AWS Cloud Operations Blog
Using AWS Systems Manager Run Command to submit Spark/Hadoop jobs on Amazon EMR
Many customers use Amazon EMR with Apache Spark to build scalable big data pipelines. For large-scale production pipelines, a common use case is to read complex data from a variety of sources. This data must be transformed to make it useful to downstream applications, such as machine learning pipelines, analytics dashboards, and business reports. Such pipelines often require Spark or Hadoop jobs to be submitted on Amazon EMR. This post focuses on how to submit Hadoop or Spark jobs on an Amazon EMR cluster using AWS SystemManager Run Command .
Overview
Run Command, which is part of AWS Systems Manager, is designed to let you remotely and securely manage instances. Run Command provides a simple way of automating common administrative tasks like running shell scripts, installing software or patches, and more. Run Command allows you to execute these commands across multiple instances and provides visibility into the results. Through integration with IAM, you can apply granular permissions to control the actions users can perform on instances. All actions taken with Run Command are recorded by AWS CloudTrail, allowing you to audit changes in your fleet.
In this post, I demonstrate how to use the SSM Run Command and submit Spark and Hadoop jobs on Amazon EMR securely without using SSH, as interactive SSH access to traditional server-based resources often comes with high management and security overhead. User accounts, passwords, SSH keys, and inbound network ports need to be maintained to provide this level of access, and there is often the additional cost of supporting additional infrastructure for bastion hosts, etc.
Prerequisites
Before you get started, make sure you have done the following:
1. Create an IAM role with least-restricted access for AWS Systems Manager and Amazon S3 services
- Attach the AmazonSSMManagedInstanceCore managed policy for the role created, as seen in the following screenshot.
- Create and attach a least-restricted policy which has access to the only Amazon S3 bucket. As seen in the following screenshot , s3://ssmruncmdemr bucket is used to stage the shell script code and persist the output of SSM RUNCMD execution.
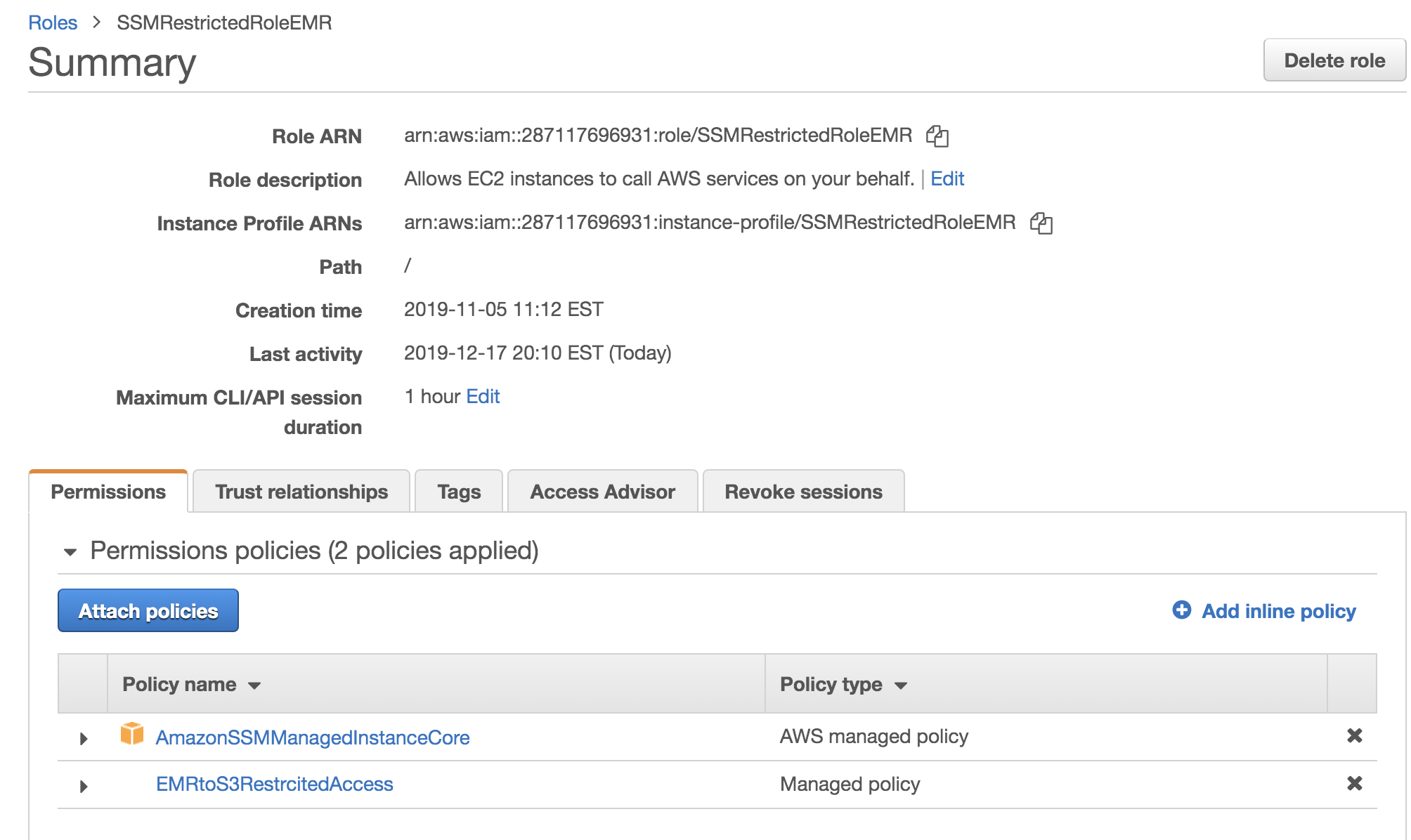
2. Launch the Amazon EMR cluster. By default, Amazon EMR launches with the EMR_EC2_Instance role. Select the role you created in the previous step. Once the Amazon EMR cluster is ready and in the waiting state, the Amazon EC2 Instance Profile will have role you specified, as shown in the following screenshot.

Demonstrating the AWS-RunShellScript using the AWS console
Follow these steps to demonstrate the AWS-Run-Shell-Script.
- Log into the Systems Manager console and choose Run Command from the left navigation pane.
- Choose the AWS Systems Manager AWS-RunShellScript document, as shown in the following screenshot.
- Using Run Command and the AWS-RunShellScript document, you can run any command or script on an Amazon EMR instance as if you were logged on locally

- Pass the value for the command parameter. You can specify either the path for the script located in the Amazon EMR instance or the direct Unix or Hadoop command.
Example 1
In this step, you pass the shell script as command parameter. The shell script invokes spark job as part of its execution. Scripts are copied from Amazon S3 to the Amazon EMR home/hadoop directory, as shown in the following screenshot.

Run Command provides options to choose an instance by tags, manually, or by a resource group. Select the Amazon EMR master node instance manually, as shown in the following screenshot

EMR Master Node

After the command is submitted, you can track the AWS-RunShellScript command from the UI. You see the status of the command as In Progress and, after it completes, as Success, as shown in the following screenshot. The results of the command persist on the Amazon S3 bucket

The output shown in the following screenshot demonstrates successful execution:
Script has performed following actions:
- The artifact has been copied from the Amazon S3 bucket to Amazon EMR home/hadoop directory.
- The actual shell script code is displayed using Unix cat command.You can see the shell script code in following screenshot
- Added Wait for 10 seconds.
- The shell script Big_data_processing.sh is executed, which runs the Spark example sparkPi
#Big_data_processing.sh
#!bin/sh
echo "Starting Spark Job1"
echo "start time:"
date '+%F %T'
spark-submit --executor-memory 1g --class org.apache.spark.examples.SparkPi /usr/lib/spark/examples/jars/spark-examples.jar 10
echo "end time:"
date '+%F %T'
echo "ETL Job 1 completed"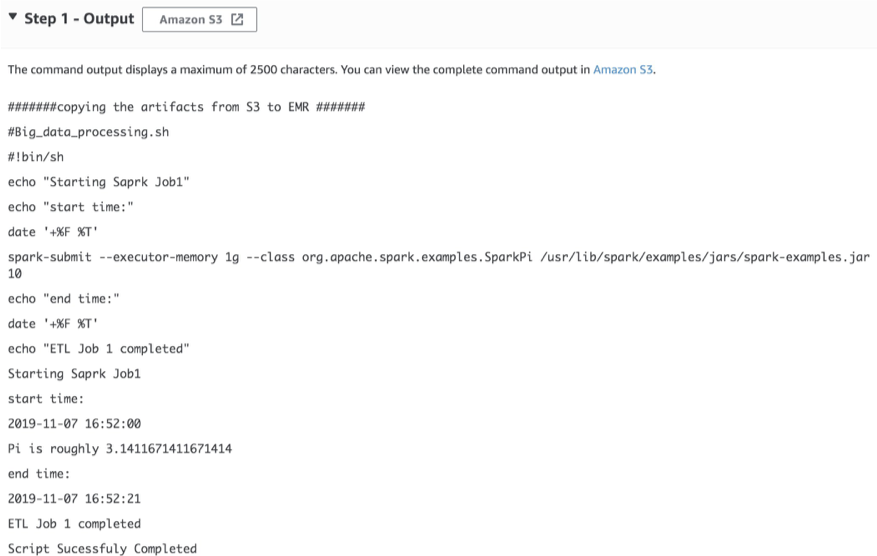
RunCommand – SparkOutput
Note: If you plan to run multiple Apache Spark jobs at same time, invoke the shell script in background mode so that the next command can run without waiting for the current command to complete. Ensure the Amazon EMR has the supported configuration to run parallel loads.
Example 2
In this example, you pass a Hadoop administration command to check HDFS file system usage.
hdfs dfs -df -h
Above command displays free space , used space of HDFS on an Amazon EMR in human readable format

Hadoop Command
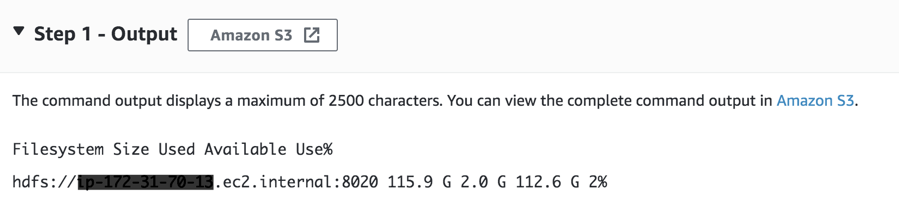
Hadoop Command Output
Demonstrate AWS-Run-Shell-Script using AWS CLI
You can accomplish the same using the following AWS CLI command:
aws ssm send-command --document-name "AWS-RunShellScript" --document-version "1" --targets '[{"Key":"InstanceIds","Values":["i-instanceid"]}]' --parameters '{"workingDirectory":[""],"executionTimeout":["3600"],"commands":["sh /home/hadoop/Big_data_processing.sh"]}' --timeout-seconds 600 --max-concurrency "50" --max-errors "0" --output-s3-bucket-name "ssmruncmdemr" --output-s3-key-prefix "output" --region us-east-1
aws ssm list-command-invocations --command-id "f0a3241c-29a8-418b-bb16-33f2f9337874" --details
Check the Hadoop or Spark job status from the YARN Resource Manager UI
Open the Amazon EMR resource manager UI (http://master-public-dns-name:8088/) to verify the execution of the Spark or Hadoop jobs submitted using the run command, as shown in the following screenshot.

Summary
In this blog post, I demonstrated how to use the System Manager Run Command to submit Hadoop and Spark jobs on Amazon EMR without a SSH key. Results of Run Command execution are persisted in an Amazon S3 bucket. Systems Manager Run-Command provides a secure way to perform Amazon EMR operations and administration, and to install new software by executing shell scripts without SSH.
Please visit AWS documentation to learn more about System Manager functionality . To run remote commands on EC2 instance please read the document
About the Author

Suresh Patnam is a Senior Data Architect – Big Data at AWS. He works with customers in their journey to the cloud with a focus on Big data, Data Lakes, and Data Strategy. In his spare time, Suresh enjoys playing tennis and spending time with family.