AWS Storage Blog
SAN: A million IOPs in AWS from Amazon FSx NetApp ONTAP
There are use cases where applications demand the highest IOPS and throughput to achieve strict service level requirements. You may have seen how it’s possible to leverage the immense horizontal storage scalability of Amazon Elastic Block Store (EBS) into concentrated vertically scaled storage performance in my recent blog “SAN in the Cloud: Millions of IOPs and tens of GB/s to any Amazon EC2 instance.”
By leveraging iSCSI block support on Amazon FSx for NetApp ONTAP, there is an additional method to scale SAN (Storage Area Network) block storage to millions of IOPs and gigabytes per second to AWS instances. FSx for NetApp ONTAP is a storage service that allows customers to launch and run fully managed ONTAP file systems in the cloud. With FSx for NetApp ONTAP, AWS customers benefit from a block service that supports Multiple Availability Zones (Multi-AZs), small computer systems interface (SCSI) locks, near instantly available snapshots, cross-region replication, thin provisioning, deduplication, compression, compaction, and tiering from solid-state drive (SSD) to an elastic capacity tier.
A single FSx for NetApp ONTAP File System is currently capable of (depending on workload caching) of a few hundred thousand IOPs, and up to 2 GB/s. But, we don’t have to stop there. In this post, I cover aggregating block performance to 5, 10, or even 20 times that of a single FSx for NetApp ONTAP to a single client instance using standard operating systems, while still maintaining the ability to support consistent snapshots. With FSx for NetApp ONTAP, you can elastically and non-disruptively scale both capacity and performance enabling a true pay-as-you-go model.
Solution overview
FSx for NetApp ONTAP supports two deployment options that you can deploy in a Region: Single-AZ and Multi-AZ. Single-AZ file systems are built for use cases that need storage replicated within an AZ but do not require resiliency across multiple AZs, such as development and test workloads or storing secondary copies of data that is already stored on-premises or in other AWS Regions. Single-AZ file systems are cost-optimized for these use cases by only replicating data within an AZ. You should use a Multi-AZ file system if your application needs storage that’s highly available and durable across AZs in the same AWS Region. For this solution, I benchmark ten Single-AZ FSx for NetApp ONTAP arrays in parallel.
A Virtual Array of FSx for NetApp ONTAP
A Virtual Array of FSx for NetApp ONTAP volumes is deployed as seen in Figure 1, using infrastructure-as-code to reduce the complexity of provisioning the desired number of FSx for NetApp ONTAP to reach the required performance level. A simple AWS Command Line Interface (CLI) script creates a number of FSx for NetApp ONTAP with the desired configuration, and prepares them for provisioning of iSCSI logical unit numbers (LUNs).
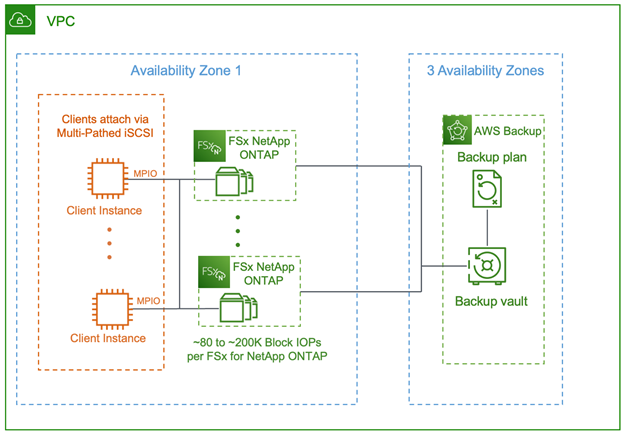
Figure 1: Millions of SAN IOPs via FSx for NetApp ONTAP iSCSI
In Figure 1, each client instance can mount and utilize iSCSI volumes, which are presented by multi-pathed, highly available FSx for NetApp ONTAP instances. Access to volumes is controlled by Initiator Groups, LUN mapping, and CHAP authentication, just as in any Enterprise iSCSI implementation.
Virtual FSx for NetApp ONTAP array construction and configuration
A virtual array of 10 FSx for NetApp ONTAP Single-AZ File Systems was created, each configured with a ~5.3 TB SSD tier. Each FSx for NetApp ONTAP by default has a secondary elastic storage tier. Movement between tiers is controlled by a tiering policy.
The default tiering policy was set to “Snapshot Only,” so that only snapshot blocks are eligible to be moved to the capacity tier, ensuring that all block input/output (I/O) is serviced by the SSD tier. Each file system was provisioned with 80,000 SSD IOPs and 2 GB/s of throughput. Note that the actual IOPs delivered by each file system can exceed the provisioned IOPs by a significant amount if the workload is cache friendly.
The creation of the file systems, and the provisioning of the iSCSI volumes, along with the host setup, configuration, and iSCSI attachments utilized a script leveraging AWS CLI and ONTAP CLI to reduce deployment complexity. Figure 2 shows the results after provisioning the file systems.

Figure 2: A 10x Virtual Array of FSx for NetApp ONTAP in Console View
Integration with FSx for NetApp ONTAP Snapshots
The Virtual FSxN Array can leverage native FSx snapshots by using a coordination script to ensure each File System is snapshot with either crash-level consistency (i.e., point in time), or application consistency that requires host interaction to achieve across multiple FSx for NetApp ONTAP.
Performance on Demand
To scale your performance on-demand, you can update your existing FSx for NetApp ONTAP file systems IOPs (up to 80,000) and throughput (up to 2 GB/s). You can also grow the size of the SSD Tier from 1 to 196 TB in size, allowing block devices to fit completely within the SSD even if you grow the devices. As an example, if you need 20 GB/s of aggregate throughput, instead of provisioning 10 file system with 2 GB/s each, you can instead provision 20 file systems each with 1 GB/s.
Benchmark results
A Virtual 10-wide array of FSx for NetApp ONTAP iSCSI volumes was benchmarked, targeting one million IOPs, and up to 10 GB/s. The preceding Figure 2 shows each file system was configured for ~ 5.3 TB of SSD, and capable of up to 2 GB/s.
Each FSx for NetApp ONTAP’s tiering policy was set to “Snapshot Only”, which essentially locks each iSCSI volume created into the SSD tier, and uses the capacity tier for compacted delta blocks from snapshots. If your workload profile is not high performance and high change rate, you could change the tiering policy allow blocks that are rarely used to be stored on the elastic tier, thus reducing costs. For the purposes of this benchmark, we wanted to benchmark workloads that are high performance and require reliable sub-millisecond access. This was accomplished by sizing the SSD tier to be large enough to hold the entire 2 TB volume as well as sufficient buffer space for snapshots that are eventually tiered to the capacity tier.
AWS Client instances tested were from the i3, m6, and X2 families, running the latest AWS Red Hat Enterprise Linux (RHEL) Amazon Machine Image (AMI). FIO was used to test Random Read (R), Write (W), and R/W, and throughput. An Amazon FSx file system on top of logical volume management (LVM) was used to form the file system under test. Figure 3 below details the benchmark results.
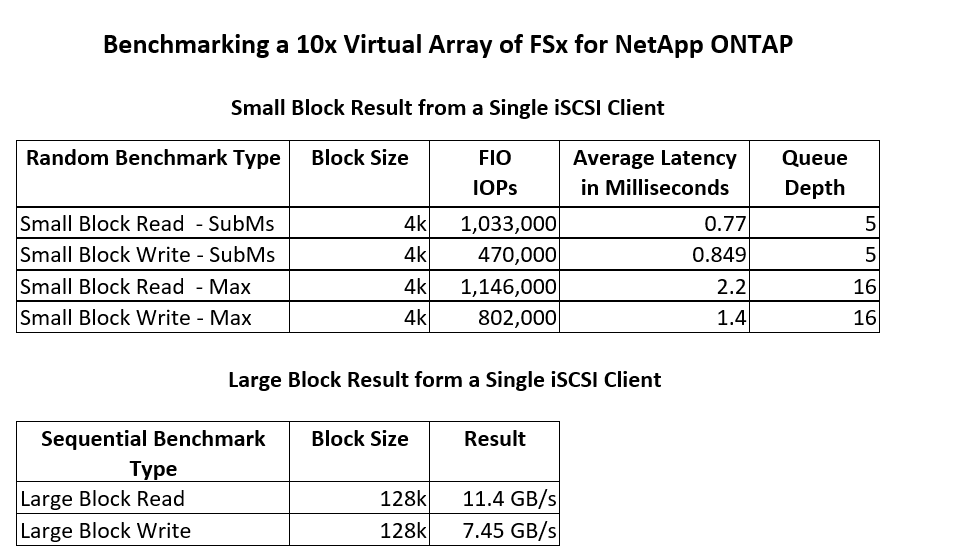
Figure 3: Single Client Benchmarking o Virtual Array of FSx for NetApp ONTAP
The results clearly demonstrate an average latency well under sub-millisecond performance for random small block I/O. Large block reads reached 100% network saturation, while large block writes achieved ~ 7.5 GB/s.
Conclusion
In this post, I showed how you can easily deploy an array of FSx for NetApp ONTAP to scale aggregate block performance in AWS while enjoying all the advanced features of FSx for NetApp ONTAP, and without sacrificing interoperability with other AWS services. Applications and environments that need high aggregate block performance to a single instance (or a small number of instances) can now run in AWS without refactoring for storage performance.
Available now
The Virtual FSx for NetApp ONTAP reference design shown here is based on the currently available AWS FSx for NetApp ONTAP version, standard Amazon EC2 Instances, and RHEL 8.2. Clients that can be supported by AWS instance, while running any operating system (OS) that supports an iSCSI client and multi-pathing.