AWS Open Source Blog
Category: Compute

Continuous Integration using Jenkins and HashiCorp Terraform on Amazon EKS
This blog post is the result of a collaboration between Amazon Web Services and HashiCorp. HashiCorp is an AWS Partner Network (APN) Advanced Technology Partner with AWS Competencies in both DevOps and Containers. Introduction Customers running microservices-based applications on Amazon Elastic Kubernetes Service (Amazon EKS) are looking for guidance on architecting complete end-to-end Continuous Integration […]

fMRI data preprocessing on AWS using fMRIprep
A typical fMRI study often produces imaging data of terabytes or more. Storing and preprocessing this data can be challenging on a single computer because it often has neither enough disk space to store the data nor enough computing power to preprocess it. Traditionally, researchers use a combination of cloud-based storage and on-premises high-performance clusters […]

Deploying an HPC cluster and remote visualization in a single step using AWS ParallelCluster
Since its initial release in November 2018, AWS ParallelCluster (an AWS-supported open source tool) has made it easier and more cost effective for users to manage and deploy HPC clusters in the cloud. Since then, the team has continued to enhance the product with more configuration flexibility and enhancements like built-in support for the Elastic […]
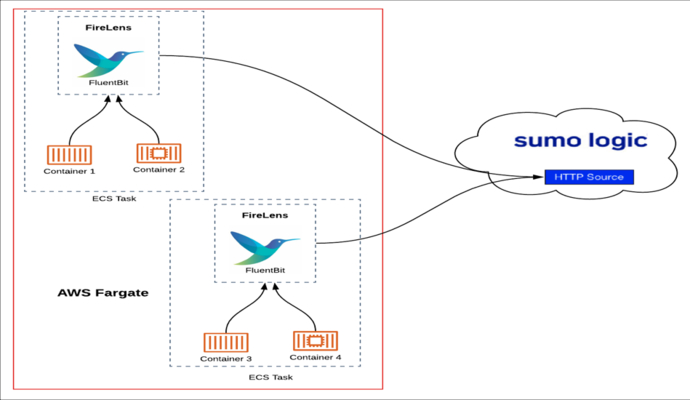
AWS Fargate container logs collection and analysis with AWS FireLens and Sumo Logic
AWS Fargate is a compute engine for Amazon ECS that allows you to run containers without having to manage servers or clusters. Fargate manages provisioning, configuration, and scaling of the clusters. With Fargate, you can focus on your application design and implementation instead of worrying about the infrastructure. In this post, we’ll provide an overview […]

Splitting an application’s logs into multiple streams: a Fluent tutorial
Not all logs are of equal importance. Some require real-time analytics, others simply need to be stored long term so that they can be analyzed if needed. In this tutorial, I will show three different methods by which you can “fork” a single application’s stream of logs into multiple streams which can be parsed, filtered, […]

Continuous delivery of container applications to AWS Fargate with GitHub Actions
At the day two keynote of the GitHub Universe 2019 conference on Nov 14, Amazon Web Services announced that we have open sourced four new GitHub Actions for Amazon ECS and ECR. Using these GitHub Actions, developers and DevOps engineers can easily set up continuous delivery pipelines in their code repositories on GitHub, deploying container workloads to Amazon Elastic Container […]

Continuous Delivery using Spinnaker on Amazon EKS
I work closely with partners, helping them to architect solutions on AWS for their customers. Customers running their microservices-based applications on Amazon Elastic Kubernetes Service (Amazon EKS) are looking for guidance on architecting complete end-to-end Continuous Integration (CI) and Continuous Deployment/Delivery (CD) pipelines using Jenkins and Spinnaker. The benefits of using Jenkins include that it […]

How to run AWS ParallelCluster from AppStream 2.0 and share S3 data
High Performance Computing (HPC) cluster administrators typically need a way to let their users to create HPC clusters quickly and easily from a common Windows desktop, while enforcing security, isolation, scalability, and cost effectiveness. This important step could be part of a wider user workflow, or an established procedure followed by HPC users to start […]

How AWS built a production service using serverless technologies
Our customers are constantly seeking ways to increase agility and innovation in their organizations, and often reach out to us wanting to learn more about how we iterate quickly on behalf of our customers. As part of our unique culture (which Jeff Barr discusses at length in this keynote talk), we constantly explore ways to […]
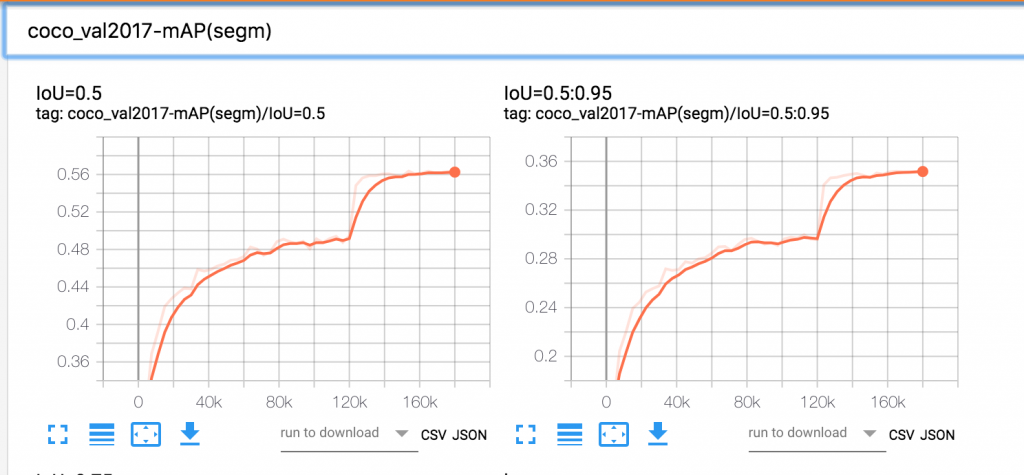
Distributed TensorFlow training using Kubeflow on Amazon EKS
Training heavy-weight deep neural networks (DNNs) on large datasets ranging from tens to hundreds of GBs often takes an unacceptably long time. Business imperatives force us to search for solutions that can reduce the training time from days to hours. Distributed data-parallel training of DNNs using multiple GPUs on multiple machines is often the right […]