AWS Storage Blog
AWS SAN in the Cloud: Millions of IOPs and tens of GB/s to any Amazon EC2 instance
Over the years, traditional on-premises applications have relied on ever more powerful (and expensive) storage arrays to scale application IO performance and provide a single server with millions of IOPs. Meanwhile, AWS was perfecting the art of linear, elastic horizontal scalability of storage performance in the cloud.
Until now, it’s been difficult to meet the highly specialized storage performance needs of demanding applications without refactoring the application stack to leverage a more modern dispersed storage architecture, such as Amazon Elastic Block Store (EBS). Recently, AWS announced the general availability of Amazon EBS io2 Block Express volumes, bringing SAN-level performance, features, availability and reliability to the cloud. Io2 Block Express has five nines of durability and each volume can scale to 64TB with up to 260,000 sub-millisecond IOPs, when attached to an Amazon Elastic Compute (EC2) R5b instance. For applications that need up to 260,000 IOPs, io2 Block Express is a great solution.
However, if your traditional application stack has servers using more than 260,000 IOPs to single server, AWS has a solution that does not require refactoring your on-premises SAN based workloads. Yes, Virginia, SAN performance and scalability has come to cloud!
In this blog, I am excited to share how to use a virtualized SAN in the Cloud to integrate AWS’ most powerful compute instances. You can deliver up to millions of sub-millisecond IOPs, and up to 40 GB/s – all to a single EC2 compute instance, leveraging the massive scalability and performance of io2 Block Express. Now high performance application stacks can run on the instance that best meets compute and networking needs, while dynamically allowing you to scale storage performance. In addition, snapshots and a policy based backup service can deliver data protection similar to on-premises SANs. For the first time, the performance and functionality of an on-premises SAN is available in the cloud, and with the cost savings of an on-demand, “pay as you go” model.
Introducing the Virtual Storage Array
The Virtual Storage Array (VSA), depicted in Figure 1, is an improved, virtualized, dynamic form of a classic shared disk array leveraging multiple EC2 R5B instances as front-end controllers, and EBS io2 Block Express multi-attach volumes as the backing store. Unlike a physical array or software defined storage cluster, our Virtual Storage Array can instantly shrink or grow the number of controllers, each delivering up to 260,000 IOPs. No disruption to IO occurs as EC2 R5B controllers are added or removed, or in the event of failure due to the clients attaching to the controllers via multi-pathed NVMe-oF. The controllers are active/active, and stateless as they do not cache data. The number of controllers can be scaled up and down over time as your performance requirements change.
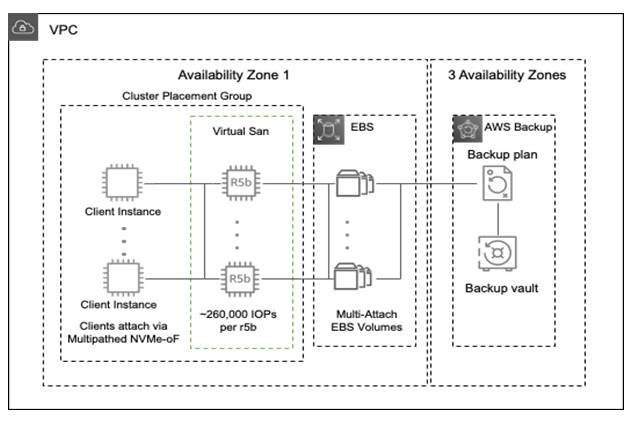
Figure 1: Virtualized Storage Array
AWS instances connect to the VSA through a subnet which forms a SAN, and can share access for a number of high-powered instances. The only limit to the storage performance of a particular instance is 1) the network between the client instance and the VSA, and 2) the number of VSA controllers.
The upcoming Figure 2 shows a 5 controller VSA attached to a 100Gbit Client. The i3en.24xlarge client has 8x 6.8 TB (54.4TB) of local fast scratch NVMe capable of ~ 8 GB/s and 1 million IOPs and is also attached to the VSA which can reach ~ 20 GB/s or over 1 million 8k random IOPs with elastic capacity scalability and snapshot support. If your client need more than 48 cores (96 vCPU), it is also possible to attach a high memory, high CPU instance such as the u-6tb1.112xlarge which has 224 cores, 448 vCPU, 6TB of memory and a 100 Gbit network connection.
Figure 2: VSA in operation
Integration with EBS Snapshots
EBS snapshots can be used to provision copies (with their own, separate performance and storage tiering) directly to another server for backups, test, development or protection from deletion and ransomware, without going through the VSA. EBS snapshots are typically used for backups, report servers, and other lower performance workloads. These EBS snapshots can be mounted directly to any instance, without need of a VSA when the desired performance level is less than 260,000 IOPs. Note that this performance does not impact the primary copy’s performance in any way. If another copy with millions of IOPs is desired, the EBS snapshots can be mounted to another VSA.
Integration with AWS Backup
AWS Backup can create a crash-consistent backups of the entire VSA. AWS Backup utilizes EBS Snapshots to create a VSA-wide crash consistent copy. This consistency refers to the host’s buffers. If an application consistent backup is desired, momentarily pausing Host IO (as in any SAN) can be utilized to take an application consistent backup. All backups are stored in Amazon S3, and thus are replicated to three different Amazon Availability Zones, as illustrated in Figure 1. AWS Backups can also be replicated to other regions in the background. AWS Backup can enforce policies that automate regularly scheduled backups. No performance degradation was observed during testing while leveraging either snapshots or backups.
Performance on demand
You can add IO performance to running instances on AWS beyond the current EBS instance limits by attaching VSA controllers, without disrupting the host while applications are running. The controllers will discover to the volumes, aggregate IO, and present the volumes to the client instance, leveraging client-side multipath to recognize and add new paths to the existing volumes. Once the need for higher performance is satisfied, the additional controllers can be shutdown with no impact on host operations other than a reduction in performance.
The benchmarks
The VSA has been benchmarked using application specific and generic benchmark suites. Two different configurations were benchmarked, a 5 node VSA backed by EBS, and an 8 node VSA backed by local NVMe (non-volatile memory express) instance storage on i3en.24xlarge instances. The local NVMe instance storage is for fast scratch environments, temporary data, etc and does not have the redundancy and reliability of EBS. FIO was used to test Random Read, Write, and R/W, with emphasis on 8k as that size dominates the database landscape. XFS on top of LVM was used to form the file system under test. Large block testing was done to for workloads interested in throughput rather than IOPs.
The following results were obtained on a 5 node VSA with EBS IO2BE as a backing store, using the configuration shown in Figure 2, with FIO, with an XFS file system on the client. The configuration is capable of 1 – 1.2 million IOPs at 8K block size, or up to 21 GB/s. Although VSA can continue to scale, this configuration was chosen to match the 100 Gbit client speed.
5 Node VSA
- 5 Node VSA 8K Random Writes 1.12 Million @ 595 usec
Run1: numjobs=48, bs=8k, rw=randwrite, iodepth=14, ioengine=libaio, direct=1
write: IOPS=1126k, BW=8799MiB/s (9226MB/s)(258GiB/30002msec) (usec) avg=595.22,stdev=768.56
- 5 Node VSA 8K Random Reads 1.16 Million @ 635 usec
Run2: numjobs=48, bs=8k, rw=randread, iodepth=14, ioengine=libaio, direct=1
read: IOPS=1016k, BW=7940MiB/s (8326MB/s)(233GiB/30003msec) (usec) avg=635.10, stdev=220.51
- 5 Node VSA 8k Random R+W 1.05 Million @ 661/564 usec
Run3: numjobs=48, bs=8k, rw=randrw, iodepth=14, ioengine=libaio, direct=1
read: IOPS=526k, BW=4111MiB/s (4310MB/s)(80.3GiB/20003msec) (usec) avg=661.13, stdev=230.40
write: IOPS=526k, BW=4111MiB/s (4311MB/s)(80.3GiB/20003msec) (usec) avg=564.22, stdev=1691.04
- 5 Node VSA 256k Random Write 10.3 GB/s @ QD=2
Run4: numjobs=48, bs=256k, rw=randw, iodepth=2, ioengine=libaio, direct=1
write: IOPS=42.2k, BW=10.3GiB/s (11.1GB/s)(309GiB/30003msec) (usec) avg=2274.23, stdev=2291.23
- 5 Node VSA 256k Random Read+Write 21.4 GB/s @ QD=2
Run5: numjobs=96, bs=256k, rw=randw, iodepth=2, ioengine=libaio, direct=1
read: IOPS=40.9k, BW=9.99GiB/s (10.7GB/s)(301GiB/30134msec) (usec) avg=1862.97, stdev=944.89
write: IOPS=40.9k, BW=9.99GiB/s (10.7GB/s)(301GiB/30134msec) (usec) avg=2744.72, stdev=2998.68
The 5 node VSA results clearly demonstrate an average latency well under sub-millisecond performance approaching near saturation of the network, which is reached with the 256k block size (the preceding Run5). Note that Run5 proves VSA can drive the bi-directional (Read/Write) full-rate of the client 100 Gbit Elastic Fabric Adapter (EFA). Note all IO is direct, so that no localized caching biases the benchmark.
8 Node VSA
The following results were achieved with an 8 node VSA utilizing i32n.24large instances with controllers connected to a single client p4d instance. FIO was used with two different XFS file systems in both job runs. The client p4d instance has four 100 Gbit EFA, totaling over 400Gbit of network throughput, and thus can scale single client performance higher than the previous example. A VSA can utilize either EBS volumes (as is the case of the 5 node example above) or local instance, direct attached NVMe. This benchmark utilized local NVME non-redundant scratch storage on each VSA i3en controller. Similar results can be achieved with an appropriate number of R5b EBS backed controller instances as well.
- 8 Node VSA 2K Random Reads 5.7 Million @ 353 usec
Run6: numjobs=32, bs=2k, rw=randr, iodepth=64, ioengine=libaio, direct=1
read: IOPS=5787k, BW=11.0GiB/s (11.9GB/s)(331GiB/30002msec) (usec) avg=353.03, stdev=121.27
- 8 Node VSA 4K Random Reads 5.2 Million @ 385 usec
Run7: numjobs=32, bs=4k, rw=randr, iodepth=64, ioengine=libaio, direct=1
read: IOPS=5201k, BW=19.8GiB/s (21.3GB/s)(595GiB/30003msec) (usec) avg=385.65, stdev=132.92
- 8 Node VSA 8K Random Reads 3.0 Million @ 660 usec
Run8: numjobs=32, bs=8k, rw=randr, iodepth=64, ioengine=libaio, direct=1
read: IOPS=3098k, BW=23.6GiB/s (25.4GB/s)(709GiB/30002msec) (usec) avg=651.60, stdev=326.11
- 8 Node VSA 8k Random R+W 2.26 Million @ 751 usec
8k-Job1: (groupid=0, jobs=24): err= 0: pid=32512: Thu Sep 9 19:30:56 2021
read: IOPS=573k, BW=4479MiB/s (4697MB/s)(131GiB/30002msec) (usec) avg=719.01, stdev=147.93
write: IOPS=573k, BW=4480MiB/s (4697MB/s)(131GiB/30002msec) (usec) avg=617.90, stdev=138.56
8k-Job2: (groupid=1, jobs=24): err= 0: pid=32536: Thu Sep 9 19:30:56 2021
read: IOPS=561k, BW=4385MiB/s (4598MB/s)(128GiB/30002msec) (usec) avg=750.90, stdev=143.64
write: IOPS=561k, BW=4386MiB/s (4600MB/s)(129GiB/30002msec) (usec) avg=614.59, stdev=138.05
- 8 Node VSA 128K Random Read/Writes 41 GB/s (20.2 R, 20.8 W across 2 Jobs)
128k-Job1: (groupid=0, jobs=32): err= 0: pid=31894: Thu Sep 9 18:57:29 2021
read: IOPS=82.5k, BW=10.1GiB/s (10.8GB/s)(304GiB/30192msec)
write: IOPS=82.5k, BW=10.1GiB/s (10.8GB/s)(304GiB/30192msec); 0 zone resets
slat (usec): min=6, max=13593, avg=114.41, stdev=401.12
128k-Job2: (groupid=1, jobs=32): err= 0: pid=31926: Thu Sep 9 18:57:29 2021
read: IOPS=85.4k, BW=10.4GiB/s (11.2GB/s)(313GiB/30004msec)
write: IOPS=85.4k, BW=10.4GiB/s (11.2GB/s)(313GiB/30004msec); 0 zone resets
slat (usec): min=6, max=10798, avg=118.92, stdev=386.03
The results show that the 8 node VSA scales without increasing latency significantly, up to the limit of the client’s capability to perform IO. VSA can continue to scale by adding controllers and more clients, leveraging the elastic scalability of AWS in compute (EC2) and storage (EBS).
Performance under failure (and maintenance) of 5 node R5b VSA
For EBS backed VSA environments, each r5B controller can achieve close to the network rate of it’s 25 Gbit network. Thus the aggregate of 5 controllers can drive more than a 100Gbit, and the client is capable of exploiting this (in one direction). This makes it possible to remove one of the five controllers for maintenance, or if a single instance failure occurs, there is no noticeable performance impact. Because the client uses a fully interconnected front end to all the controllers (each volume seen on all controllers by the client), the only impact is that one of the paths for each volume is lost. Once the controller is restarted and the path is restored, IO resumes normally. Due to the stateless operation of the controller, performance scales linearly as controllers are added, and no data is lost on controller failure. Recovery of failed controllers and paths is automatic via AWS auto-scaling groups, and occurs in less than one minute.
Conclusion
With VSA, you can now run your mission critical block based concentrated IOPs applications in AWS without refactoring your application, allowing legacy applications to enjoy the same (or higher) levels of application performance than an on-premises deployment. You can easily predict performance levels, pay only for the performance you need when you need it, and ensure timely data protection with snapshots and backup without affecting production performance. Traditional on-premises storage arrays have to be sized to meet surge demand during peak periods and allow for some amount of performance headroom and growth. As a result, the average performance utilization is typically less than 20 percent. However, with VSA simply dynamically add controllers (or remove them) as your performance profile needs change.
Available now
The VSA design is based on AWS standard r5b instances, RHEL 8, with no special software installed. Clients can be any supported AWS instance, running any OS that supports both NVMe-oF client, and multi-pathing. For this configuration nvme-tcp transport was used. You can learn more about R5b instances used in the VSA, the vast number of client (server) instances that can leverage VSA performance. Although the design uses standard storage abstractions like NVMe-oF and multipath, if you would like specific instructions on a VSA configuration, just contact me at AWS by leaving a comment in the comments section. I would love to hear about how AWS can help you meet your high performance EBS storage needs.
-Randy