AWS Cloud Operations Blog
Manage Amazon EC2 instance clock accuracy using Amazon Time Sync Service and Amazon CloudWatch – Part 1
This two-part series discusses the measurement and management of time accuracy on Amazon EC2 instances. Part 1 covers the important concepts related to system and reference time. Part 2 covers the mechanism of measure, monitor, and maintain accurate system time on EC2 instances.
A large and diverse set of customer workloads depends on the observed clock accuracy of Amazon Elastic Compute Cloud (Amazon EC2) instances compared to a reference time or true time. Data processing, scientific computing, and transaction processing workloads are good examples because inaccurate time can have huge negative consequences on generated results. Inaccurate system time can produce unreliable timestamps and security tokens, sync failures, and application errors upstream. Amazon Time Sync Service, a time synchronization service that is delivered over the Network Time Protocol (NTP), was launched in November 2017 to help instances maintain accurate time. Amazon Time Sync is used by EC2 instances and other AWS services. It uses a fleet of redundant satellite-connected and atomic clocks in each Region to deliver time derived from these highly accurate reference clocks. This service is provided at no additional charge. It is available to all EC2 instances in all AWS Regions and the AWS GovCloud (US) Regions.
Without active correction, the time on instances’ clock would drift due to a number of factors, including ambient temperature. The periodic synchronization to an NTP server corrects for this deviation, but is not perfect due to the approximation of latencies introduced while querying a remote system over a network. For time-sensitive workloads, customers are interested in monitoring the accuracy of system times in their fleet and want to be alerted when the difference between reference time and system time exceeds a threshold. In this post, I show how you can use Amazon CloudWatch to alert you when the time differences exceed a tolerable threshold.
Figure 1 shows an example of an Amazon CloudWatch dashboard with graphs for two alarms and a CloudWatch composite alarm, which aggregates the instance alarm notifications to reduce alarm noise. Each graph represents the time drift metric on an EC2 instance and a 1millisecond (ms) alarm threshold for the metric.
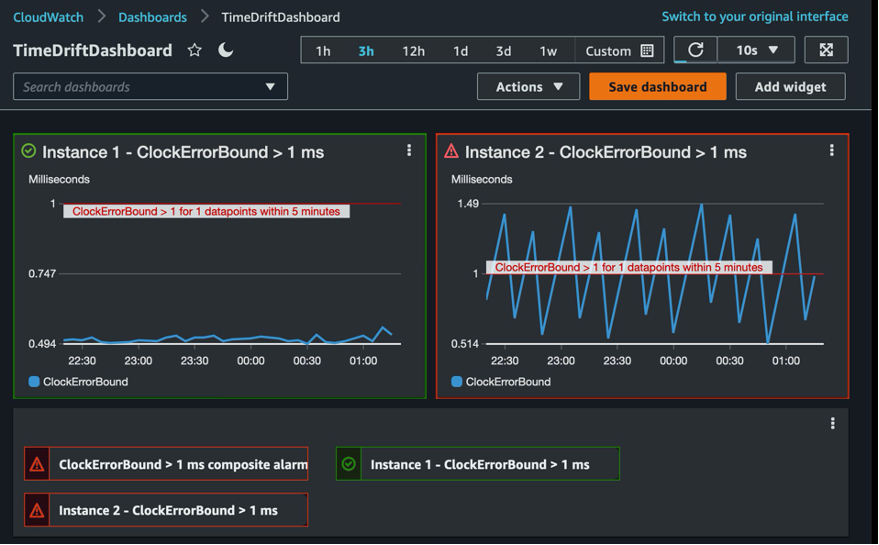
Figure 1: Amazon CloudWatch dashboard displaying alarms and metrics
Time concepts and terminology
The following terminology helps you understand and make an accurate assessment of your instance time accuracy.
Reference time: The basis of clock accuracy. Most time services, including the Amazon Time Sync Service, use the Coordinated Universal Time (UTC) global standard through NTP.
Stratum levels: Used to define the hierarchy of the network in an NTP setup. Stratum 0 refers to the reference clock. The typical sources for stratum 0 are GPS or atomic clocks. The device that embeds the stratum 0 and serves time over the network is called stratum 1. The server that synchronizes time with stratum 1 is called stratum 2. For example, in the Amazon Time Sync Service, the stratum 1 devices are the fleet of satellite-connected and atomic reference clocks used by the service.
Accuracy (offset to UTC): Clock accuracy is generally defined as the offset to UTC. Because of network delays and network noise, it is difficult to measure the offset to UTC in an NTP network. This difficulty arises because NTP packets, which contain timestamp data, face delays as they travel between the NTP client and NTP server. These delays can be reliably measured with perfect clocks. As an alternative, we use the concept of clock error bound to determine a confidence interval that contains the actual offset to UTC.
Clock error bound: Clock accuracy is a measure of clock error, typically defined as the offset to UTC. This clock error is the difference between the observed time on the computer and reference time (also known as true time). But it is often approximated to the time of the reference clock (for example, GPS satellites, atomic clocks). The clock error is inherently driven by the drift of the hardware oscillator driving the host, and cannot be measured without specialized equipment. Network delays and variabilities make it difficult to measure the clock accuracy with certainty.
In an NTP architecture, this error can be bounded using three measurements that are defined by the protocol:
- Local offset (the system time): The residual adjustment to be applied to the operating system clock.
- Root dispersion: The accumulation of clock drift at each NTP server on the path to the reference clock.
- Root delay: The accumulation of network delays on the path to the reference clock.
ClockErrorBound(?) = Local Offset + Root Dispersion + (0.5 * Root delay)

Figure 1: the ClockErrorBound (?) provides a bound on the worst case offset of a clock with regard to “true time”.
The combination of local offset, root dispersion, and root delay provides us with a clock error bound. For a given reading of the clock C(t) at true time t, this bound makes sure that true time exists within the clock error bound. The clock error bound is used as a proxy for clock accuracy and measures the worst case scenario (see Figure 1). Therefore, clock error bound is the main metric used to determine the accuracy of an NTP service.
Conclusion
In this post, I discussed important time measurement concepts and using ClockErrorBound (?) as a measure of time accuracy. Part 2 of this series will describe the mechanism by which time can be measured, monitored, and synchronized on EC2 instances. You can read more about using Amazon Time Sync Service and Amazon CloudWatch to manage time accuracy in part 2 of this series.