AWS Open Source Blog
fMRI data preprocessing on AWS using fMRIprep
A typical fMRI study often produces imaging data of terabytes or more. Storing and preprocessing this data can be challenging on a single computer because it often has neither enough disk space to store the data nor enough computing power to preprocess it. Traditionally, researchers use a combination of cloud-based storage and on-premises high-performance clusters to store and preprocess the data. However, transferring data between the cloud and the on-premises cluster can be time consuming, and learning how to use a cluster can be a challenge itself. In this post, we “open-source” a solution that simplifies the storage and compute needs for analyzing fMRI data using Amazon Simple Storage Service (S3) and Elastic Compute Cloud (EC2). This solution will demonstrate how researchers can run fMRIprep, an open source preprocessing pipeline for fMRI data developed by Stanford University’s Poldrack Lab, on AWS to preprocess fMRI data for further analyses. We believe that adopting cloud-based solutions can help researchers focus on their core research by significantly reducing engineering efforts on preprocessing fMRI data.
| Time to read | 25 minutes |
| Time to complete | 30 minutes |
| Cost to complete | $10 OR free |
Overview of solution
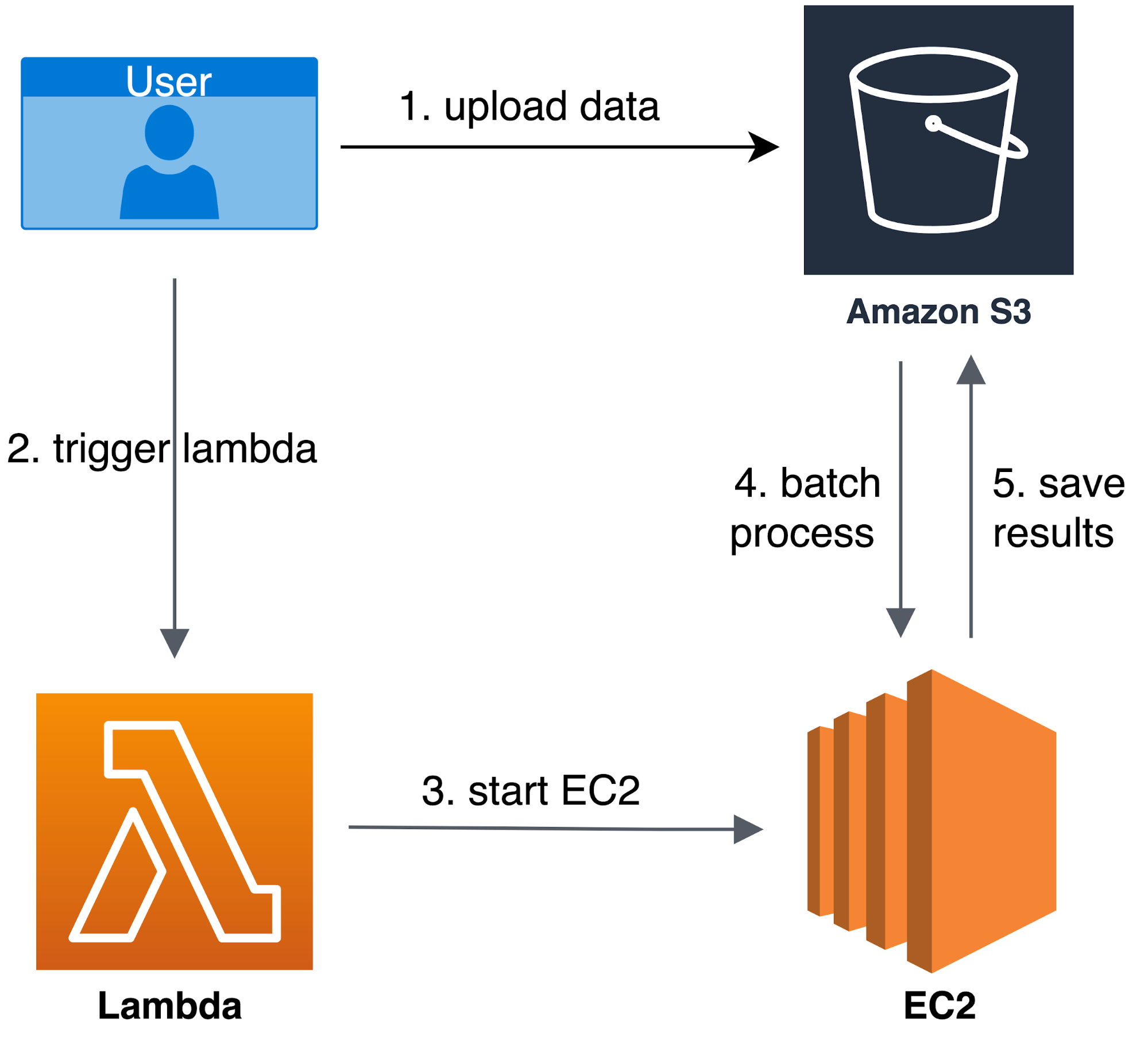
User uploads data in BIDS format to S3 and starts the Lambda function → Lambda parses the uploaded data and launches a cluster of EC2 instances → EC2 instances run fMRIprep which preprocesses the data → preprocessed data are saved to S3.
Prerequisites
- A FreeSurfer license. fMRIprep uses FreeSurfer, which requires a license. You can get it for free.
- An AWS account.
Sign up for a Free Tier account if you do not already have an AWS account.
If you are a student or faculty member, you can sign up via AWS Educate, which gives you at least $75 in credits, as well as other benefits.
If you do not have an education account, working through this tutorial may cost you $10. If you do not want to pay for anything, choose a free-tier instance type and you can get through most of the post except the final step. - Some familiarity with fMRIprep and the AWS console.
Walkthrough
The following sections cover four major steps:
- Launch the AWS CloudFormation stack.
- Upload the FreeSurfer license and fMRI data to S3.
- Update the Lambda function and start preprocessing.
- Clean up.
Steps
Log in to the AWS console
- Select Oregon (us-west-2) region at the top right corner. (If you want to launch in a different region, check the extra instructions in the Supplementary Steps section at the end of this post.)

- If you requested an AWS Education account, you will need to log in to the console using this URL: https://aws.amazon.com/education/awseducate/members/
Launch the CloudFormation stack
- If the CloudFormation stack works as expected, you should see a Create Stack dialog box.

- If step 1 did not work for you, open CloudFormation (click Services in the top left corner, type in
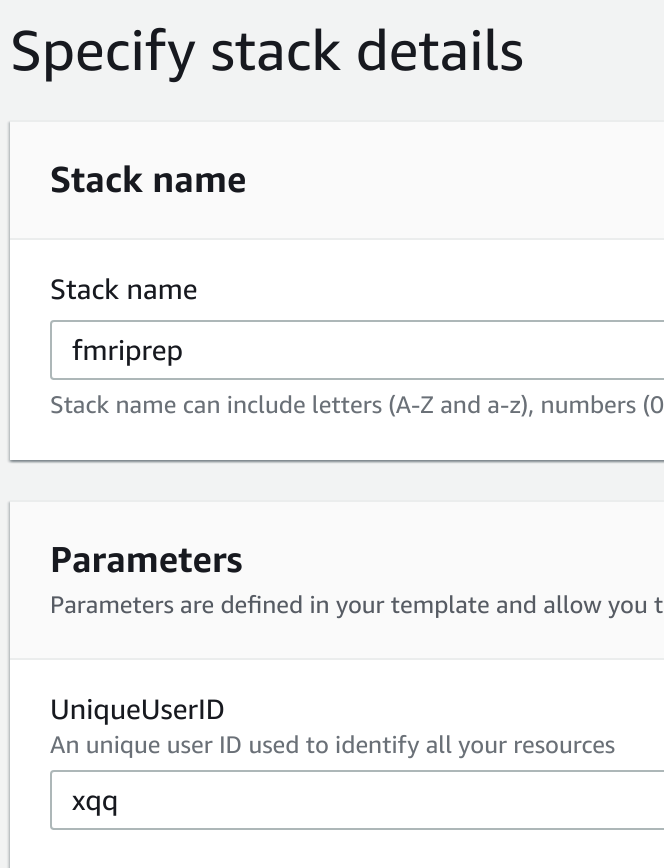
cloudformation, and click CloudFormation). Click Create stack, choose Template is ready and Amazon S3 URL. Copy this URLhttps://aws-blog-files.s3.amazonaws.com/fmriprep-cf.jsoninto the Amazon S3 URL field, and click Next. - Change Stack name (e.g.,
fmriprep) if desired, input a UniqueUserID (e.g.,xqq), and click Next. Note: you must choose a unique UniqueUserID – it has to be DIFFERENT fromxqqbecause S3 bucket names are global and CloudFormation will create three S3 buckets based on the UniqueUserID. If CloudFormation fails with the errorXXX bucket already exists in stack, select a different UniqueUserID and try again.
- Leave everything else as default and click Next until you see the Capabilities tab, check it and click Create Stack.

After the stack is successfully created (about one minute), the following resources will be created for you:
- Three S3 buckets used to store the input, output data, and FreeSurfer license.
- A Lambda function that can parse the input data and launches EC2 instances to preprocess fMRI data in the input bucket.
- One IAM role for Lambda to launch EC2 instances.
- One IAM role for EC2 to read and write files from/to S3.
Before moving on to the next step, make sure your stack is successfully created.
Upload FreeSurfer license and fMRI data (BIDS format).
Note: Do not use white spaces in your filenames or paths, or the Lambda function may not run correctly.
- Open S3 service by typing in S3 after clicking Services.
- Upload your FreeSurfer license file into the FreeSurfer bucket (e.g., fmriprep-freesurfer-license-xqq, where “xqq” should be your UniqueUserID) by clicking Upload, adding the license (e.g., license.txt), and then clicking Upload on bottom left. Note: Do not create any extra folder to store the license file. Otherwise, you will have to change the Lambda function accordingly.
- Upload your data in BIDS format into the input bucket (e.g., fmriprep-input-xqq).
You can also try this toy data set OR other datasets from bids-examples. If using the toy data set, download it, unzip it, and upload the whole folder.
The figure below shows a sample bucket folder structure. Verify your data is in BIDS format using BIDS validator before uploading them.
Update the Lambda function and start preprocessing
The Lambda function extracts the numerical subject ID from the input S3 bucket folder and launches EC2 instances based on a pre-built AMI with Docker and fMRIprep installed.
- Open the Lambda service (Click the Services Tab, type in lambda and select Lambda).
- CloudFormation should have already created a Lambda function for you (e.g., fmriprep-lambda-xqq). Click and scroll down the Environment variables section.
- Change freesurfer_license_filename to your filename (e.g., license.txt).
- Change folder_in_input_bucket to your BIDS data folder (e.g., hcp_example_bids).

- Leave ami_id, instance_type, and unique_user_id as default.
- If you want to use your own AMI or launch in a different region, input your own AMI ID in place of ami-0938afc45f7f5593c. See details under Supplementary Steps at the end of this post.
- You can change instance_type to t2.micro to avoid all fees, but the preprocessing will fail due to insufficient memory.
- If you want to process your own data, you may need to change instance_type (e.g., to m4.xlarge) so that it has enough RAM. See available instance types here.
- Note: all these variables can be changed directly in the Lambda function as well.
- Click Save at the top right corner, then click Test.
- If prompted to create a new test, input any name (e.g.,
test) and leave everything as default and click Create. - Click Test again and it should show a success message after a few seconds.
- If prompted to create a new test, input any name (e.g.,
- Go to the EC2 dashboard and you should see that EC2 instances are running to preprocess your data. The EC2 name tells which subject that instance is processing.

- After the fMRI data is processed, the output files from fMRIprep will be saved in the output S3 bucket and EC2 instances will be automatically terminated. You can check progress by SSHing into the EC2 instances and using the command
cat /var/log/cloud-init-output.log.
Cleaning up
- In S3, delete all the files in the input/output/FreeSurfer-license buckets.
- In CloudFormation, delete the stack that you created. Once the stack is successfully deleted, everything is deleted.
Explanation of service choices
Data storage
Storing fMRI data in S3 has several advantages:
- There is no limit to the amount of data that S3 can store and you only pay for the used space.
- Data in S3 can be easily accessed by compute services like EC2, which removes the need for transferring data between storage and compute providers.
- S3 is highly durable and supports versioning and lifecycle policies. With a lifecycle policy, you can archive data that is unlikely to be used again, to further reduce storage costs.
Compute
AWS offers many computing choices, e.g., EC2, ECS. In this post, we used an Amazon Machine Image (AMI) with Docker and fMRIprep pre-installed. By using this AMI, other researchers can directly start preprocessing fMRI data without having to repeat the tedious work of installation. You can also launch many EC2 instances at the same time to batch process a lot of fMRI data (you may need to submit a request for service limit increase, to increase the number of instances you can launch at the same time). As with S3, you also only pay for what you use.
Scheduler
In this post, we used a Lambda function to schedule the compute jobs. The Lambda function reads the fMRI data inside your uploaded folder, identifies the subjects to analyze, and launches the corresponding number of EC2 instances to process the data. After the preprocessing is done, EC2 saves the data to the output S3 bucket and automatically terminates itself.
A more native solution for scheduling work is to use AWS Batch or AWS Fargate. However, Batch uses ECS, for which the recommended Docker image size is less than 10GB, and the Docker image for fMRIprep is around 13GB. A big Docker image is slow to retrieve and load, which creates a lot of compute overhead before the actual analysis can start.
Permissions
AWS offers many services and features to ensure the safety of the system. The CloudFormation stack creates two roles, one for Lambda to launch EC2 instances on your behalf, the other to grant EC2 instances the read/write access to S3 buckets.
Supplementary steps (optional)
To install the AWS CLI, upload data via the CLI, and automatically start the Lambda function:
- Install AWS CLI.
- Configure your AWS credentials.
- Upload your data using AWS CLI:
aws s3 cp –recursive ./hcp_example_bids s3://fmriprep-input-xqq/ - Run your Lambda function via the AWS CLI. e.g.,
aws lambda invoke --function-name fmriprep-lambda-xqq --payload '{"test": "test"}' out - You can execute the above two commands consecutively so that the Lambda automatically start the preprocessing after the data is uploaded . e.g.,
aws s3 cp --recursive ./hcp_example_bids s3://fmriprep-input-xqq/ && aws lambda invoke --function-name fmriprep-lambda-xqq --payload '{"test": "test"}' out
To run this workflow in a different region:
- Because the AMI cannot be used across different regions, you need to either create an AMI yourself or copy the existing AMI from us-east-1 to your region.
- To create your own AMI, follow the AMI documentation. You need to install Docker and the Docker version of the fMRIprep, and then create the AMI.
- After you have an AMI in your desired region, launch the CloudFormation stack. In your Lambda function, modify both occurrences of AMI to your AMI ID and REGION to your desired region. Note that you need to input the region code rather the region name here. For a complete list of region names and corresponding codes, see the AMI documentation.
FAQs
Why not use a container service like AWS Fargate/ECS/Batch?
- The fMRIprep Docker image is larger than 10GB. AWS does not recommend using large containers in a production environment. Also, a large Docker image takes a long time to load, creating a large overhead in the processing pipeline.
- Fargate limits the data volume to 10 GB, while fMRI tasks often require a lot of temporary storage. In addition, the upper limit of four vCPUs may throttle the performance of fMRIprep.
- ECS: Mounting an external volume is possible but not straightforward.
If these limitations can be addressed, AWS Batch/Fargate/ECS can be a better solution than the current one.
Why not use AWS ParallelCluster?
- Installing the software and maintaining an HPC cluster would require more steps than are needed for a quick introduction to how to use AWS to run fMRIprep.
- For researchers with experiences in managing a HPC cluster, we encourage them to try AWS ParallelCluster as another possible solution. AWS ParallelCluster provides an easy way to set up an on-demand HPC cluster.
What are the main advantages of using AWS over on-premises HPC?
- More flexible and easier to set up with tools like CloudFormation.
- Good integration between data storage (S3) and data processing (EC2).
How do I connect to my instances?
- Create your own key pair name in Key Pairs in EC2.
- In the Lambda function, change KeyName (line 38) to your key pair name in EC2.
- In EC2, choose the instance you want to connect to and click Connect.
What can be added or improved in these steps in future?
- Fine-tune the performance by changing the Lambda function based on the instance type so that Docker can utilize all computing cores.
- Add an email notification when jobs are finished.
- Explore the use of AWS Batch/Fargate to run the preprocessing.
Conclusion
AWS offers many different storage and computing services. This post shows an easy way to start running fMRIprep on AWS to preprocess fMRI data. We expect that other and better ways to do this will become available in time as service features are added and extended. We hope that readers will collaborate with us to continue to explore better and more efficient ways to process fMRI data on AWS. The CloudFormation template and Lambda function template are provided here for readers to modify and improve. Please let us know your thoughts and suggestions by commenting.
Acknowledgements
Thanks to Tapodipta Ghosh, AWS senior Solutions Architect, for his suggestions and technical review.

Mengxue Kang
Mengxue Kang is a PhD candidate in Cognitive Psychology and Master’s in Computer Science at Rutgers University. She studies the mechanism of memory using neuroimaging tools and machine learning techniques. She has 4 years experiences in fMRI data processing.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.