AWS Startups Blog
END.’s New Platform Runs On AWS Fargate At Its Core
Guest post by Aris Boutselis and George Anagnostopoulos, DevOps Engineers at END. — leaders in luxury and contemporary men’s fashion // endclothing.com
At END. we’re constantly working to improve the way our engineering department operates. Our goal is simple: to empower the team so they can get stuff done without obstruction or interference. Anything to make things easier, faster, more reliable—and if that means tinkering with some new technology along the way, even better.
Until recently, deployments were one of the biggest pain points for our engineers and with a two-person DevOps team we inevitably became a massive bottleneck when it came to go-live. We knew we needed to find a better way of doing things, and as existing AWS users, AWS Fargate seemed like the natural way forward.
By introducing a solution that completely removed the infrastructure layer from DevOps’ scope we were finally able to shift our focus from support to new projects, while our engineers became free to perform their deployment tasks at the push of a button, with little or no involvement from DevOps’ side. This was a real win-win for everyone and delightfully simple to execute.
Here’s how we did it.
The Way We Were
We decided to start small, working with just one of our teams at a time. The ‘END. Launches’ platform was first up.
END. Launches is a microsite that operates high-profile raffles for some of our most exclusive and limited-edition stock. Although launches doesn’t typically handle transactions on the same scale as our main site, it is an important and highly visible part of our brand so any downtime on the platform can cause untold damage to our reputation (no pressure).
Unlike our main site, however, it had no dependency on the rest of our infrastructure, making it the perfect test case to test our Fargate rollout on. Another plus; Launches was also a small team, which allowed us to roll out changes to their process in a much more Agile way. Collectively these factors made it far easier for us to abort our mission if things went terribly wrong.
After choosing our guinea pigs, step one was to pinpoint the pain points in their existing workflow. There were many.
Firstly the legacy infrastructure was deployed using Terraform, but the Terraform state had deviated from the actual existing infrastructure. At some point, manual changes had been introduced and a lack of capacity in the team led to snowballing technical debt. Obviously tech debt happens, but this created an ad hoc dependency on DevOps every time Engineers needed a new environment to test major changes.
The use of immutable design in deployments also posed problems, meaning that new changes took a painfully long time to reach the production environment. In order to deploy Developers also needed to manually trigger a build of their code in conjunction with a deployment on the respective environment, and to complicate things even further, this process needed to be repeated for both the frontend and backend of the application.
Behind the scenes, with every build and deployment a new AMI would be created and all the EC2 instances in the respective auto scaling groups would be replaced with new ones using the new AMI. Then, a QA Engineer would manually run through the test scripts for the application and give the all clear before starting the build for the next environment.
This old way of working hinged on a constant back and forth between the different teams which was time consuming and prone to error. Rollbacks also took a significant amount of time as we had to wait for the new AMI to be created, which often lead to the worst possible outcome for us as an ecommerce site: downtime.
In short, it was a bit of a mess.
Welcome to The World Of Tomorrow
With the old ways of working well understood, it was time to say goodbye and crack on with implementing a new solution that would make everyone’s lives easier.
As you would expect, the native AWS solution provided seamless integration with the rest of our AWS infrastructure. It had a very smooth learning curve and we were up and running in a few minutes. Remarkably it has since required very little, if any, of our time for maintenance. Really, our experience has been the epitome of ‘it just works’.
Better yet, deploying tasks in Fargate has saved us immeasurable hours when compared to our previous setup with EC2 which was tediously slow; and the ability to rollback almost instantaneously has given us the freedom to fail faster. By introducing AWS’ serverless solutions for containers we now have the breathing room to be proactive in our day-to-day and have been able to start investing our time in END.’s Continuous Integration and Deployment processes.
Introducing CI/CD
For this we decided to go with Bitbucket pipelines as our main CI/CD tool — a no brainer as we were existing users.
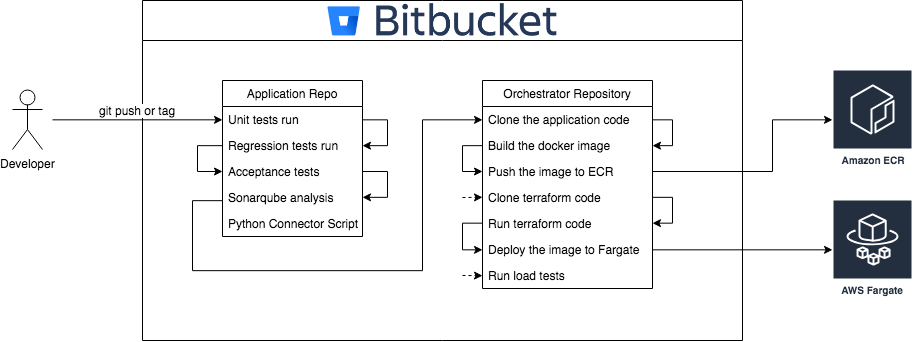
In our existing setup we had three repositories: the code base repo, a Terraform repo and the orchestrator repository. The latter houses all the logic while the other two contain the application code and the project’s infrastructure components. In order to create a relation between these three repositories we used a small Python script, making API calls to trigger different pipelines on the orchestrator side. It turns out Bitbucket pipelines have become quite powerful and handy for utilising CI/CD practices; so for instance we managed to create the exact same Fargate development environment inside pipelines with the help of services and databases like Redis and MySQL.
The next step was building continuous integration tests. If our automated unit, regression and acceptance tests were successful then the Python connector script would try to trigger a Fargate deployment pipeline in the orchestrator.
Meanwhile all the deployment logic resides in the orchestrator which is responsible for cloning application code and Terraform repositories, building and pushing Docker images to Amazon ECR and finally deploying new Fargate tasks via an AWS CLI wrapper script. Terraform also ensures that we have the desirable AWS infrastructure components based on the remote S3 tfstate files. This solution provided a centralised environment for Terraform to run, logging all the actions in pipelines.
From a Developer’s perspective everything is managed by git push or tags and having the same infrastructure inside pipelines and in AWS for the development environment allowed our Engineers to make real time deployments with every commit they made. From here on out Developers have been empowered to take full responsibility for their application, and our QA team have been free to focus entirely on pre-live environments — just as things should be!
Here’s what this process looks like:

In Short
Even with just one team up and running with Fargate, our new process has significantly improved the everyday operations of our team. Centralisation is making things more transparent, code deployments have been streamlined and the dependency on us as a DevOps team has been greatly reduced.
Another unexpected upside—being serverless has also meant we’ve had to write better microservices. By removing access to boxes we’ve been forced to properly consider everything about the application. With no room to hide, we’ve really had to step up and consider every edge case and potential mistake before it occurs. It’s challenging, but worth it.
Most importantly though, our Developers are fully empowered to own their product and have the autonomy to do what they do best; make things and ship them. Now it’s time to tackle roll out for the rest of our teams. Thankfully, with Fargate’s easy implementation, it should be a breeze.