Networking & Content Delivery
How to optimize content for search engines with AWS WAF Bot Control and Amazon CloudFront
Search engine crawlers – a special bot type used to index your site – are very important visitors. They make sure that your content is searchable by end users. If a crawler can’t easily read your content, then any updates you make might not be immediately reflected in the search results. Depending on the algorithms that the search engine uses, it could also affect where you appear in search results – your search ranking.
Therefore, it’s important to make sure that search engine crawlers can read your content without additional processing, and that they can access your content as quickly as possible.
In this post, I will outline the content types that search engines can have difficulty with, and the methods that you can use to work around this. I will discuss how you can identify search engines, as well as the impact on your ability to cache content in a Content Delivery Network (CDN). Then, I will walk you through how to use AWS Web Application Firewall (WAF) Bot Control to reliably identify search engines, and how to use Amazon CloudFront with Lambda@Edge to direct them to an optimized version of your content, all while maximizing use of the CDN cache.
According to W3Techs, approximately 97% of all websites today use JavaScript. This enables otherwise static websites to transform into responsive web applications by running code inside of the user’s browser. JavaScript is commonly used to generate HTML content and display it in the browser, also known as client-side rendering. Single Page Applications also make extensive use of JavaScript to render content as the user interacts with the application.
JavaScript is great for human visitors – but what about search engine crawlers? Most search engines can deal with JavaScript, but usually they must perform additional processing to render the content before they can parse it. However, not all of them can do it successfully all of the time. Crawlers usually have limited time and compute resources, so they will often queue the page for rendering first, and then parse it when rendering is complete. This can result in a delay between publishing your content and having it appear in search results. Therefore, search engines actually recommend not serving them JavaScript and using dynamic rendering instead.
To use dynamic rendering for search engines, you must first identify them. The most common way of doing this is by inspecting the user-agent header. If the header value indicates that the visitor is a search engine crawler, then you can route it to a version of the page which can serve a suitable version of the content – a static HTML version, for example.
If you’re using a CDN, then using the user-agent header to identify search engines will impact caching. You would need the CDN to serve a different version of each object for each different value of the user-agent header. In other words, the user-agent header must form part of the cache key. The problem here is that there are numerous potential values for the user-agent header – millions, in fact. The CDN would need to make a request to the origin for every value of user-agent for every object. This would increase the cost of running your origin servers, as they must respond to a larger number of requests. Moreover, it would increase the response times for users, as it would be less likely that their requests could be served from the cache, and they would need to wait while the object is fetched from the origin. In other words, your cache hit ratio would be lower.
By using AWS WAF Bot Control, you can accurately identify search engine crawlers without relying on inspecting the user-agent header, or needing to include it in the cache key for the CDN.
AWS WAF Bot Control analyzes HTTP requests to identify the source and purpose of a bot. It can identify bots and categorize them based on their type – for example: scraper, SEO, crawler, or site monitor. When it identifies a bot, Bot Control adds a label to the request that you can utilize later on in a custom WAF rule.
Now I will walk you through how to enable AWS WAF Bot Control to label your traffic. You will learn how to add a custom WAF rule that will evaluate the labels and add a new, custom request header if Bot Control identified a search engine bot. And you will also learn how to add your custom header to the cache key for a CloudFront distribution.
Furthermore, you’ll learn how to send bot traffic to an alternate origin (one that is configured to serve static HTML, for example) by using Lambda@Edge to inspect the custom header.
The resulting configuration will look like this:
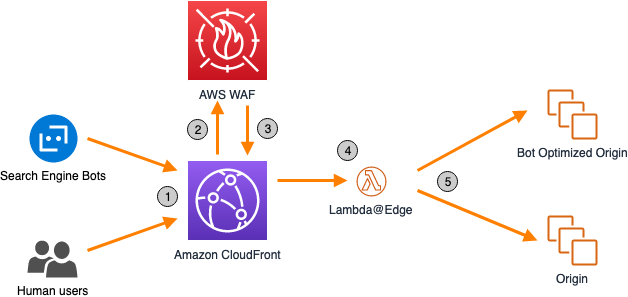
Figure 1 – Diagram showing request flow from human and search engine visitors
- Both bots and human users make requests to a CloudFront distribution.
- AWS WAF inspects each request, using Bot Control to identify bots and adds labels to the requests.
- AWS WAF inspects the labels and adds a custom HTTP header into the request if the labels indicate that a search engine made the request.
- When CloudFront requests objects from the origin, Lambda@Edge inspects the request, looking for the custom header. If it’s present, Lambda@Edge modifies the origin, instructing CloudFront to send the request to the bot-optimized origin. CloudFront sends all other requests to the default origin.
Note that while you are changing the origin for the purposes of this example, it’s also possible to use a single origin and differentiate between the website versions (human optimized, bot optimized) in other ways. For example, you can do this by modifying the URI path or by using an HTTP request header. This is discussed in more detail in the Building Low Latency Websites breakout session from Re:Invent 2021.
Additionally, because search engines don’t typically receive dynamic content, you can also maximize the Time-to-Live (TTL) for your static HTML content via the cache-control header. This increases the opportunity for search engines to receive your content from the CDN cache, which in turn provides faster response times. This may improve your SEO rankings, as search engines tend to favor fast responses.
Walkthrough
Creating a WAF WebACL
In this section, you’ll create a new WAF WebACL and configure Amazon Bot Control to identify bots. You’ll also create a custom rule to insert a new request header when Bot Control identifies a search engine crawler.
To create a new WebACL and configure Amazon Bot Control:
- Sign in to the AWS Management Console and open the AWS WAF console here.
- In the navigation pane, choose WebACLs, then choose Create web ACL.
- In the Web ACL details dialog box, do the following:
- For Resource type, choose CloudFront distributions.
- Choose a name (eg. SearchBot-ACL) and a Cloudwatch metric name.
- Choose Next.
- In the Rules dialog box, choose Add rules, Add managed rule groups.
- Expand the AWS managed rule groups dialog box and turn on Add to web ACL next to Bot Control.
You’ll notice that Bot Control is a paid rule group – for pricing information, refer here.
Note that, by default, this rule group will block all bot traffic. You’ll change this behavior so that you can evaluate Bot Control without blocking any requests.
- Choose the Edit button underneath Add to web ACL.
- Turn on Set all rule actions to count
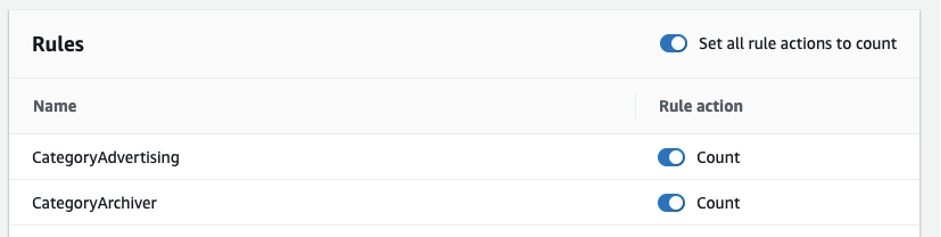
Figure 2: Screenshot showing all rule actions set to count
- At the bottom of the page, choose Save Rule.
- At the bottom of the page, choose Add Rules.
Bot Control identifies various bots and bot categories, and assigns labels to requests based on what was identified. You can use the labels in other WAF rules for fine-grained control over bot traffic to your applications. Now you’ll configure AWS WAF to evaluate the labels in a custom rule, and add a new request header if Bot Control identifies a search engine crawler.
To configure a custom rule to evaluate labels and add a header (visual rule builder):
- On the Add rules and rule groups page, choose Add rules, Add my own rules and rule groups.
- Use the rule builder visual editor to construct your rule:
- For Name, choose a name (eg. Add-Bot-Header).
- For Type, choose Regular Rule.
- For If a request, choose Matches at least one of the statements (OR).
- In the Statement 1 dialog box, do the following:
- For Inspect, choose Has a label.
- For Match scope, choose Label.
- For Match key, choose awswaf:managed:aws:bot-control:bot:category:search_engine.
- In the Statement 2 dialog box, do the following:
- For Inspect, choose Has a label.
- For Match scope, choose Label.
- For Match key, choose awswaf:managed:aws:bot-control:bot:category:seo.
- In the Action dialog box, do the following:
- For Action, choose Allow.
- Expand Custom request and choose Add new custom header.
- For Key, enter a header name (eg. SearchBot).
Note that AWS WAF automatically prefixes your custom header name with x-amzn-waf- .
-
-
- For Value, enter True.
-
- At the bottom of the page, choose Add rule.
To configure a custom rule to evaluate labels and add a header (rule json editor):
- On the Add rules and rule groups page, choose Add rules, Add my own rules and rule groups.
- For Rule builder, choose Rule JSON Editor.
- Copy and paste the following JSON snippet into the editor in the console:
{
"Name": "Add-Bot-Header",
"Priority": 0,
"Action": {
"Allow": {
"CustomRequestHandling": {
"InsertHeaders": [
{
"Name": "SearchBot",
"Value": "True"
}
]
}
}
},
"VisibilityConfig": {
"SampledRequestsEnabled": true,
"CloudWatchMetricsEnabled": true,
"MetricName": "Add-Bot-Header"
},
"Statement": {
"OrStatement": {
"Statements": [
{
"LabelMatchStatement": {
"Scope": "LABEL",
"Key": "awswaf:managed:aws:bot-control:bot:category:search_engine"
}
},
{
"LabelMatchStatement": {
"Scope": "LABEL",
"Key": "awswaf:managed:aws:bot-control:bot:category:seo"
}
}
]
}
}
}
- At the bottom of the page, choose Add rule.
To finalize your new WebACL:
- In the Default web ACL action for requests that don’t match any rules dialog box, for Default action, choose Allow.
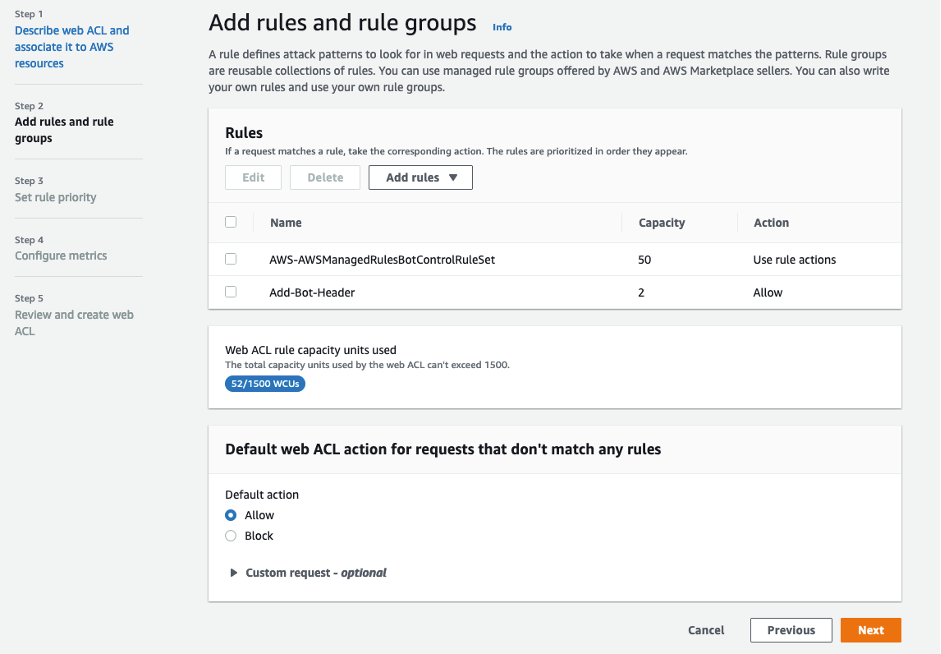
Figure 3: Managed & Custom WAF rules with default action set to Allow
- Choose Next three times to accept the default values on the remaining pages.
- Choose Create web ACL.
Now you have AWS WAF configured to identify and report on various bots, and to insert a new request header x-amzn-waf-searchbot: true on requests from search engine bots.
Next, you’ll create a new Lambda@Edge function to look for the presence of the x-amzn-waf-searchbot header, and send the request to a new custom origin if it’s present.
Creating a Lambda@Edge function
To create the lambda@edge function:
- Open the Lambda console here.
Note that you must use the N. Virginia (us-east-1) region to author Lambda functions for use with Lambda@Edge. See here for further details.
- Choose Create Function.
- Choose Author from scratch.
- In the Basic Information dialog box, do the following:
- For Function name, enter a name for your function (eg. Edge-SearchBots).
- For Runtime, choose Node.js 16.x.
- For Architecture, choose x86_64.
- Under Permissions, expand Change default execution role.
- For Execution role, choose Create a new role from AWS policy templates.
- For Role name, enter a name (eg. EdgeLambda-role).
- For Policy templates, choose Basic Lambda@Edge permissions (for CloudFront trigger).
- Choose Create function.
Refer here for more information on the permissions required for Lambda@Edge.
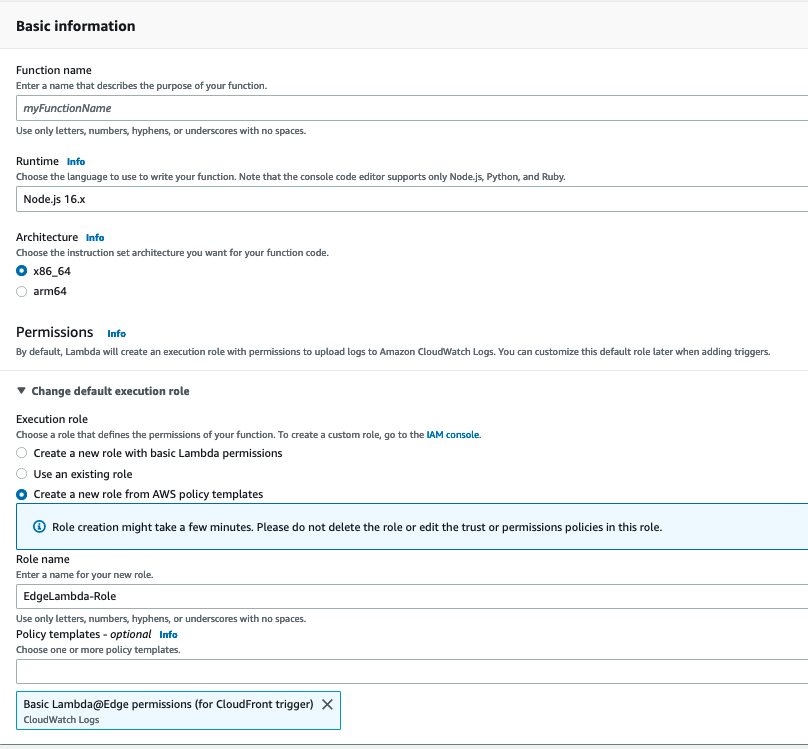
Figure 4: Lambda function configuration
- In the Code source dialog box, replace the sample code in the editor with the code that follows:
exports.handler = (event, context, callback) => {
const SEO_ORIGIN 'seo-origin.example.com';
const CRAWLER_HEADER = 'x-amzn-waf-searchbot';
const {request} = event.Records[0].cf;
if (request.headers[CRAWLER_HEADER]){
request.origin = {
custom: {
domainName: SEO_ORIGIN,
port: 80,
protocol: 'http',
path: '',
sslProtocols: ['TLSv1.2'],
readTimeout: 5,
keepaliveTimeout: 60,
customHeaders: {}
}
};
request.headers.host = [{ key: 'host', value: SEO_ORIGIN}];
}
callback(null, request);
};
- Inside the code block, replace seo-origin.example.com with the DNS name of an origin which should receive requests from search engine crawlers. Make sure that the other settings such as port, protocol, and timeouts are appropriate for your origin.
- Choose Deploy to deploy your code.
- Choose Actions, Publish New Version.
- For Version description, enter a suitable description (eg. v1).
- Choose Publish.
Note that this step is necessary to allow Lambda@Edge to replicate your function code across multiple AWS regions so that it can be used by CloudFront.
- Once the new version of your function has been published, copy the Function ARN and keep it handy, as this will be needed later on when configuring your CloudFront behavior.
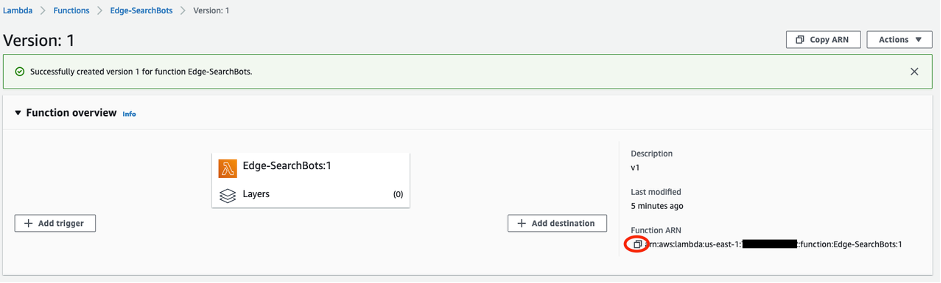
Figure 5: Published function and function ARN
Now you have a Lambda@Edge function and a WebACL created. However, neither have been associated with a CloudFront distribution just yet, so neither is currently in use.
Before you do that, you must add your new header, x-amzn-waf-searchbot, to the cache policy for the appropriate CloudFront behavior(s). This will instruct CloudFront to store a different copy of each object, depending on the value of the header. Because the header can only have two values, true or false, CloudFront will store two copies of each object – one where the header value is true, and another where the header value is false. This is much more efficient than using the user-agent header, where there are numerous potential values.
For this example, you’ll walk through creating a new, custom cache policy that includes the x-amzn-waf-searchbot header. Depending on your requirements, you may need to adjust the other settings, or you might add the custom header to an existing custom policy.
Creating a custom cache policy
To create a custom cache policy:
- Open the CloudFront console here.
- In the navigation pane, choose
- In the Custom policies dialog box, choose Create cache policy.
- For Name, enter a name (eg. Cache-Searchbot-Header).
- In the Cache key settings dialog box, do the following:
- For Headers, choose Include the following headers.
- For Add Header, choose Add custom.
- For Custom header, enter x-amzn-waf-searchbot.
- Choose Add.
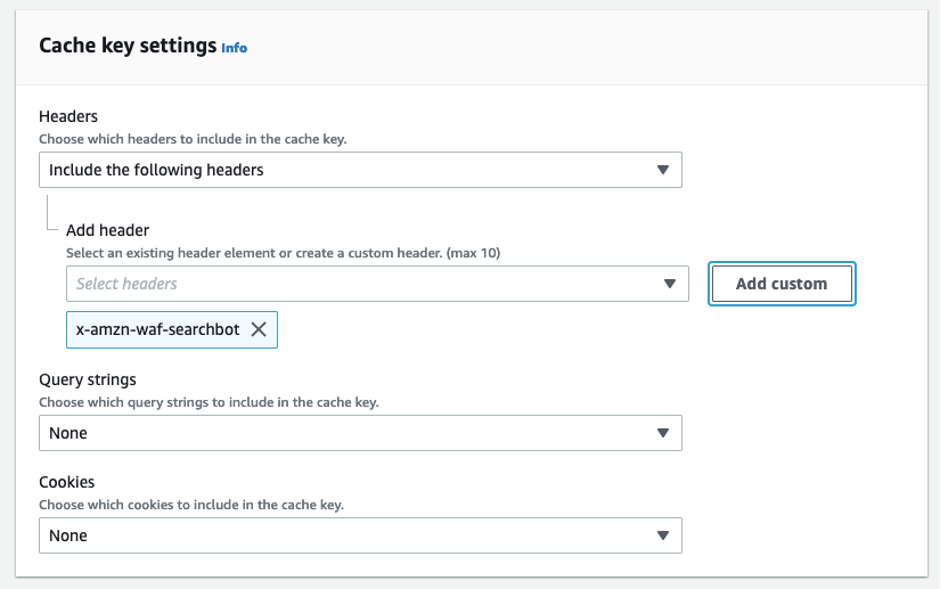
Figure 6: Cache key configuration
- Choose Create.
Now you have all of the components ready to add the new functionality to your CloudFront distribution.
Adding the new functionality to your CloudFront distribution
To associate your WebACL and Lambda@Edge function and cache policy to an existing CloudFront distribution:
- Open the CloudFront console here.
- Choose the ID of the CloudFront distribution to which you wish to apply this functionality.
- In the Settings dialog box, choose Edit.
- For AWS WAF web ACL, choose the Web ACL you created earlier (e.g., SearchBot-ACL).
- At the bottom of the page, choose Save changes.
- Choose the Behaviors tab.
- Choose the behavior that you want to apply this functionality to, then choose Edit.
- For Cache key and origin request, do the following:
- Choose Cache policy and origin request policy (recommended).
- For Cache policy, choose the policy that you created earlier (eg. Cache-Searchbot-Header).
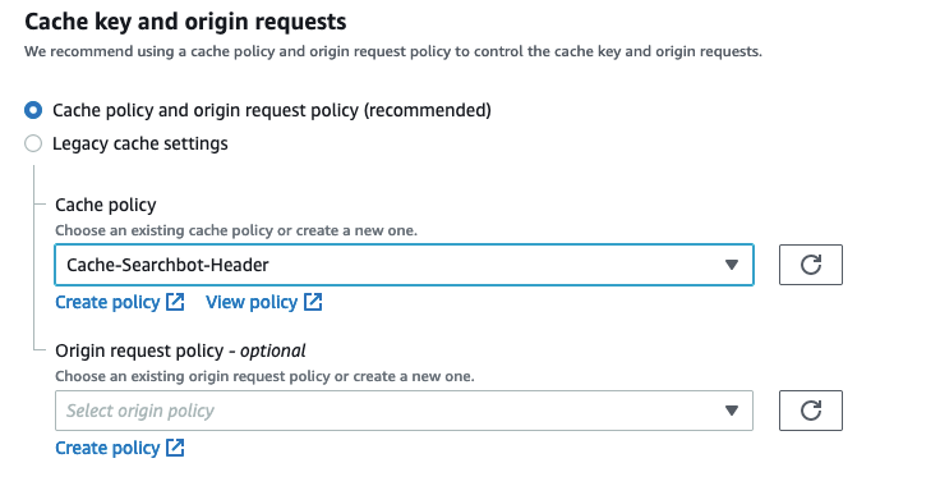
Figure 7: Custom cache policy selected
- For Function Associations, do the following:
- For Origin request, choose Lambda@Edge.
- For Function ARN / Name, paste the ARN of your function’s version that you copied earlier.
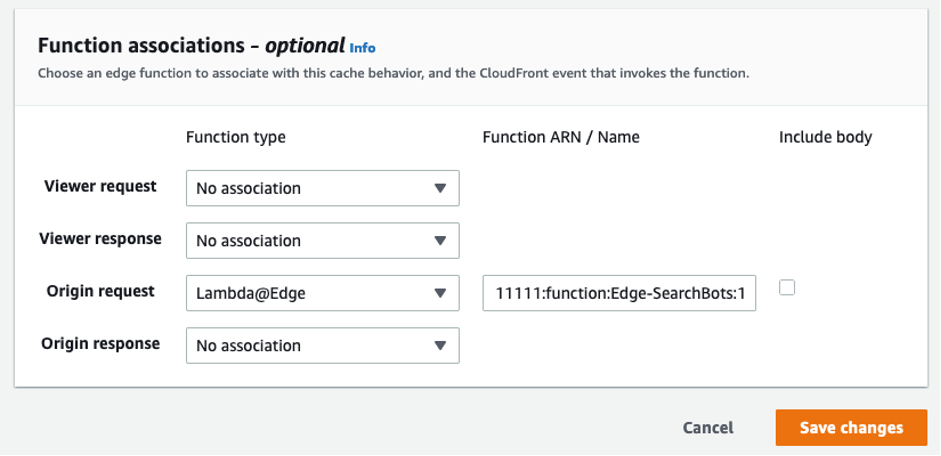
Figure 8: Lambda@Edge function associated with Origin Request
- Choose Save changes.
After a few minutes, your changes will have propagated to all of the CloudFront edge locations, and search engine bots will be sent to your custom origin.
Testing
To test this accurately, you must instruct a search engine to make a legitimate request to your application. This is because AWS WAF Bot Control performs validation on search engine bots. This means that you can’t simply spoof the user-agent header to test. You also can’t attempt to include the x-amzn-waf-searchbot header in your request, as CloudFront will remove it.
Both Google and Microsoft offer consoles that can perform a live test against a URL on your website.
To test using Google:
- Navigate to the search console.
- Choose URL Inspection.
- Enter a URL which will match the CloudFront Behavior that you modified above.
- Choose Test Live URL and View tested page.
To test using Microsoft:
- Navigate to the URL Inspection function in Webmaster Tools.
- Enter a URL which will match the CloudFront Behavior that you modified above.
- Choose Inspect,then Live URL, then View Tested Page.
Make sure that the content of the page received by the search engine matches your expectations. The HTML view should display the static HTML version of the page that you expect, rather than the javascript-enabled version that you would serve to human visitors.
Conclusion
By using AWS WAF Bot Control to identify search engine crawlers, you now have a robust method for identifying bots, rather than relying on the user-agent header alone.
By injecting a new, custom request header in AWS WAF based on the labels applied to traffic by AWS WAF Bot Control, you have been able to optimize your cache key in CloudFront (as compared to including user-agent in the cache key). This increases the likelihood of your content being served from cache, and reduces the number of requests that must be forwarded to your origin.
Rather than inspecting the header in your application code, you have moved this processing into Lambda@Edge, and you can now forward search engine traffic to a different instance of your application, configured specifically to render HTML content. Furthermore, you can increase the TTL of your HTML content in the CloudFront cache through the use of the cache-control header. If the origin can’t add or modify the cache-control header, then you can still optimize this through Lambda@Edge if required.
All of this serves to make sure that search engine crawlers receive your content in the format that works best for them, with the lowest possible response time, while continuing to use JavaScript-based page frameworks for human visitors.

Paul Le Page
Paul Le Page is a Senior Solutions Architect at AWS. He works with enterprise retail customers, helping them with migrations to the cloud and adoption of cloud native services. In his free time, Paul enjoys travel, food and the great outdoors.