AWS Open Source Blog
How AWS built a production service using serverless technologies
Our customers are constantly seeking ways to increase agility and innovation in their organizations, and often reach out to us wanting to learn more about how we iterate quickly on behalf of our customers. As part of our unique culture (which Jeff Barr discusses at length in this keynote talk), we constantly explore ways to move faster by using new technologies.
Serverless computing is one technology that helps Amazon innovate faster than before. It frees up time for internal teams by eliminating the need to provision, scale, and patch infrastructure. We use that time to improve our products and services.
Today, we are excited to announce that we have published a new open source project designed to help customers learn from Amazon’s approach to building serverless applications. The project captures key architectural components, code structure, deployment techniques, testing approaches, and operational practices of the AWS Serverless Application Repository, a production-grade AWS service written mainly in Java and built using serverless technologies. We wanted to give customers an opportunity to learn more about serverless development through an open and well-documented code base that has years of Amazon best practices built in. The project was developed by the same team that launched the AWS Serverless Application Repository two years ago, and is available under the Apache 2.0 license on GitHub.
Open source has always been a critical part of AWS’ strategy, as the Firecracker example illustrates. Open source is a more efficient way to collaborate with the community, and we view our investments in open source as a way to enable customer innovation. While we have dozens of example serverless applications available on GitHub and many reference architectures, this is our first attempt to open source a set of serverless application components inspired by the implementation of a production AWS service. Because the focus is on learning, we have made only a few service operations available on GitHub. For example, to show how we developed a request and response architecture, we published code for the create-application operation of the service and excluded similar operations like put-policy or get-template — we used the service to draw motivation from real-world scenarios in developing this project. You can study the code, make changes locally, deploy an inspired version of the service in your AWS account, and repeat this cycle to gain further insight into how we develop, test, and operate our production services using serverless technologies.
A quick note about the AWS Serverless Application Repository, and why we used it as a reference to develop this project:
The AWS Serverless Application Repository enables teams, organizations, and individual developers to store and share reusable serverless applications, and easily assemble and deploy serverless architectures in powerful new ways. The service implements common request/response patterns, makes use of event-driven systems for asynchronous processing, and uses a component architecture to reduce coupling and improve scaling dimensions. Learning how to implement these patterns, using best practices, is a common ask from our customers.
The diagram below represents the high-level architecture of the open source project, and closely resembles the production architecture of the service. Let’s learn more about the things we have made available for you to study from on GitHub.
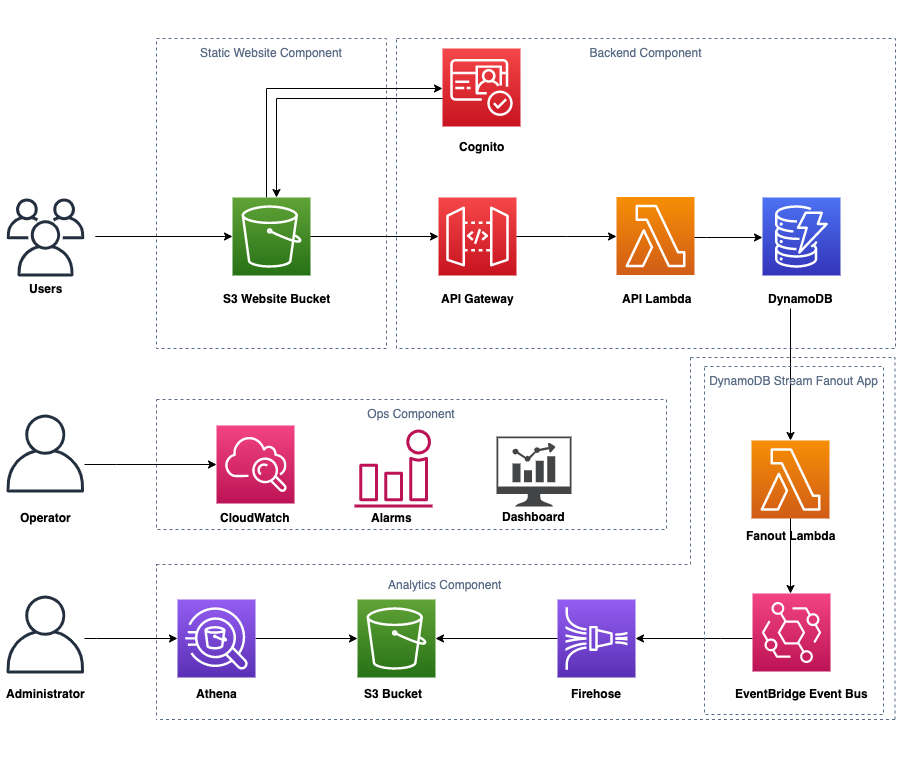
The open source project has four core components: a static website (front-end), a back-end, an operations component, and an asynchronous analytics component. This modular architecture helps minimize customer impact in the event of failures, and is key in iterating quickly and independently on components. Each component has its own designated folder to help organize its code, dependencies, and infrastructure-as-code template, closely resembling the layout of the production service. Within each folder, a suite of unit and integration tests is provided to help ensure that changes are thoroughly tested before being deployed. CI/CD pipeline templates are available for individual components to give you the flexibility of setting up a pipeline for the specific components you wish to deploy.
Note: While the project is designed for learning, each component is built with production quality in mind. The components extracted from the service can also be deployed independently as apps via the AWS Serverless Application Repository.
This post will provide a detailed explanation of the back-end component. A version of this is also available in the project wiki.
Back-end (request/response)
It is very common for applications to handle user requests, process data, and respond with success or error. Users must also be authenticated, which requires ways to communicate with APIs (usually via a web interface). For example, the create-application operation of the service is exposed as an Amazon API Gateway API. Customers interact with the service using the AWS SDK and the AWS console, where auth(n) and auth(z) are managed via AWS Identity and Access Management (IAM). Requests made to the service get routed to AWS Lambda where the business logic is executed, and state is managed via Amazon DynamoDB. The open source project captures the request/response architecture of the production service almost identically, except that we show how to use Amazon Cognito for authentication and authorization. The following diagram captures the architecture for the back-end component released with this open source project.
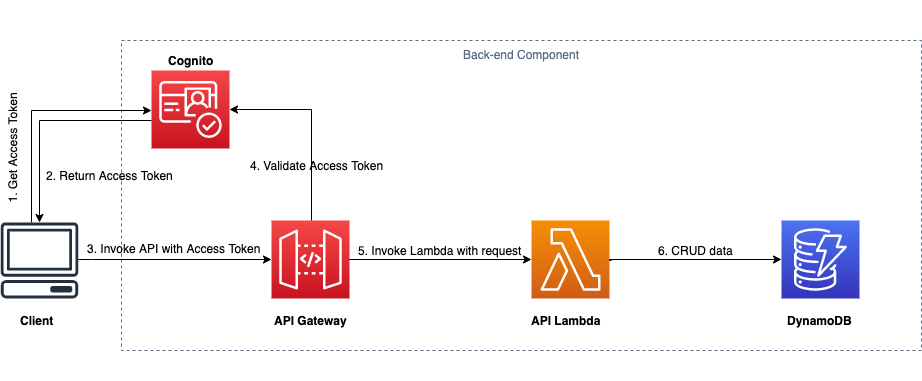
The back-end component implements the following operations:
- CreateApplication: creates an application
- UpdateApplication: updates the application metadata
- GetApplication: gets the details of an application
- ListApplications: lists applications that you have created
- DeleteApplication: deletes an application
We used the Open API’s (Swagger) specification to define our APIs, and used the Swagger codegen tool to generate server side models (for input/output), and JAX-RS annotations for the APIs listed above.
Note: JAX-RS (Java API for RESTful Web Services) is a Java programming language API spec that provides support in creating web services according to the Representational State Transfer architectural pattern. Jersey, the reference implementation of JAX-RS, implements support for the annotations defined in JSR 311, making it easy for developers to build RESTful web services using the Java programming language.
Let’s walk through a few sections of code that show how requests get routed and then processed by the appropriate Java methods of the application. It will be helpful to see how we used existing Java frameworks to help developers stay focused on writing just the business logic of the application.
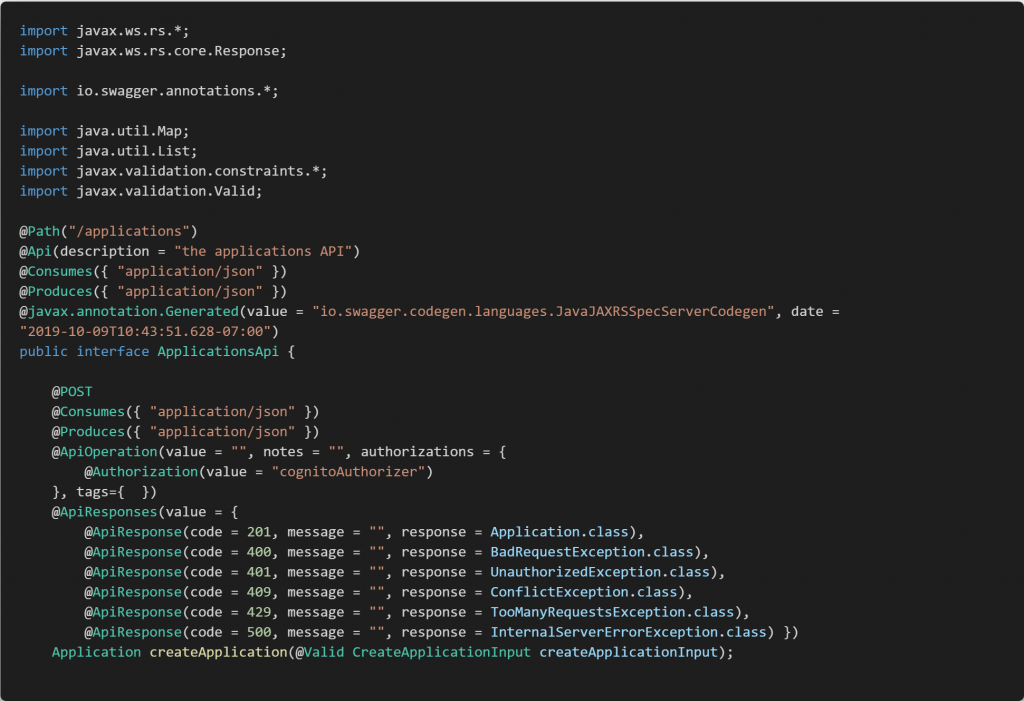
The code snippet below shows JAX-RS annotations defined for the create-application API in the ApplicationsApi Java Interface generated from the API spec.
The ApplicationService class contains all business logic for the APIs. This class implements the methods defined by the ApplicationsApi Java interface. The code snippet below shows the implementation of the create-application API: a simple Java method that accepts the CreateApplicationInput POJO as input to process the request for creating an application.

Finally, the code snippet below shows how Amazon API Gateway requests get routed (from the Lambda handler) to the appropriate Java methods in the ApplicationService class.
As mentioned earlier, the project uses the Jersey framework (an implementation of JAX-RS). The ApplicationService class is registered with ResourceConfig (a Jersey Application) so that Jersey can forward REST calls to the appropriate methods in ApplicationService class. The API requests get sent to Jersey via the JerseyLambdaContainerHandler middleware component that natively supports API Gateway’s proxy integration models for requests and responses. This middleware component is part of the open source AWS Serverless Java Container framework, which provides Java wrappers to run Jersey, Spring, Spark, and other Java-based framework apps inside AWS Lambda.

Testing and deployment
Integration tests are defined using Cucumber, a popular Java testing framework that allows translating user requirements into test scenarios in plain English that all stakeholders can understand, review, and agree upon before implementation. These tests are inside the src/test folder and can be run as part of an automated CI/CD pipeline, or manually. Running integration tests deploys a test stack to your AWS account, runs the tests, and deletes the stack after the tests are complete.
For deployment to AWS, we use the AWS Serverless Application Model (SAM), which provides shorthand syntax to express functions, APIs, databases, and event source mappings. These templates can be deployed manually or as part of an automated pipeline. When organizing our templates, we adopted two key best practices learned over the years at AWS: nested stacks and parameter referencing:
1) Nested stacks make the templates reusable across different stacks. As your infrastructure grows, common patterns can be converted into templates, and these templates can be defined as resources in other templates. In this project, we have added a root-level SAM template called template.yaml for each component. Within that template, nested templates, such as database.template.yaml and api.template.yaml, are defined as resources. These nested templates, in turn, define the specific resources required by the component, such as an API Gateway API and a DynamoDB table.
2) For parameter referencing we used AWS Systems Manager Parameter store, which allows configurable parameters to be stored in a parameter store and referenced inside a SAM template. A parameter store also allows referencing these directly inside Lambda functions instead of passing them as environment variables. It allows managing the configuration values independent of your service deployment.
Walkthrough
In the section above, we described some of the development techniques, testing practices, and deployment approaches of the project. Now, let us walk through building and deploying the application in your AWS account. We will build the static website (front-end), and the back-end components so that we can see an end-to-end demo of the working application. This should take less than 10 minutes.
Make sure you have the necessary prerequisites installed locally on your computer. Clone the GitHub repository, change into the directory of the project, and run the following commands to build the code:
cd static-website
npm install
npm run ci
cd ..
mvn clean compile
Note: The application supports Node LTS version 10.16.3, and OpenJDK version 8. You can use Amazon Corretto for a production-ready distribution of the OpenJDK.
Once the project is built successfully:
- Create an s3 bucket to store the packaged artifacts of the application via
aws s3 mb s3://<s3 bucket name>; - Package the application via
mvn clean package -DpackageBucket=<s3 bucket name>; - Deploy the application via
aws cloudformation deploy --template-file target/sam/app/packaged-template.yaml --capabilities CAPABILITY_IAM CAPABILITY_AUTO_EXPAND --stack-name <name>
You should see an output similar to the following image:

Once the stack has been successfully created, navigate to the AWS CloudFormation console, locate the stack you just created, and go to the Outputs tab to find the website URL for the application. When you click on the link, you should see a page like this. The application is up and running!

You can click on Try the Demo to access the back-end APIs. As a first time user, you will be asked to sign up first. You can then create (publish), get, update, list, and delete applications.
Next steps
In this post we covered how we leveraged serverless to build a production-grade service, and how AWS developers are using serverless technologies to innovate ever faster on behalf of our customers. The post briefly covered the details of the project’s back-end (request/response) component, our testing and deployment practices, and a walkthrough of how you can deploy an instance of the front-end and back-end to your AWS account. As next steps, you can fork the repository and modify it. You can also set up a CI/CD pipeline to push your changes automatically. We have provided CI/CD templates for each of the components under sam/cicd/template.yaml. These templates can be easily deployed using:
aws cloudformation deploy --template-file target/sam/cicd/template.yaml --capabilities CAPABILITY_IAM CAPABILITY_AUTO_EXPAND --stack-name <your-stack-name>
You can also learn more about the analytics component and the pipelines, operational alarms and dashboards. We hope you find this useful – if you do, please let us know by starring the GitHub project.