AWS Storage Blog
Architecting for high availability on Amazon S3

Amazon S3 has now surpassed 15 years of operation and has scaled to more than 100 trillion objects. AWS has scaled S3’s hardware infrastructure while continuously deploying software for new features and updates, all while maintaining the high availability that customers require. High availability is an important pillar of S3 – customers should be able to access data whenever they need it.
High availability starts with infrastructure that is resilient and resistant to disruption, characteristics at the core of Amazon S3, which delivers high durability, availability, and performant object storage. With S3 at the core, designing your system for high availability becomes easier.
In this post, I provide some of the key takeaways from my re:Invent session “Architecting for high availability on Amazon S3,” first presented in December 2020 and then again on the first day of AWS Pi Week due to popular demand. As covered in the session, I give an inside look on how S3 is architected for high availability, and actionable takeaways that you can implement into your environment to achieve high availability. I start with challenges around defining and measuring availability. Then I discuss details on the end-to-end robustness of Amazon S3, and techniques to ensure robustness of each component of your infrastructure. That is half of the story; the other half is around best practices to operate a system for high availability. Building for high availability includes continuous and safe software deployment, cell-based architectures, and a culture that encourages deep root cause analysis. Finally, I recap some high availability examples in three different customer scenarios.
Measuring availability
Measuring availability in a large multi-tenant service is challenging. A big risk is having important availability problems be masked by anticipated, regular occurrences such as hardware failures, network link flaps, or the natural change in demand throughout the day. As we know, if you cannot measure it, you cannot fix it, so metrics for availability are a critical component of identifying issues and rectifying them.
So what does availability mean to a customer and what does Amazon S3 need to measure? Let’s look at it a few different ways.
Availability is personal
A customer cares about their observed availability. If you have any availability concerns or impacts, the overall service availability uptime will not matter to you. We also want to make sure that we don’t bias against more active users of a service. For example, both the availability of a customer that makes 1000 requests/second and that of a customer that makes 1 request/second matter equally to those customers. That is why we always measure availability on a per-customer basis, no matter the size.
Timing
Availability is about the system experience when it matters the most to customers. For example, when users send requests to Amazon S3, expect them to always succeed. Therefore, the next relevant metric here is the error rate. Time granularity is an important factor to consider here. If it is too long (for example, when making an average measurement for a whole day), then we’d miss explaining short outages in the order of seconds or minutes that could still be important to you. S3 measures this metric during a fine-grained time interval so that it captures a full distribution of errors over the entire day.
Monitoring
Amazon S3 continuously and pro-actively monitors the health of each component in the system. In addition to monitoring and canaries, we have integrated monitoring systems that enable us to measure the average and the distribution of component failure rates and repair rates. The metrics we pull from this monitoring goes into our model for Amazon S3’s availability.

Putting all these measurements together leads to the 9s availability analysis that you can read about on many Amazon S3 pages and documentation pages.
End-to-end robustness in Amazon S3
During my re:Invent session I covered how Amazon S3 maintains high availability in the face of hardware infrastructure failures, both permanent ones and transient failures. I started with a top-to-bottom approach. First, I looked at how we rigorously and continuously prepare for an entire facility failure, even though it is extremely rare for such an event. Then, I covered how we use the same rigor to plan for individual component failures, like a storage server or even a single disk.
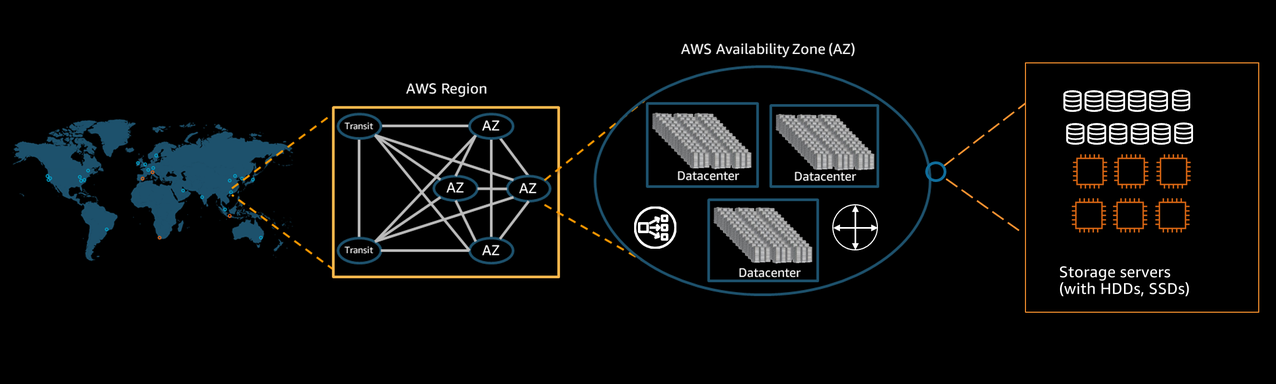
Redundancy in everything
For example, to survive an entire facility failure, Amazon S3 leverages the concept of Availability Zones, which are a collection of one or more data centers that are physically separate facilities in a metropolitan area. Amazon S3 storage classes replicate their data on more than three Availability Zone (except for S3 One Zone-Infrequent Access). Amazon S3 maintains redundancy even within one of the facilities in a single Availability Zone. For example, Amazon S3 replicates data across multiple disks, so even if one of them fails, customers can still access their data with no downtime.
Continuously improve failure detection
Improving failure detection typically means having deep service instrumentation and tests and canaries that run constantly and proactively find out any component failures. Improved failure detection can also involve predicting when certain devices like disks will fail and automatically and proactively initiating their repair (by re-replicating data).
Continuously improve recovery times
Recovery times are critical to bringing back the original redundancy and guarding for multiple simultaneous failures. In the talk, I showed how we use an elastic repair fleet of machines whose job it is re-replicate data in case of disk failures. The fleet is elastic in the sense that its size (and therefore speed of repair) is automatically tuned to the amount of data that needs to be re-replicated.
Some failures can be transient, for example, network queues could be temporarily overloaded and shed traffic or DNS resolving might temporarily fail. Amazon S3 internally maintains high availability even in the face of such transient failures by automatically retrying requests with the appropriate backoff times. In the talk, I discuss the shared responsibility model for maintaining high availability that Amazon S3 has with customers who run the S3 client-side libraries (SDK). Customers are encouraged to keep the AWS SDK up to date to pick up any new fixes and performance improvements that lead to high availability. They are also encouraged to follow best practices in re-resolving DNS entries in their environment.
Operational best practices
So far, I have discussed how Amazon S3 maintains high availability by monitoring and planning for system failures, so that S3 mitigates such events without an impact on customers’ availability. One lesson we learned over the years is that the organizational culture of rigor and hardened software deployments is important to system availability. We deploy a lot of software in S3, itself made up of hundreds of constantly updated microservices. The multitude of tests, and focus on predicting issues at scale for software updates, can make a positive impact on system availability. Let’s look at a couple of things we’ve learned.
Cell-based architectures reduce blast radius
Amazon S3 deploys software gradually over its fleet one using best practices for reducing the impact of something going wrong. One such best practice is using a cell-based architecture. A cell is a self-contained unit of devices that handles specific workloads. After AWS updates a cell, customers whose requests use those cells benefit from the new software. Deploying one cell at a time gives us time to measure and mitigate any updates that had unintended consequences. If the measurements detect that something has gone wrong, we can roll back the software automatically to diagnose the problem and fix it, before redeploying the software.

Good tooling
In Amazon S3, we give operators good troubleshooting and mitigation tools, and our development teams priorities the development of such tools above anything else. These tools are precise and are useful for the task at hand, so that the operator does not need to improvise during an on call event. They do not require unnecessary input, because they attempt to infer it automatically, and they perform safety and sanity checks and fail safely. They have the necessary and sufficient permissions to perform only the task at hand (for example, we disallow broad SSH access to instances and limit access permissions to times when there is an on call event).
We also make the operator’s engagement easier by automating many of the recovery mechanisms when something goes wrong. Developers spend a lot of time writing good mitigation scripts, and instructions for how to solve an issue, should it arise in practice.
Non-judgmental root-cause analysis
Amazon S3, and indeed all of AWS, performs detailed root-cause analysis reviews. In these reviews, Amazon S3 identifies where the root-cause of an availability problem is. Generally, we prioritize improvements above new features. These reviews are non-judgmental. In the talk, I describe the typical review agenda for such meetings in the hope that it can be useful in your organization as well.
Applying lessons to your own applications
I concluded my talk by looking at 3 case studies that exemplify the approach used by Amazon S3 to build your own highly available applications. The first case study discussed a customer application that is stateless, where the customer’s goal was to have a resilient application in the face of compute instance failures. I showed how the customer could benefit by using multiple Availability Zones and focusing on fast recovery. The second case study discussed a customer that desired high availability in the face of transient failures. We showed how the customer could do that by making sure they kept their AWS SDK up to date and correctly configured the Java Virtual Machine (JVM) DNS cache. The third case study discussed a customer that deployed bug fixes and new features more frequently, but worried that their deployments would result in availability impact. In this case, the customer could benefit from using a cell-based architecture for their deployments, just like Amazon S3 does.
Conclusion
In this blog post, I provided a short summary of my re:Invent and AWS Pi Week session “Architecting for high availability on Amazon S3.” I discussed how Amazon S3 measures availability. I also discussed how Amazon S3 maintains high availability in the face of hardware infrastructure failures, while continuously deploying software for new features and updates.
Millions of customers trust Amazon to store trillions of objects. I hope that some of the high availability principles of S3 shared in this post can help you with your own application or service planning. High availability is key to serving customers, regardless of industry, and is critical in the pursuit of limiting downtime, efficiency, and a positive customer experience.
For more information, I would encourage you to watch my session on this topic. If you have any comments or questions about my session or this blog post, please don’t hesitate to reply in the comments section. Thanks again for reading!