AWS Storage Blog
Turbocharge Amazon S3 with Amazon ElastiCache for Redis
Authored by Michael Labib, Principal Architect, AWS Solutions Architecture with contribution from Sabrinath Rao, Amazon S3 product manager
Amazon S3 is the persistent store for applications such as data lakes, media catalogs, and website-related content. These applications often have latency requirements of 10 ms or less, with frequent object requests on 1–10% of the total stored S3 data. Many customers achieve this by directly writing to S3. Some applications, such as media catalog updates that I discuss below require high frequency reads, and consistent throughput. For such applications, customers often complement S3 with an in-memory cache, such as Amazon ElastiCache for Redis, to reduce the S3 retrieval cost and to improve performance.
Consider the real example of an AWS customer who streams media content. This customer updates their media catalog and channel guides that are consumed by millions of set-top boxes several times a day. These updates generate over one million read operations per second against 1% of their data stored in S3. During the updates, they have to sustain latency at < 5 ms. Caching hot objects outside of S3, such as their content catalog, helps this customer meet their transfer performance goals, while also reducing their retrieval and transfer costs.
In this post, I share how you can set up an in-memory cache using ElastiCache for Redis, along with best practices to be used with S3. You can also test the performance benefits of incorporating a cache for S3.
A brief introduction to ElastiCache for Redis
ElastiCache for Redis is a fully managed, in-memory data store that provides sub-millisecond latency performance with high throughput. ElastiCache for Redis complements S3 in the following ways:
- Redis stores data in-memory, so it provides sub-millisecond latency and supports incredibly high requests per second. See here.
- It supports key/value based operations that map well to S3 operations (for example, GET/SET => GET/PUT), making it easy to write code for both S3 and ElastiCache.
- It can be implemented as an application side cache. This allows you to use S3 as your persistent store and benefit from its durability, availability, and low cost. Your applications decide what objects to cache, when to cache them, and how to cache them.
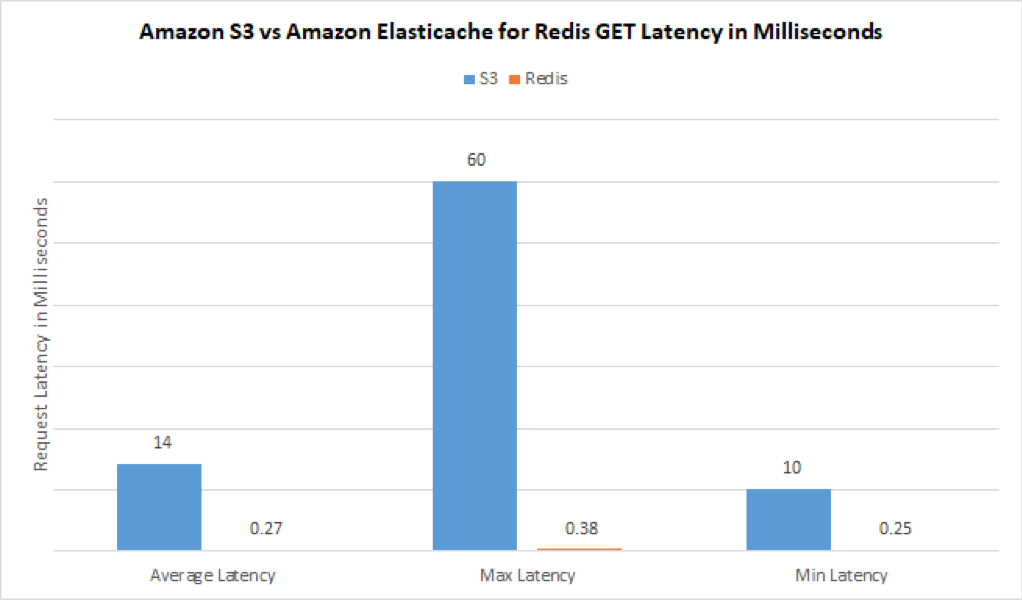
A quick test with 100 GETs on both ElastiCache for Redis and S3 yielded the following self-evident results. Later in this post, I’ll provide you information on how you can also run a similar test.
Setting up your Redis cache
You can set up a Redis cache with just a few clicks from the ElastiCache console. Here are a few important concepts to know before you set up your cache: Redis topologies, eviction policies, availability, and memory.
Redis topologies (configuration modes)
There are two types of Redis topologies:
- Cluster-mode enabled (scales horizontally): The majority of customers choose the cluster-mode enabled configuration. It’s the optimal choice for building highly scalable environments, where your cache can grow and shrink with storage and throughput needs. In the media customer example that I discussed earlier, cluster-mode enabled is the most useful, as the cache can scale in and out without application impact or downtime. Also, the failover time is <30 seconds while reads are not affected when a replica is available.
- Cluster-mode disabled (scales vertically): This topology is suitable for relatively small caches whose storage and performance needs are predictable and do not change frequently. Because this cluster is vertically scaled, the largest sized cache supported must fit within an individual ElastiCache for Redis primary node.
Eviction policies
Next, you have to define what happens when your cache becomes full (maxmemory). Eviction policies control the behavior of key evictions when the cache reaches its max memory size. ElastiCache for Redis offers various maxmemory eviction policies. Most commonly, the least recently used (LRU) eviction policies are used.
ElastiCache for Redis offers two types of LRU policies:
allkeys-lru—Evicts any object key that is least recently used regardless of whether a Time To Load (TTL) value is associated with the key.volatile-lru—Only evicts an object key that has an associated TTL value, which allows you to protect keys that you may not want to evict. This policy would be more applicable if some of your data should be longer lived.
For a full list of cluster parameters, see Redis Specific Parameters.
Availability and memory
When building your Redis cluster, I always recommend deploying it within a Multi-AZ environment, with at minimum one replica for high availability.
It’s also important to consider how much data you need in the cluster and size it appropriately. If you must adjust the memory footprint, the good news is that you can always re-shard your cluster with cluster-mode enabled.
As of publication time, you can store up to 80+ TBs with ElastiCache for Redis, using 125 shards and one replica. You can also take snapshots of your Redis cluster and store them in S3.
For more information, see Best Practices: Online Cluster Resizing and ElastiCache 250 node per cluster support.
Additional considerations
You may also want to consider the following:
- How to organize the data in your cache
- Naming conventions
- Application cache logic
How to organize the data in your cache
After you set up your cache, you have to decide how the content should be stored within the cache. Redis offers a variety of data structure options including strings and aggregate data structure such as a hash, set, or list. The decisions involved with choosing the proper data structure are as simple as deciding how you want your data organized and retrieved.
For example, with a Redis hash, you can store a map of fields and values. This could be a collection of related documents or various properties of a user or content metadata. You can use a Redis list to store an ordered sequence of events or documents. You can also use a Redis set to store unique content, or you can use a Redis sorted set to sort content.
In this post, I use Redis strings to store the content for individual S3 objects within the cache for demonstration purposes. These sample techniques can be used with other data structures.
Naming conventions
Next, develop naming conventions. I recommend using a convention that is easily repeatable and predictable.
In Redis, a colon is commonly used in the key name to imply the structure. In the following code snippets, I use S3 bucket name:S3 Object Key name as my convention. The value associated with the key name is the string value stored within the S3 object itself.
Application cache logic
When you’ve decided on your Redis data structures and naming conventions, you are ready to start applying your application cache logic.
Redis users typically employ two commonly used caching techniques: Lazy loading and write-through. Cache population can happen when objects are read (lazy loading), when new objects are added to the database and proactively written to the cache (write-through), or both.
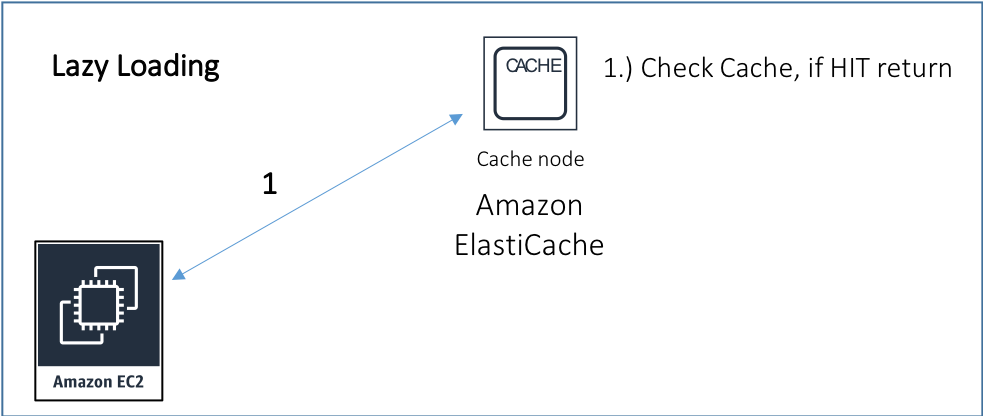
Lazy loading
With lazy loading, you assume that the object is already cached. If it isn’t, you cache it! Start by performing a GET operation on ElastiCache for Redis for a given key (for example, S3 bucket name: S3 Object Key name). If a value is returned, then the data was found, resulting in a cache hit.
Python example
r = redis.StrictRedis(host=redishost, port=6379)
### Query redis for a particular S3 object
value = r.get(S3bucket + ':' + S3ObjectKey)
if value is None:
print("cache miss")The github repo and setup instructions can be found here: https://github.com/aws-samples/amazon-S3-cache-with-amazon-elasticache-redis
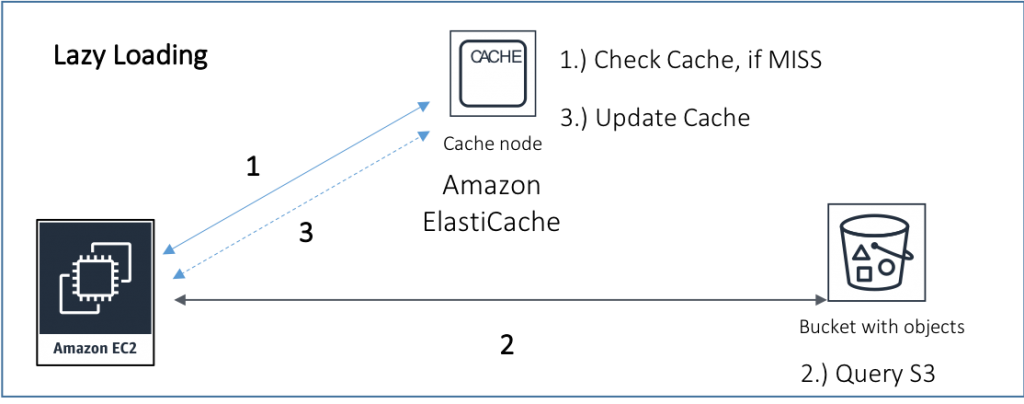
If the key was not found or the value was None (cache miss), then you have to query S3 and then store the object into ElastiCache for Redis.
Python example
r = redis.StrictRedis(host=redishost, port=6379)
s3 = boto3.resource('s3')
### Query redis for a particular S3 object
value = r.get(S3bucket + ':' + S3ObjectKey)
if value is None:
print("cache miss")
### Get data from S3
obj = s3.Object(S3bucket, S3ObjectKey)
data = obj.get()['Body'].read().decode('utf-8')
### Store the data into Redis
r.set(S3bucket + ':' + S3ObjectKey, data)
else:
print ("cache hit")
print("Data retrieved from redis = " + value)The github repo and setup instructions can be found here: https://github.com/aws-samples/amazon-S3-cache-with-amazon-elasticache-redis
Lazy loading is a common strategy for caching data, as it prevents you from filling the cache with data that may not be applicable. You could further optimize by applying a time-to-live (TTL) value to the data. TTL helps prevent retrieving stale data from the cache. Apply a TTL value that corresponds to the update activity associated to the underlying data.
Write through (cache-aside)

The other common technique includes creating a pipeline to update the cache as new data is written to S3, with an AWS Lambda function trigger. This enables you to keep your cache fresh as data is being written to S3. You also eliminate the initial round trip overhead found in a cache miss using lazy loading. It’s important to ensure that you apply a TTL value to keep your cache size manageable.
The combination of lazy loading and write through is ideal. Use the best practice of proactively hydrating the cache. If the data expires and is requested, then store the object back in the cache using lazy loading. The ideal scenario would be to enable a high probability of a cache hit by means of these two approaches. ElastiCache metrics in Amazon CloudWatch provides insights to cache hits and misses for additional analysis.
Putting it all together
I’ve put together a sample python application that allows you to conduct a simple performance test to measure the object retrieval latency against Amazon S3 and ElastiCache for Redis. The application calculates the average, minimum, and maximum latency of 100 GET requests against each service. The number of requests can also be modified directly within the scripts. In addition, there is a lazy loading example provided as well.
The github repo and setup instructions can be found here: https://github.com/aws-samples/amazon-S3-cache-with-amazon-elasticache-redis
An example of the performance results show latency improvement of 98.10%. For more accurate testing, you can use testing tools designed for load.

Conclusion
Amazon S3 and ElastiCache for Redis make an excellent pairing especially with high velocity and repeated object lookup workloads. S3 is the primary storage providing exceptionally high levels of durability and availability and ElastiCache for Redis is the secondary storage providing low latency and high throughput.