.
Since AWS Step Functions are designed to track state and easily define any desired sequence to execute and cascade data through the pipeline, microservice orchestration can be easily achieved. Tube stores the state and results for all Step Function tasks in its own data collection. With the stored data, operators are able to step back in a workflow to recover from errors, modify input data, or resubmit jobs. Figure 4.

Figure 4. Step Functions Metadata with User Input
Digital Media Archive
20th Century Fox’s Digital Media Archive is responsible for holding the losslessly compressed Studio assets. As a result, geo-separation of these assets for the purpose of Disaster Recovery is paramount. Keeping pace with the increased data requirements for formats such as 4K HDR as well as the complexity of archiving and servicing emerging formats such as IMF require a highly scalable and flexible asset management solution. As Fox continues to be at the leading edge of new industry initiatives, having a partnership with a media centric asset management solution, Vidispine, as our backend is critical to keep pace.
The Digital Media Archive offers its users the ability to store, search and retrieve digital masters in AWS and On-premise. The Media Asset Management application and databases are run in Docker containers that are deployed and managed through AWS ECR. We also leverage Terraform across 21st Century Fox with a pull request model to ensure best practices are universally adopted. The Digital Media Archive is just one of many business units at 21st Century Fox using AWS. Terraform provides an efficient way for us to make a request to our Cloud shared services team to deploy changes into our VPC. Terraform allows us to easily manage changes and deploy entire environments consistently with minimal effort.
The Digital Media Archive integrates many AWS products (Figure 5) and with our own Tube and Stencil applications to perform the Archiving (Ingest pipeline) and Restoring functionality (Retrieval pipeline.) A few AWS products used in Tube and Stencil are outlined in Figure 6.
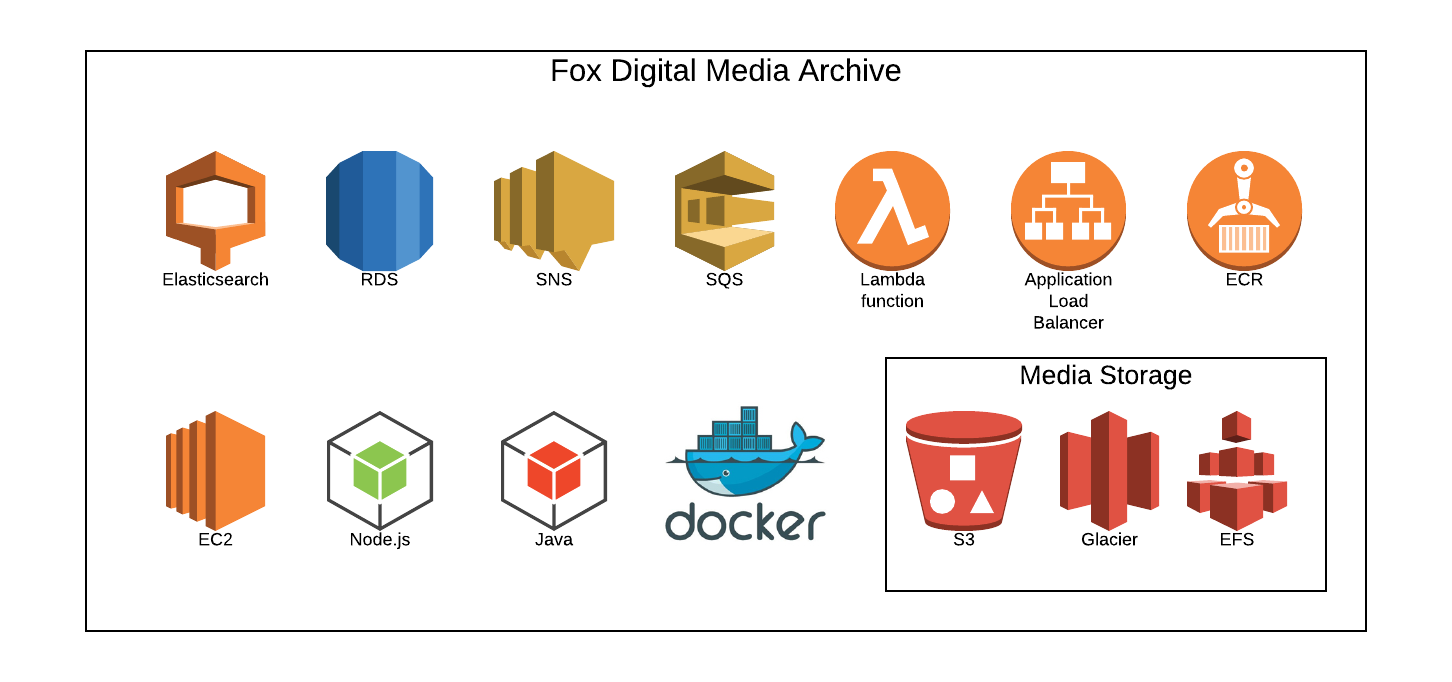
Figure 5. Digital Media Archive Solution Components
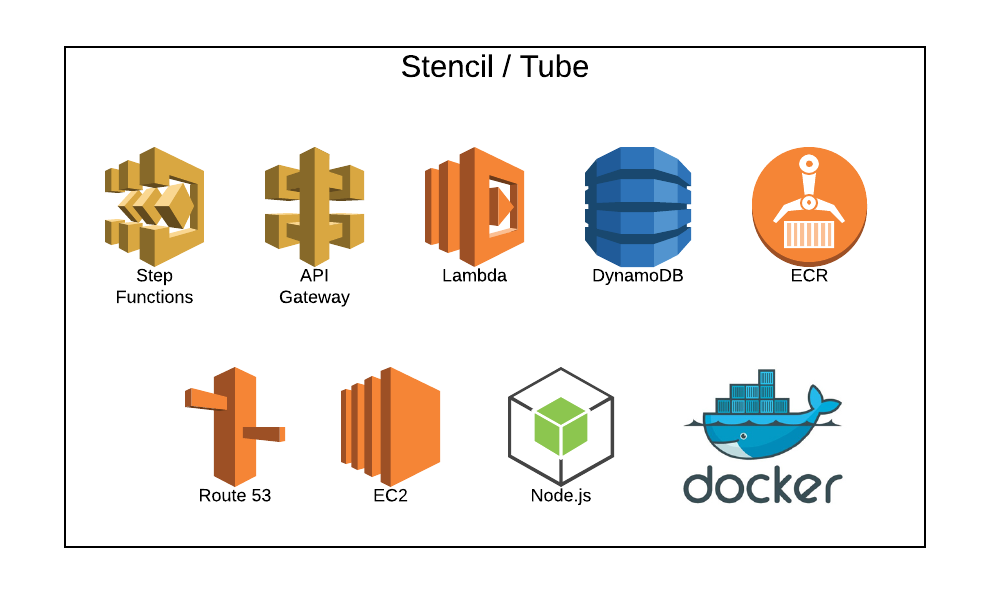
Figure 6. Stencil / Tube Application Components
When an operator starts an Ingest job, they must associate the media with basic title and technical metadata. There is an automated verification process that uses several Lambda Functions. This verification process leverages the file name, media file introspection and analysis as well as QC reports to ensure that the files being archived are associated with the correct title, version, and other technical metadata. The Ingest pipeline also ensures that media files conform to our technical specifications. A record is created for the media in the asset management system and other external systems are updated. Files are then copied simultaneously into the on-premise storage systems and S3 storage (and subsequently Glacier) for disaster recovery. After the asset is in S3 a proxy asset is created leveraging Lambda, API Gateway, Elemental MediaConvert, and SQS. Assets are then attached to the lossless masters in Vidispine. Using the Media Convert service enables us to scale seamlessly to meet any load without having to manage any infrastructure, licensing, or configuration changes. See Figure 7.
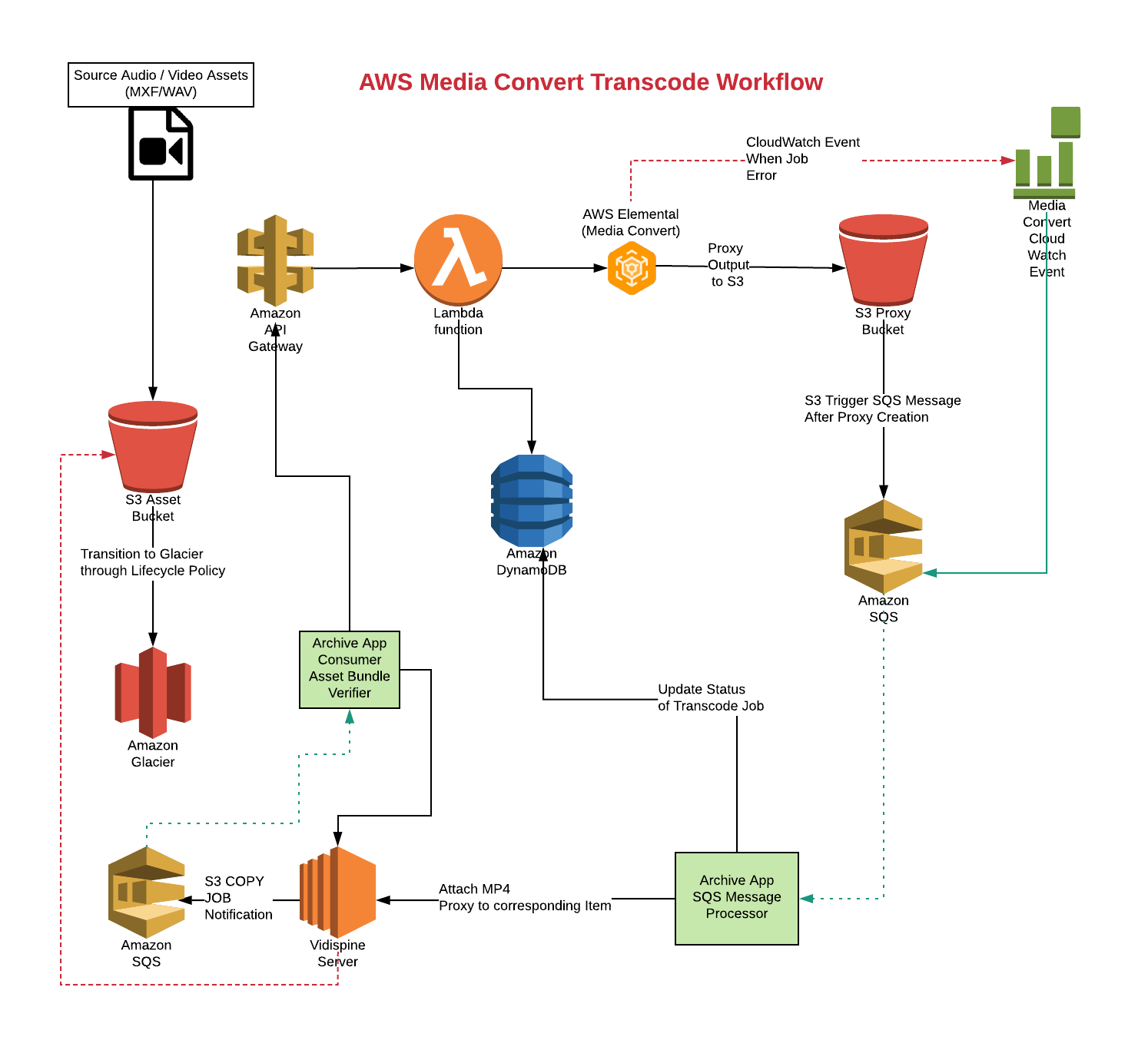
Figure 7. Proxy creation workflow using Elemental MediaConvert
Our hybrid cloud and on-prem architecture lets us scale quickly to meet expanding and often competing business requirements. All these tasks are orchestrated microservice calls via Step Functions. The state and job progress is presented in a status dashboard and users are alerted if errors are encountered in the pipeline. Figure 8.
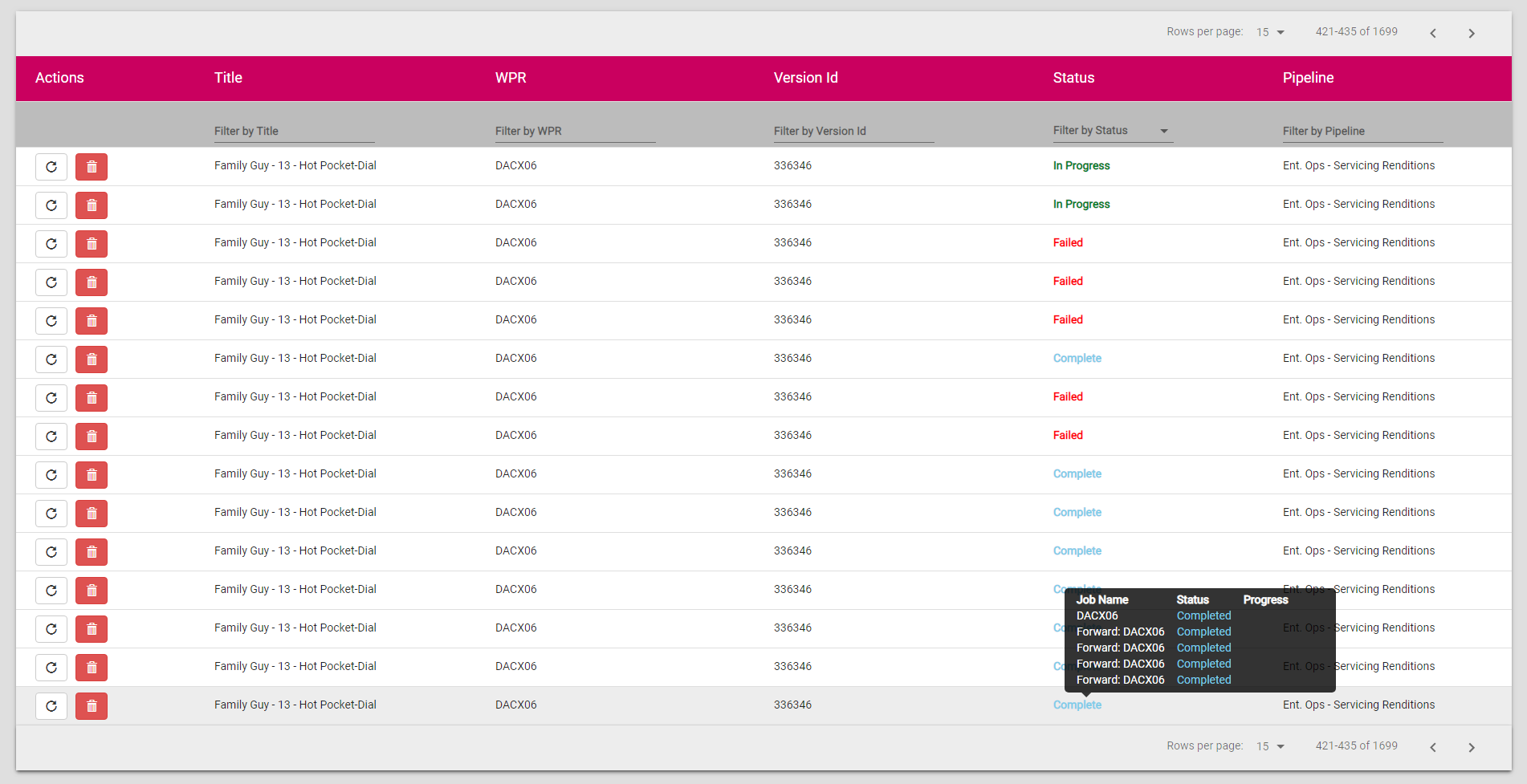
Figure 8. Job Status Dashboard
Once the media files are in the asset management system, users can search, browse and preview media via proxies. The entire contents of our archive is at the user’s fingertips thanks to Elasticsearch. The most common use-case is searching for a particular asset to be updated in the archive or media files restored. Once the desired asset is identified, operators will invoke a retrieval pipeline to restore the media and deliver it B2B to one of our internal business units, outside vendors, or retailer partners.
The retrieval pipeline’s goal is to restore the desired assets to a particular network storage location or transfers to an external facility or customer. This pipeline orchestrates calls to a checksum, file naming and file moving Lambda Function based microservices. The status dashboard presents the state and progress of the Step Functions that make the retrieval pipeline and alerts are displayed if errors occur.Utilizing an asset management solution that leverages both on-prem and cloud components and storage allows our ingest, archive, and restore pipelines to be leveraged for our current and future requirements. This architecture not only satisfies our goal for having geo-separated assets for Disaster Recovery purposes, but also creates a virtual secondary facility location that we can leverage to build out 100% cloud based workflows with limitless scalability.
WHAT IS NEXT?
AWS Cloud technology offers a new paradigm for media workflows that facilitates the decoupling of functionality into reusable microservices. Programmatic webform creation for user input substantially reduces the software development effort. Orchestrating microservice calls empowers application developers with the ability to create media pipelines to increase reliability and productivity in a modern media company. With an increased presence in the cloud, we are actively working on several POCs with Amazon partners to accelerate our strategy and keep pace with industry demands. As these partners mature, we will be leveraging them to move more editorial, processing, packaging, and delivery to the cloud to redefine the Digital Supply Chain. The maturing of Amazon services such as Elemental MediaConvert for IMF support and Fargate for container orchestration are innovations that align with our internal development efforts and strategic goals. This next evolution of the Media and Entertainment Industry is exciting and full of opportunity for those who can remain agile and adapt to this new “normal.”