AWS Storage Blog
AWS re:Invent recap: Deep dive on Amazon FSx for Lustre + Amazon S3

Amazon S3 stores exabytes of data, trillions of objects, and peaks regularly at millions of requests per second. It has set the standard for object storage across the globe. If you’re reading this blog, you probably have data stored in Amazon S3. This could be financial services, life sciences, or media and entertainment data. Perhaps the data is associated with simulations for computational fluid dynamics in the autonomous vehicle, electronic design automation, or oil and gas industries. In any case, over the years you have accumulated and continue to accumulate a massive amount of data. Well, what are you doing with this data? Have you created workloads to leverage the power of this data using big data analytics, machine learning, or high performance computing? If you have, then you’ll want to supercharge these compute workloads by leveraging Amazon FSx for Lustre and Amazon S3.
Amazon FSx for Lustre is a fully managed service that provides cost-effective, high-performance, scalable storage for compute workloads. Many workloads such as machine learning, high performance computing (HPC), video rendering, and financial simulations depend on compute instances accessing the same set of data through high-performance shared storage.
In this post, I cover key points from my re:Invent session on Amazon FSx for Lustre and Amazon S3, in addition to recommending some other relevant and related re:Invent sessions.
Featured session
I start off by covering my re:Invent session, STG214.
STG214: Supercharge your compute workloads: Deep dive on Amazon FSx for Lustre + S3
DEC 8, 2020 | 5:15 PM – 5:45 PM EST
DEC 9, 2020 | 1:15 AM – 1:45 AM EST
DEC 9, 2020 | 9:15 AM – 9:45 AM EST
Featured speaker: Darryl S. Osborne, Principal Solutions Architect, Amazon FSx
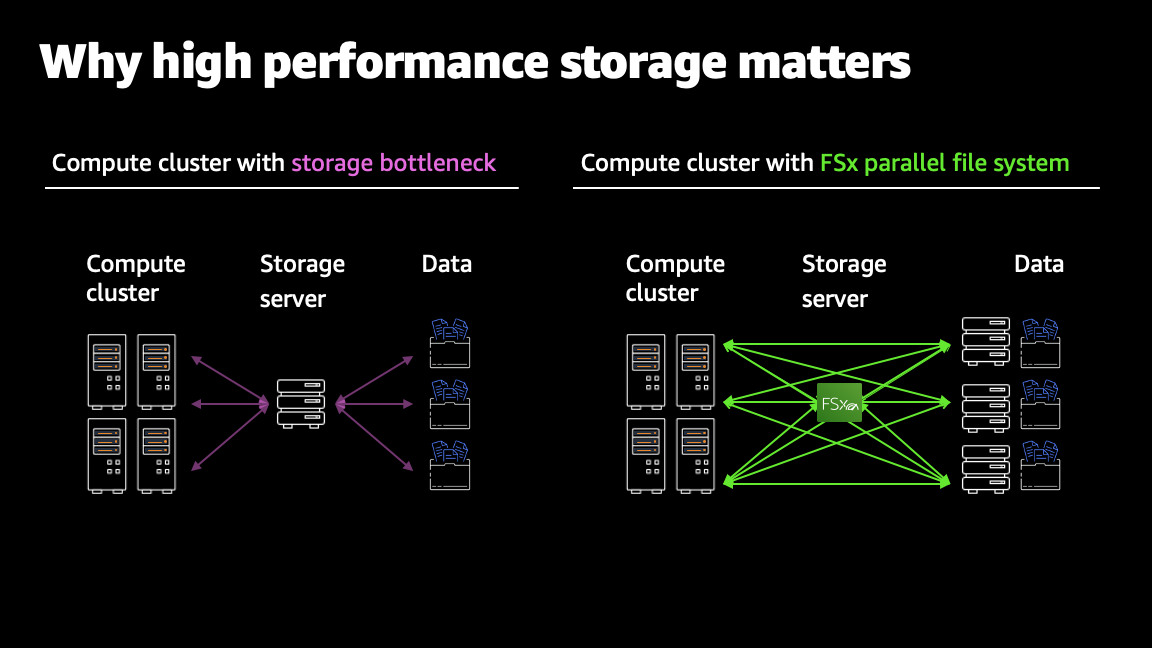
Why does high-performance storage matter?
One of the benefits of cloud computing is the ability to process massive amounts of data in parallel using elastic compute resources. To support these high-performance compute clusters, storage needs to provide equally scalable performance, thus avoiding any bottlenecks in this design. Without sufficient storage performance, compute resources are left idle, waiting for new data to arrive. High-performance storage prevents these system bottlenecks so you can reduce workload runtimes, accelerate business insights, and save compute costs.
Simple and fully managed
A key attribute of FSx for Lustre is that you can easily integrate with your S3 data lake. It offers fully managed file storage so you no longer have to worry about planning hardware capacity, managing hardware failures, managing backups, or performing maintenance updates on your file server. It is also POSIX-compatible, requiring no changes to your existing applications and workflows.
Fast
AWS designed Amazon FSx for Lustre for fast processing workloads where speed matters and the highest throughput is required. It delivers up to hundreds of GB/s of throughput and millions of IOPs. It is accessible from hundreds of thousands of compute cores, providing scalable storage for your compute workloads.
Multiple deployment and storage options
FSx for Lustre offers a range of storage options to optimize price and performance. FSx for Lustre provides scratch file systems designed for temporary storage and shorter-term processing of data, and persistent file systems designed for longer-term storage and workloads. It also provides different storage options. Solid state drive (SSD) storage is optimized for latency-sensitive workloads. Hard Disk Drive (HDD) storage is optimized for throughput-focused workloads.

What’s new in Amazon FSx for Lustre
In my re:Invent session, I cover the innovations we’ve been busy with this past year and how customers are innovating with FSx for Lustre. Two recent features we launched that I’m excited about are live storage scaling and integration with AWS Backup.
With storage scaling, customers can add storage to their high-performance file system with a single click.
AWS Backup is AWS’ native data protection platform that offers centralized, fully managed, and policy-based service to protect customer data and ensure compliance and business continuity across AWS services.
Related re:Invent 2020-2021 sessions
These sessions can keep you ahead of the curve when it comes to optimizing high-performance workloads and making the most of your stored data.
STG205: Amazon S3 Foundations: Best practices for Amazon S3
Watch session on-demand.
Featured speaker: Bijeta Chakraborty, Senior Product Manager, Amazon S3
Amazon S3 and Amazon S3 Glacier provide developers and IT teams with object storage that offers industry-leading scalability, durability, security, and performance. In this session, see an overview of Amazon S3 and review key features such as storage classes, security, data protection, monitoring, and more.
CMP206: HPC on AWS: Innovating without infrastructure constraints
DEC 15, 2020 | 5:15 PM – 5:45 PM EST
DEC 16, 2020 | 1:15 AM – 1:45 AM EST
DEC 16, 2020 | 9:15 AM – 9:45 AM EST
Featured speaker: Ian Colle, General Manager, AWS Batch and HPC
Migrate your High Performance Computing (HPC) workloads to AWS to accelerate your most complex engineering simulations and high-performance data analysis workloads. In this session, learn how new Amazon EC2 instances and the latest features in Amazon FSx for Lustre, Elastic Fabric Adapter, AWS ParallelCluster, AWS Batch, and NICE DCV help you achieve the best price/performance metrics for your HPC workloads. Learn about AWS services that can help manage your HPC costs, and discover how AWS users are increasing their agility and accelerating life-saving research to develop drugs and vaccines by leveraging the virtually unlimited capacity and flexibility of HPC on AWS.
STG221: SAS Grid on AWS: Optimize price, performance, and agility
DEC 15, 2020 | 1:30 PM – 2:00 PM EST
DEC 15, 2020 | 9:30 PM – 10:00 PM EST
DEC 16, 2020 | 5:30 AM – 6:00 AM EST
Featured speaker: Laura Shepard, Principal GTM Manager, Amazon FSx
Many organizations use SAS Grid to analyze data and make critical business decisions. Companies are also moving their SAS applications from on-premises data centers to the AWS Cloud to increase their agility and reduce costs. In this session, you learn how Amazon FSx for Lustre and Amazon EC2 compute instances can simplify your migration to AWS and optimize the price and performance of your SAS Grid deployment.
Conclusion
While we won’t be able to meet in person at re:Invent 2020-2021, I am still looking forward to our AWS customers getting a fulfilling and informative re:Invent experience. Please join me and other Amazonians and virtually attend these sessions to learn more about how you can best leverage file services on AWS.
Thanks for taking a moment to learn more about my session at re:Invent 2020-2021, if you have any comments, please don’t hesitate to leave them in the comments section.