Networking & Content Delivery
Implementing long-running TCP Connections within VPC networking
Many network appliances define idle connection timeout to terminate connections after an inactivity period. For example, appliances like NAT Gateway, Amazon Virtual Private Cloud (Amazon VPC) Endpoints, and Network Load Balancer (NLB) currently have a fixed idle timeout of 350 seconds. Packets sent after the idle timeout expired aren’t delivered to the destination.
Some applications or API requests, such as synchronous calls to databases, can have long inactivity periods. If you have a scenario where you must keep an idle TCP connection alive, then this post is for you. This post will demonstrate techniques to keep TCP connections alive for idle connections for cases when applications must keep them open while not generating any traffic on either end of the connection.
Overview
Amazon VPC provides a multitude of networking services such as NLB, Gateway Load Balancer (GWLB), Interface VPC Endpoints, NAT Gateway, and more. In addition, you might have self-managed or on-premises network appliances, such as firewalls. Most of the time, those network appliances have packets flowing back and forth through them. However, in some cases, connections may remain idle for some time without packets being transmitted.
When building a secure cloud environment in Amazon VPC, it’s recommended to host your workloads in a private subnet. Some AWS services may be used to achieve this:
- You can use NAT Gateway for outbound connections. The instances in a private subnet can egress to destinations outside of your VPC, while external entities can’t ingress to the instances behind a NAT Gateway. You can also leverage a private NAT Gateway for private communication, e.g., when attempting to communicate to other resources external to VPCs using a single IP for consolidation reasons.
- Interface VPC Endpoint makes sure that connections to services remain within the AWS private network.
- NLB lets you create a public or private NLB, and expose the service to multiple clients. Then, the NLB sends traffic to targets in a private subnet.
- With GWLB, a transparent bump-in-the-wire device sends traffic to firewall instances for inspection and firewall.
All of the services mentioned above currently have the idle timeout set at 350 seconds. When you have ongoing packet exchange over your TCP connections, with packets being sent in under 350 seconds, everything works as expected. See following diagram for more information.

(Figure 1. Network connection successfully transmits a response after 250 seconds)
Note that other network appliances used in your environment might use different idle timeout settings than the services listed above.
Idle timeout
A TCP connection that remains idle for a period of time can timeout. When the timeout occurs, the network appliance will no longer consider this connection as active and will no longer deliver packets in either direction. What would happen in this case depends on the specific implementation of that network appliance. When this happens with NAT Gateways, NLBs, and interface VPC Endpoints, the transmitting end of the connection receives a TCP RST packet back from the appliance which timed out. However, the remote end won’t receive any TCP packets. Therefore, it still may consider the connection to be in an established state, even though it’s no longer usable, until it also times out.
Let’s explore an example. The client has sent a request to server and is waiting for a server response. The server is processing this request, and it isn’t transmitting anything back to the client for an extended period of time. The connection timeout occurs at the network appliance used between the client and server, but neither side is aware of it. The server continues to process the request not knowing that the connection is already closed. Once the server completes processing and starts to transmit a response back, it will receive an RST packet from the network appliance, notifying it that the connection is closed. This can result in a waste of resources and a redundant load on the server.
On the other side, the client will continue waiting for the server response. Since the connection has already timed out, the client will never receive any response back from the server. Assuming that there’s a request timeout defined explicitly on the client side, the request will eventually timeout. However, until that happens, the client will continue to wait and potentially use resources while expecting a response that will never arrive.

(Figure 2. Network connection is closed after 350 seconds. Response cannot be transmitted)
The idle timeout is important to make sure that stale connections are destroyed in a timely manner. However, you might need to wait for a server response for a longer period of time. To address this, you must make sure that the connection that you want to remain active doesn’t remain idle for longer than what was defined as the idle timeout on network appliances. This can be achieved with TCP Keepalive.
Note that for the GWLB, once a TCP flow is idle for longer than the idle timeout, the connection is removed from GWLB’s connection state table. As a result, the subsequent packets for that flow are treated as a new flow and can be sent to a different healthy firewall instance. Although this doesn’t produce a TCP reset from the GWLB end, it may have a similar effect, resulting in the flow timing out, as the other firewall instance may not be expecting the traffic and can drop all subsequent packets. Moreover, TCP Keepalive can help in this scenario. Alternatively, depending on your requirements, you can consider changing your GWLB flow stickiness configuration to make sure that all of the packets from a certain source and destination are always delivered to the same appliance. This works independent of the timeout. Check the GWLB documentation to understand more about GWLB flow stickiness.
TCP Keepalive
TCP Keepalive is a mechanism that can keep idle TCP connections alive. The mechanism is implemented according to the RFC 1122. The Keepalive probe is sent with no payload Length 0 (Len=0) and the Sequence number (Seq No) as the Sequence number that the receiver is expecting subtracted by 1 (SEG.SEQ = SND.NXT-1). The remote node will simply acknowledge the packet by replying it with a TCP ACK, since the segment was mimicking a retransmission of another previously acknowledged segment.
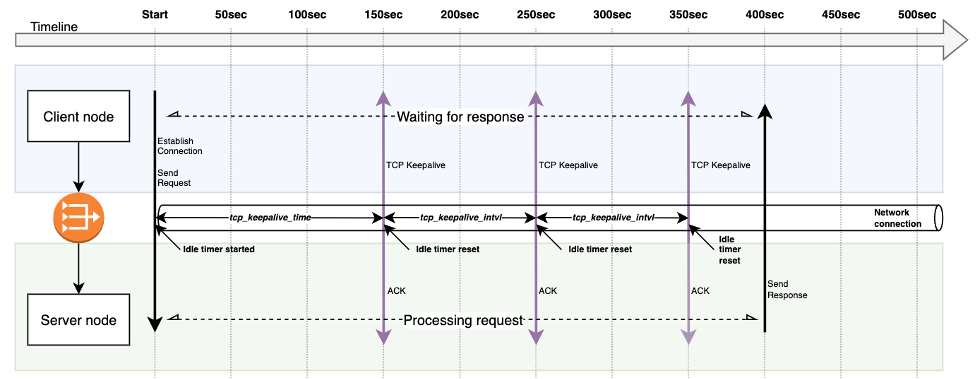
(Figure 3. TCP Keepalive prevents connection from being closed due to idle timeout. Response is successfully transmitted after 400 seconds)
By default, Linux-based OSes has the TCP Keepalive configured to be triggered after 7200 seconds (2 hours). This is significantly higher than the idle timeout settings you may find with network appliances running in the cloud.
In the following guide, we’ll explore how to enable and configure the TCP Keepalive. This will require you to make two updates:
- Configure TCP Keepalive settings in node OS – we’ll consider doing this with Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Elastic Kubernetes Service (Amazon EKS).
- Enable TCP Keepalive in an application – we’ll consider doing this with AWS Command Line Interface (AWS CLI), AWS SDK for Python, and AWS SDK for Java
TCP Keepalive in a Linux-based OS
TCP Keepalive works by “probing” the other side of the connection when it has detected an idle state:
- Each TCP connection is associated with a set of settings in the Kernel. Whenever a new socket is created with the SO_KEEPALIVE option, the Kernel settings are applied.
- Each connection in an ESTABLISHED state is tracked and associated to a timer. When a connection is idle for longer than the configured period, the OS sends the remote node a keepalive probe packet with no data in it and the ACK flag turned on.
- Because of the TCP/IP specifications, this is handled similarly to a duplicate ACK. The remote node will simply reply with no data and an ACK packet. The remote node doesn’t need to implement anything on their end, and this logic is implemented as part of the TCP protocol.
For Linux-based OS, there are three OS level parameters to configure the TCP Keepalive behavior:
- tcp_keepalive_time – how long the connection must be idle before TCP Keepalive probes are sent.
- tcp_keepalive_intvl – the interval between sending Keepalive probes, as long as the connection is idle. This parameter works in conjunction with the tcp_keepalive_probes to declare a remote peer dead.
- tcp_keepalive_probes – the total number of probes that will be sent out and not receive an acknowledgement before the connection is declared dead.
TCP Keepalive is configured as Linux Kernel parameters and is available at /proc/sys/net/ipv4/.
The common default values on a Linux-based system can be seen above. The first two values are in seconds, and the third one is an absolute number. These settings mean that a connection that was idle for 2 hours will start sending TCP Keepalive probes, and after approximately an additional 11 minutes (9 retries * 75 seconds) without receiving any acknowledgement from the remote end, the connection will be closed.

(Figure 4. The TCP Keepalive configuration parameters and workflow)
Note that modifying TCP Keepalive changes the default system behavior. Make sure that you understand the consequences and have a roll-back strategy. The values are heavily dependent on your use-case. Too many probes may lead to higher resource usage and traffic congestion, while too few probes may lead to connections being closed earlier, in the event of packet loss for example.
Configuring TCP Keepalive for Linux EC2 instances
The following steps were validated on an EC2 instance running Amazon Linux 2.
With the following configuration, the software that uses the SO_KEEPALIVE option on the socket will start sending TCP Keepalive probes after 45 seconds. It will keep sending these probes every 45 seconds as long as the connection remains idle – until the remote peer has replied. If the remote peer never replies for 9 consecutive probes, then the connection is declared closed. If some data packets will be sent through the connection, then this will also reset the tcp_keepalive_time and the whole process starts from the beginning.
To persist the TCP Keepalive configuration settings across system reboots, you must update (or create if it doesn’t exist) the /etc/sysctl.conf file. Append the following content to the file:
Once the /etc/sysctl.conf file is saved, you can run the sudo sysctl -p command for changes to take immediate effect and be persisted across reboots. We recommend that you reboot your system after performing this step to validate that the new settings were applied.
Configuring TCP Keepalive for Amazon EKS clusters
Configuring TCP Keepalive for Amazon EKS managed node groups requires the cluster admin to explicitly allow updating related sysctls during the node group creation. When using the eksctl CLI to create your cluster, add the following snippet to your managed node group:
After the cluster is provisioned, create a pod security policy that will allow pods to use allowed sysctls. You must have proper access permissions to configure this if you’re not the cluster admin.
Now you can configure TCP Keepalive sysctls per pod by setting the security context in your pod definitions:
Enabling TCP Keepalive in your applications
Configuring the OS level sysctls isn’t enough. To see the effect, you must also make sure that your applications have TCP Keepalive enabled.
The following examples demonstrate changes required when using AWS CLI and SDKs to synchronously invoke an AWS Lambda function, which can run for up to 15 minutes (900 seconds). Based on your use case, you might need to do similar adjustments for other scenarios in other client libraries that you’re using. See this article for additional information about configuring AWS SDK timeouts.
AWS CLI
Update the config file located at ~/.aws/config. Add the tcp_keepalive=true property. For additional supported configuration properties, see the AWS CLI docs.
When making requests with AWS CLI, use the cli-read-timeout parameter to define the socket read timeout (defaults is 60 seconds).
aws lambda invoke --function-name my-func out.txt --cli-read-timeout 900
AWS SDK for Python
AWS SDK for Python, also known as boto3, gets the TCP Keepalive configuration from the ~/.aws/config file. See the Using a configuration file doc for more details. Add tcp_keepalive=true to ~/.aws/config, and set the value for socket read timeout using the botocore.config.Config instance.
AWS SDK for Java
The default Apache HTTP Client used internally by AWS SDK for Java has TCP Keepalive disabled. Create a custom ApacheHttpClient instance with Keepalive enabled, and configure the timeouts.
The ApacheHttpClient.Builder class is a part of the software.amazon.awssdk:apache-client package. A similar technique is applicable when using NettyNioAsyncHttpClient and UrlConnectionHttpClient.
Conclusion
This blog covers configuring the OS-level TCP Keepalive settings for Amazon EC2 instances and Amazon EKS clusters, as well as enabling TCP Keepalive in you applications using AWS Command Line Interface (AWS CLI), AWS SDK for Python, and AWS SDK for Java.
You can use this technique to maintain long-running connections originating from your workloads behind a NAT Gateway, Interface VPC Endpoint, or any other similar network appliance that terminates idle connections.
About the authors

Anton Aleksandrov
Principal Solutions Architect, Serverless, AWS

Felipe da Silva
Senior Solutions Architect, ELB, AWS

Hemanth AVS
Senior Solutions Architect, Containers, AWS