AWS for M&E Blog
Part 1: How to compete with broadcast latency using current adaptive bitrate technologies
Part 1: Defining and Measuring Latency (this post)
Part 2: Recommended Optimizations for Encoding, Packaging, and CDN Delivery
Part 3: Recommended Optimizations for Video Players
Part 4: Reference Architectures and Tests Results
Part 1: Defining and Measuring Latency
Why is latency a problem for live video streaming? Whenever content delivery is time sensitive, whether it be TV content like sports, games, or news or pure OTT content such as eSports or gambling, you cannot afford a delay. Waiting kills the suspense; waiting turns you into a second-class citizen in the world of entertainment and real-time information. An obvious example is watching a soccer game: Your neighbor watches it on traditional TV and shouts through the walls on each goal of his favorite team, usually the same as yours, while you have to wait 25 or 30 seconds before you can see the same goal with your OTT service. This is highly frustrating, and similar to when your favorite singing contest results are spoiled by a Twitter or Facebook feed that you monitor alongside the streaming channel. Those social feeds are usually generated by users watching the show on their own TV, so your comparative latency usually goes down to 15 to 20 seconds, but you are still significantly behind live TV.
On top of the broadcast latency and social network competition, there are other reasons why content providers would like to minimize live streaming latency. Their old Flash-based application using RTMP streaming was working well in terms of latency, but Flash has slowly but surely been deprecated in web browsers, leading CDNs to deprecate RTMP on the delivery side, so content providers need to switch to HTML5-friendly streaming technologies, like HLS and DASH, or more recently CMAF. Other content providers want to develop personal broadcasting services with interactive features, and a 30-second delay of the video signal does not work at all for this use case. In addition, those who want to develop synchronized second screen, social watching, or gambling applications need to control the streaming latency on a fine-grain level.
When it comes to latency, three categories are usually defined, with high and low boundaries. They do not match exactly with broadcast latency, which spans between 3 and 12 seconds depending on the transport means (cable/IPTV/DTT/satellite) and the specifics of each delivery network topology. The average value of 6 seconds of broadcast latency is very often seen in the field, which means that the sweet spot for OTT is somewhere in the low range of the “reduced latency” category or the high range of the “low latency” category. Getting close to 5 seconds maximizes the chances to efficiently fight against the competition of broadcast and social network feeds. Moreover, depending on the OTT encoders’ location in the content preparation workflow, the latency reduction objective increases if encoders are positioned downstream in the chain.
| TERMINOLOGY | HIGH (seconds) | LOW (seconds) |
|---|---|---|
| Reduced Latency | 18 | 10 |
| Low Latency | 10 | 4 |
| Ultra Low Latency | 4 | 1 |
With HTTP-based streaming, latency mainly depends on the media segment length: If your media segments are 6 seconds long, it means that your player will already be at least 6 seconds late compared to the actual absolute time when it requests the first segment. And many players download additional media segments to their buffer before the actual start of the playback, which will automatically increase the time to the first decoded video frame. There are, of course, other factors generating latency, like the video encoding pipeline duration, the duration of ingest and packaging operations, network propagation delays, and the CDN buffer (if any). But in most cases, the player carries the largest share of the overall latency. Indeed, most players would generally use conservative heuristics and buffer three segments or more.
With Microsoft Smooth Streaming, the usual segment length is 2 seconds, generally ending up at around 10 seconds latency in a Silverlight player. With DASH, it’s pretty much the same. Most players can support 2 second segments, with variable results in terms of latency. But the situation is quite different with HLS: Until mid-2016, Apple’s recommendation was to use 10 second segments, which ended up at around 30 seconds of latency in most HLS players including Apple’s own players. In August 2016, Apple’s Technical Note TN2224 stated, “We used to recommended a ten second target duration. We aren’t expecting you to suddenly re-segment all your content. But we do believe that, going forward, six seconds makes for a better tradeoff.” Four seconds less per segment and that’s 12 seconds of latency that are suddenly vanishing from our screens. Most of the time, content producers followed Apple’s recommendations, even if iOS players could work with smaller segment lengths, because they didn’t want to take any risk with the validation of their iOS applications in the AppStore. But three recent evolutions changed the game with Safari Mobile on iOS11: the autostart feature for live HLS streams is enabled; support for small segment durations is significantly improved; and FairPlay DRM is now supported. This means that content producers who don’t absolutely need to use a compiled application on iOS can benefit from reduced live latency through short media segments, while at the same time delivering protected streams with a studio-approved DRM.
Some might object that short media segments introduce a high load on the CDN and on the players, but this has actually been the case for many years with Microsoft Smooth Streaming leveraging 2 second segments. Toreduce the latency gap with broadcast, the next step is the movement to a 1 second segment, and this does not actually generate a major bottlenext either. Of course it multiplies the number of requests by two, with all the HTTP overhead in terms of headers and TCP connections, but it’s fairly manageable by a CDN (especially if it supports HTTP 2.0 at the edge and HTTP 1.1 origins, like Amazon CloudFront does), and the modern players that benefit from higher bandwidth last mile connections through fiber, 4G, LTE, DOCSIS 3.1 FD, and other recent connectivity advances. Experimentations show that short segments of 1 and 2 seconds are now supported by many players, thus providing a lot of new options for lower latency. Finally, short segments aren’t usually a problem for encoders, packagers, and origin services across the chain, in both HLS and DASH.
Outside of AppStore requirements, which still enforce a 6 second segment duration, there is a flexibility for content producers to experiment with 1 or 2 second media segments in various players on all platforms, with equal broadcast latency or faster.
At a high level, here are the main actions to conduct in order to get your streaming solution into the “low latency” category:
- Optimize your video encoding pipeline
- Choose the right segment duration for your requirements
- Build the appropriate architecture
- Optimize (or replace) your video player(s)
Let’s see how this can be done with AWS Elemental video solutions combined with open source or commercial players available today.
How to Measure Latency
The first step in the latency optimization process is to know which component in the chain is responsible for which percentage of the overall latency. It will guide you towards your optimization priorities, whether in the encoding, the packaging, or the playback stages of the workflow. Let’s start by measuring the end-to-end latency.
The easiest way to measure end-to-end latency is to use a tablet running a clapperboard application, film it with a camera connected to your encoder, publish your stream to your origin, and deliver to your player through a CDN. Put the player alongside the clapperboard tablet, take a picture of the two screens, subtract the timecodes on each screen, and that’s it, you have your number. You should do this a few times to make sure it is an accurate representation of your workflow’s latency.
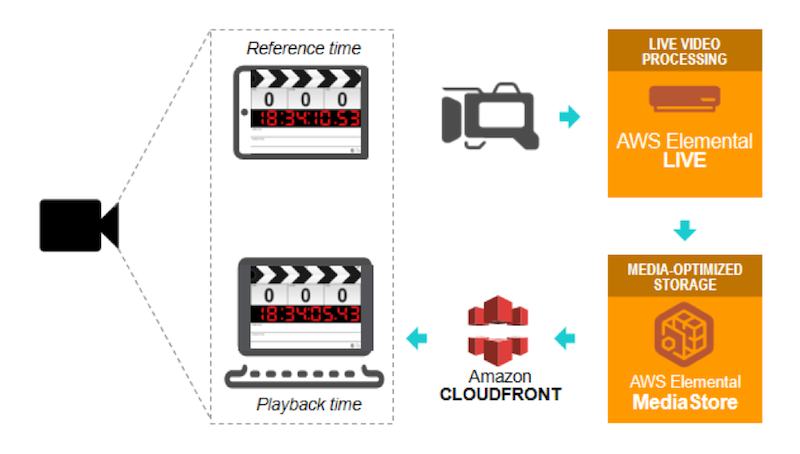
Alternatively, you can use an AWS Elemental Live encoder with a looped file source, burn the encoder time (with the encoder using an NTP reference) as overlay on the video, and compare the burnt timecode with a time service such as time.is in a browser window. You will need to add the capture latency, usually around 400ms.
Capture Latency
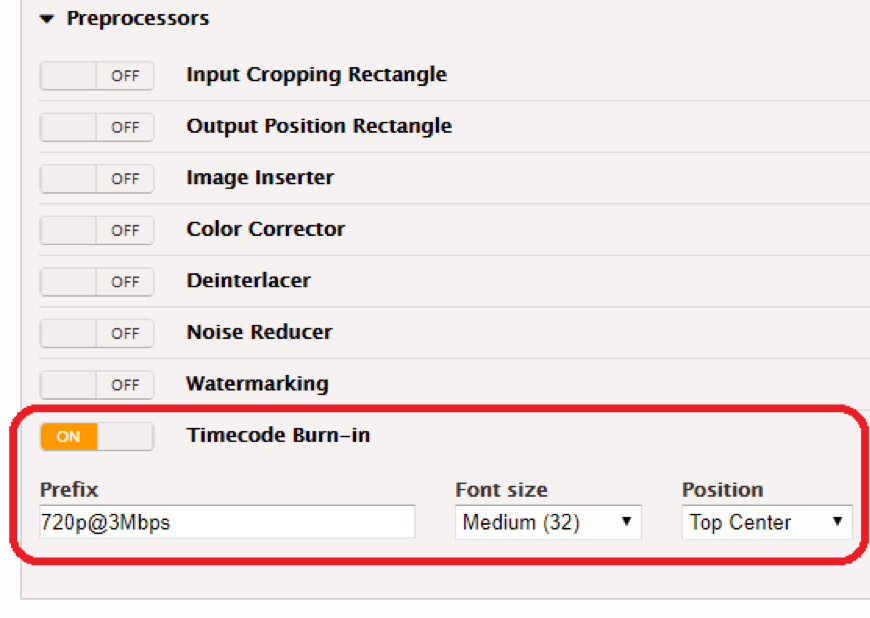
You can activate the timecode burn on AWS Elemental Live in the pre-processors section of your video encoding parameters; you will need to activate it for each bitrate of your encoding ladder.
You need to verify that you set up your encoder in low latency mode. With AWS Elemental Live, this means selecting the “Low Latency Mode” checkbox in the “Additional Global Configuration” section of the Input parameters.
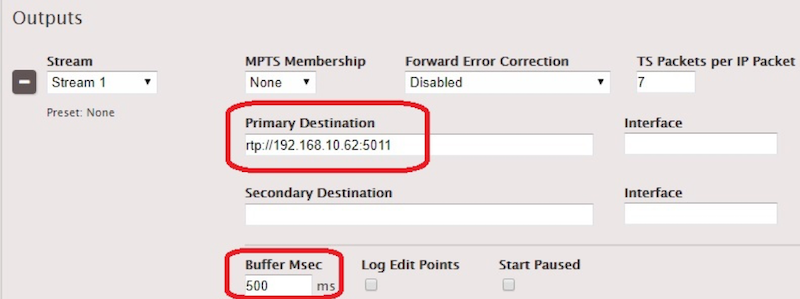
Next, set up a UDP/TS encoding event with a 500 ms Buffer in the TS output section, with your laptop IP as the destination.
On your laptop, open the network stream on VLC (in this example, rtp://192.168.10.62:5011) with a :network-caching=200 option to use a 200 ms network buffer. You will be able to calculate the capture latency from a snapshot of your VLC window, by comparing the burnt timecode with the clapperboard timecode.

If your tablet doesn’t allow you to synchronize it with NTP, some applications such as “Emerald Time” on iOS nevertheless allow you to find how much your tablet’s time drift is compared to NTP. In our case, the drift is +0.023s, meaning that the clapperboard time is actually 25:00.86 instead of 25:00.88. The burnt timecode is 25:01:06 (the last two digits being the frame number), which can be translated into 25:01.25 in 100ths of a second (as we are encoding at 24fps). Our capture latency is therefore (25:01.25 – 25:00.86 ) = 0.39 seconds. The formula is: Capture latency = Burnt Timecode in seconds – (Clapperboard Timecode + NTP Drift).
Encoding Latency
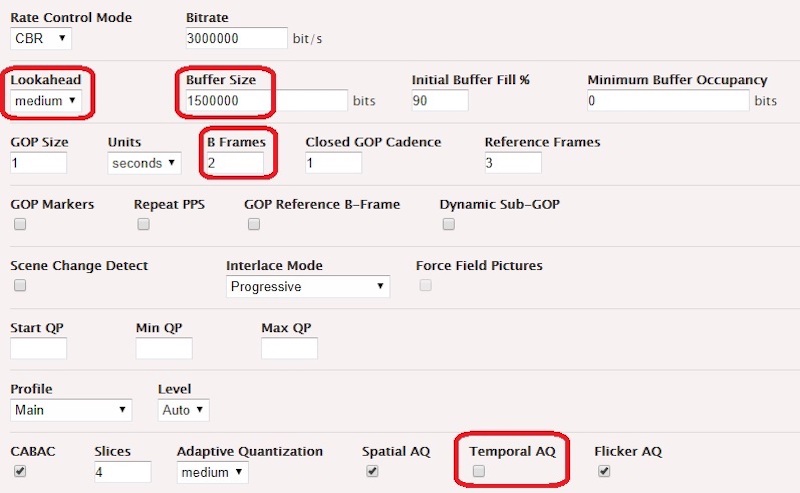
With this UDP/TS encoding event, we can also calculate the latency generated by the video encoding pipeline. Our example uses the following encoding parameters in order to generate broadcast-compliant quality for highly demanding scenes, while proposing an acceptable tradeoff in terms of induced latency.
In our case, we have a tablet time of 13:27:19.32 and a VLC time of 13:27:16.75.

The encoding pipeline latency is calculated with the following formula: (Tablet time – VLC time) – (Capture latency + VLC buffer + RTP buffer), which translates to (19.32-16.75) – (0.39 + 0.20 + 0.50) = 1.48 seconds
Ingest Latency
Now that we know the capture latency and the encoding pipeline latency, let’s figure out the ingest latency. “Ingest latency” includes the time necessary to package the ingest format and to ingest it to an origin that does not apply packaging on the ingested stream – this could be AWS Elemental Delta with a passthrough filter, or AWS Elemental MediaStore. Here we use HLS with 1 second segments pushed to AWS Elemental MediaStore.
With a shell, we monitor the changes on the HLS child playlist on the origin :
$ while sleep 0.01; do curl https://container.mediastore.eu-west-1.amazonaws.com/livehls/index_730.m3u8 && date +"%Y-%m-%d %H:%M:%S,%3N"; doneWhich returns, when segment “index_73020180223T154954_02190.ts” is first referenced in the shell output:
#EXTM3U
[…]
index_73020180223T154954_02190.ts
2018-02-23 15:49:55,515We then download the segment “index_73020180223T154954_02190.ts” to verify which timecode it carries: 16:49:53:37 (UTC+1). The difference between the current date and the segment timecode is 55.51 – 53.37 = 2.14 seconds. If we strip out the encoding latency and capture latency, we isolate the time needed to package the HLS segments and to push it to the origin. The formula is Ingest Latency = (Current Date – Segment Timecode) – (Capture Latency + Encoding Latency).For AWS Elemental MediaStore we are getting 0.27 seconds. For AWS Elemental Delta, the same calculation gives 0.55seconds.
Repackaging Latency
By applying the same approach to AWS Elemental Delta and AWS Elemental MediaPackage, and adding the ingest latency previously calculated, we can calculate the time required to repackage the ingested stream. The formula is
Repackaging Latency = (Current Date – Segment Timecode) – (Capture Latency + Encoding Latency + Ingest Latency)
For AWS ElementalMediaPackage (assuming the ingest latency is the same as AWS Elemental Delta, as there’s no simple way to measure it) outputting HLS 1 second segments from the HLS 1 second ingest, the repackaging latency is (57.34 – 54.58) – (0.39 + 1.48 + 0.55) = 0.34 seconds. For AWS Elemental Delta its (26.41 –23.86) – (0.39 + 1.48 + 0.55) = 0.41 seconds.
Delivery Latency
The same approach can be applied to delivery – namely the transport from the origin up to the CDN edge. In cases where the origin does repackaging, Delivery Latency =(Current Date – Segment Timecode) – (Capture Latency + Encoding Latency + Ingest Latency + Repackaging Latency). When the origin does passthrough streaming,Delivery Latency =(Current Date – Segment Timecode) – (Capture Latency + Encoding Latency + Ingest Latency). Delivery latency can be measured by adding an Amazon CloudFront distribution on top of the origin and using the same kind of command line as the ingest latency calculation.For AWS Elemental MediaStore, we have (52.71 – 50.40) – (0.39 + 1.48 + 0.27), which is 0.17 seconds. This latency is the same for all origin types in the same region.
Client Latency
In this category, we can find two latency factors that depend on the client: the last mile latency (related to network bandwidth), and the player latency (related to content buffer). The last mile latency ranges from a few milliseconds on a fiber connection, up to several seconds on the slowest mobile connections. The content download duration directly impacts the latency as it delays to T+x seconds the moment when timecode T will be available for buffering and playback on the client side. If this delay is too large compared to the segment length, then the player won’t be able to build a sufficient buffer, and it will switch down to a lower bitrate in the encoding ladder until finding a suitable tradeoff between the bitrate, the network conditions, and the ability to build its content buffer. If even the lowest bitrate doesn’t allow a sufficient buffer to build, it will constantly start the playback, stop, and rebuffer, as the content can’t be downloaded quickly enough. As soon as the content download duration starts to rise to 50% of the segment duration, it takes the player to a dangerous zone from the buffer perspective. Ideally, it should stay under 25%. The player latency is a consequence of the buffer policy of the player – the player might require X number of segments to be buffered, or a specific minimum duration of content – plus the playhead positioning strategy.
The way client latency can be measured is Client Latency = End-to-end Latency – (Capture Latency + Encoding Latency + Ingest Latency + Repackaging Latency + Delivery Latency). Player latency can be isolated by subtracting the average transfer time (aka last mile latency) for the media segments from the overall client latency. This last mile latency value needs to be calculated on at least 20 segment requests. It will include the actual data transfer time and the waiting time that can be generated by the client. For example, if all allowed sockets for a given subdomain are currently opened when a segment request is created.
Here is an example breakdown with HLS 1 second segments produced with AWS Elemental Live and AWS Elemental MediaStore, delivered with Amazon CloudFront to a standard hls.js 0.8.9 player:
| LATENCY TYPE | SECONDS | IMPACT |
|---|---|---|
| Capture | 0.39 | 7.58% |
| Encoding | 1.48 | 28.79% |
| Ingest | 0.27 | 5.25% |
| Repackaging | N/A | N/A |
| Delivery | 0.17 | 3.33% |
| Last Mile | 0.28 | 5.44% |
| Player | 2.55 | 49.61% |
| End-to-End Latency | 5.14 | 100% |
As we see, the encoding and playback steps are generating most of the latency. This is where most of the improvement margin is located. It doesn’t mean that there is no way to optimize the other steps, but that the impact of the optimizations will be minimal. When the output media segments duration increases, the player and last mile latencies usually increase while the other steps stay stable.
In part 2 of this series, we’ll examine the optimization options that we can apply on each step of the workflow.