AWS Database Blog
Safely reduce the cost of your unused Amazon DynamoDB tables using on-demand mode
Imagine that you have thousands of Amazon DynamoDB tables for development and production environments. You want to decommission the tables that nobody uses, because that’s what the AWS Well-Architected Framework recommends for cost saving. How can you find unused tables quickly? Moreover, how to ensure you don’t incur any application availability impact after decommissioning the unused tables?
This post shows how to safely reduce DynamoDB I/O costs by applying on-demand mode to the unused tables instead of deleting them. DynamoDB on-demand mode is one of the two I/O capacity modes for provisioning read and write capacity of DynamoDB tables. In this post, you learn how to find unused tables programmatically, and how DynamoDB on-demand mode reduces your AWS usage cost safely.
How to define an unused DynamoDB table
Developers create DynamoDB tables with a handful of provisioned read capacity units (RCUs) and write capacity units (WCUs) for development or test purposes. However, you might make production tables with a considerable amount of provisioned RCUs and WCUs, or you might make tables using auto scaling with decent amount of minimum provisioned capacity. Occasionally, people forget to monitor if a table isn’t being used. It’s wasteful if a table was configured as provisioned capacity mode, because you’re charged for the provisioned capacities even though you haven’t consumed any I/O. Although each table’s waste amount looks small, it becomes a significant amount when consolidated across teams. To find these tables, you first need to define when a table is declared unused.
In this post, we define a DynamoDB table as unused if the table hasn’t had any read or write activity in the last 90 days, which we determine by checking the Amazon CloudWatch metrics for maximum consumed RCUs and maximum consumed WCUs are both zero in the last 90 days.
You can also change the time window if it suits your team’s environment. Defining such rules upfront and consistently evaluating the environment helps you reduce the churn of communications, especially if you deal with multiple AWS accounts that are managed by various teams in the company.
DynamoDB on-demand mode safely reduces the cost of unused tables
DynamoDB on-demand capacity mode isn’t just a flexible capacity mode, it’s also a billing option that can serve thousands of requests per second without capacity provisioning. It offers pay-per-request pricing for read and write requests so you pay only for what you consumed.
When you enable on-demand mode against unused tables, because they don’t have any I/O activity by the definition in this post, you aren’t charged for any provisioned RCUs or WCUs. Additionally, because the tables are still active, enabling on-demand mode doesn’t introduce risks of irreversible disruptions against dependent applications, if there are any.
Find unused DynamoDB tables
To find unused DynamoDB tables, you need to see past read and write activities. Such information is available by looking at two metrics from CloudWatch: maximum consumed RCUs and maximum consumed WCUs. If the maximum consumed RCUs and WCUs are zero in the past 90 days, it means that no one accessed the table over the last 90 days.
The following Node.js function assessTable gets a table name as input and determines if the table is unused based on these two CloudWatch metrics. This sample function also determines whether a given table is empty or has data in it.
Enable DynamoDB on-demand mode
You can use the DynamoDB UpdateTable CLI or its corresponding API to enable on-demand mode by specifying the --billing-mode parameter with the PAY_PER_REQUEST value:
The following Node.js function remediateWaste gets a table name along with its status, then enables on-demand mode if a table is active, has provisioned capacity mode, and isn’t being used:
Automate finding and remediating unused table wastes
To monitor unused table waste, you need to scan the list of tables and evaluate if each table is unused periodically, such as weekly or daily. After you identify the tables, you can delete them manually or enable on-demand mode programmatically to automate I/O waste remediations. For this post, let’s assume you want to automate the identification and remediation process.
To get the list of DynamoDB tables, you can use the ListTables API or list-tables CLI:
For each table, you need to check the CloudWatch metrics to determine if tables are unused, then enable on-demand mode. Although we recommend doing this daily, such as every morning, you can choose your preferred interval, such as weekly or monthly.
Now let’s see how you can automate such tasks using AWS Lambda and CloudWatch Events. Because we implemented the assessTable and remediateWaste functions, we implement a Lambda main handler, which retrieves the list of tables and invokes the preceding Node.js functions. The following code is the sample implementation of the Lambda main handler:
This main handler function gets the list of DynamoDB tables, calls the assessTable() function to determine if any table is unused, then calls remediateWaste() to enable DynamoDB on-demand mode.
Solution architecture
The following diagram shows our solution architecture. It periodically finds and remediates the wasted cost of unused DynamoDB tables in the AWS account’s Region where the solution is deployed.
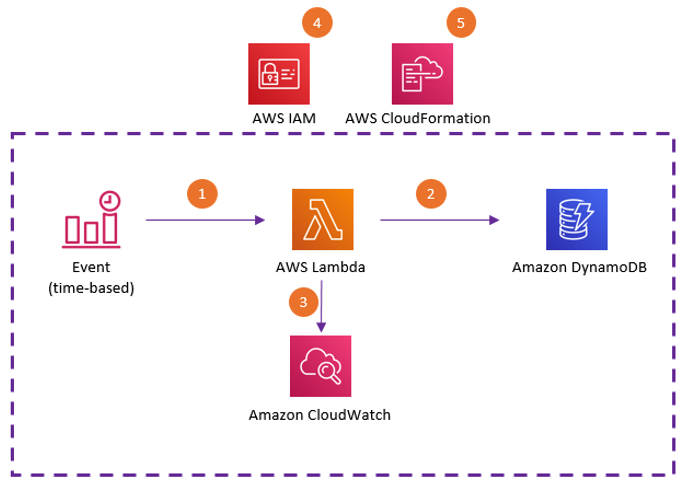
The solution includes the following steps:
- CloudWatch Events runs the Lambda function on a scheduled basis, such as 3:00 AM every day.
- An AWS Identity and Access Management (IAM) role is attached to the Lambda function to allow access to DynamoDB and CloudWatch.
- The function retrieves the list of DynamoDB tables in a Region.
- The function checks the item count of the table and the read and write capacity consumptions via CloudWatch metrics to identify empty unused tables.
- The function enables DynamoDB on-demand mode for the unused tables.
Package the solution as an AWS CloudFormation template
Let’s bundle the solution together as an AWS CloudFormation template.
- Store the preceding Node.js code as a JavaScript file named
ddbRemWaste.js. - Compress and save it as
ddbRemWaste.zip. - Upload the ZIP file to your Amazon Simple Storage Service (Amazon S3) bucket so you can point to the ZIP file as the source code location of the Lambda function, which you create via the CloudFormation template.
To deploy the solution, you need to implement a CloudFormation template that creates the following resources:
- An IAM role that allows access to the DynamoDB and CloudWatch APIs. This role is attached to the Lambda function.
- A Lambda function that is the runtime container of your Node.js code.
- A CloudWatch event that invokes the Lambda function one time per day.
The following code shows a sample CloudFormation template:
Deploy the CloudFormation stack
Now we’re ready to deploy the solution as a CloudFormation stack. The following steps provision your waste remediation solution in just a few minutes.
- On the AWS CloudFormation console, choose Create stack.
- On the Select template page, choose Upload a template to Amazon S3.
- Choose Choose File.
- Choose the
remediateWaste_FC.yamltemplate you created earlier. - Choose Next.
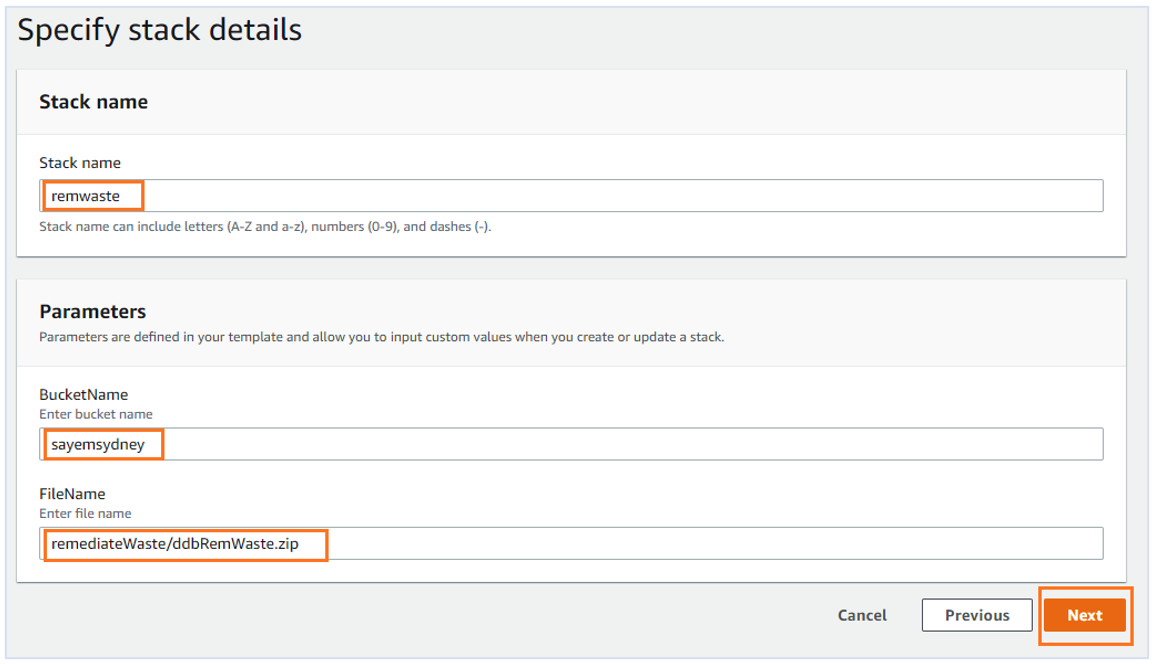
- For Stack name, enter a name.
- For BucketName, enter a name.
- For FileName¸ enter the name of the ZIP file you uploaded to S3.
- Choose Next.

- Keep the default settings on the Options page and choose Next.
- Select I acknowledge that AWS CloudFormation might create IAM resources.
- Choose Create stack.


AWS CloudFormation creates the resources based on the template definitions. Stack creation can take a few minutes to complete.

Test the solution
You have successfully created the CloudFormation stack. The CloudWatch rule, which the stack created for you, invokes the Lambda function one time per day. The function discovers empty or unused DynamoDB tables and enables on-demand mode to prevent unnecessary costs of provisioned read and write capacities. To see it in action, let’s do a quick test to see how it works!
- On the CloudWatch console, choose Rules.
- Search for the rule and choose the CloudFormation stack
remwaste.The following screenshot shows the CloudWatch Events rule is scheduled to invoke the Lambda function every day.

- Choose the Resource name to open the Lambda function created by CloudFormation.
- On the Lambda console, choose Test.
- On the Configure test event page, enter an event name.
- Accept the default value and choose Create.
- Choose Test to manually invoke the Lambda function.

- Wait for the Lambda function to complete the job.
The function checks all of your DynamoDB tables’ consumed read and write capacity metrics in the given AWS Region, and enables on-demand mode if any table is empty or unused. - On the DynamoDB console, check if any empty or unused table’s capacity mode has changed to on-demand mode.




Considerations
Despite the convenient automations in this solution, you still have some manual tasks to perform.
First, be sure to deploy this solution in the AWS account and Region where your DynamoDB tables reside. To monitor all the DynamoDB tables, you need to deploy this solution in every AWS account and Region where your applications reside. Alternatively, you can revise the Lambda function to monitor multiple Regions in the account.
Second, on-demand mode only saves I/O provisioning costs, not storage costs. Empty tables don’t count because they don’t have any data. But for the unused tables with data in them, DynamoDB still charges for storage. The only way to reduce your storage cost, besides the read and write capacity provisioning cost, is to delete the items from the table or to delete the table entirely.
Third, the CloudFormation stack’s DynamoDB resource state becomes inconsistent after the Lambda function enables on-demand mode for the unused tables. If you deployed the DynamoDB tables using AWS CloudFormation, such configuration inconsistencies may confuse your DevOps teams.
Lastly, DynamoDB only allows capacity mode changes one time every 24 hours. If you manage the tables via AWS CloudFormation along with CI/CD pipelines, you need to make sure to let the pipelines know that DynamoDB tables have been changed. Otherwise, the pipeline might struggle to revert the DynamoDB capacity mode back to the original provisioned capacity mode and fail.
For these reasons, we encourage you to manually sweep the DynamoDB tables at least one time a month. Check which tables are switched to on-demand mode, confirm if the tables are unnecessary, and delete the tables. To find such tables efficiently, you can let the Lambda function give the list of unused table names via an Amazon Simple Notification Service (Amazon SNS) topic and automate the table deletion from there. For more information about read and write capacity mode changes, see Considerations When Changing Read/Write Capacity Mode.
Conclusion
In this post, we showed you how you can reduce DynamoDB costs by enabling on-demand mode for empty or unused tables. When you use on-demand mode instead of deleting DynamoDB tables, you can stop billing on provisioned capacities for empty or unused tables. This technique comes in handy when you have many DynamoDB tables and don’t have time for manual housekeeping.
It is one of the most straightforward ways for reducing costs to decommission unused resources, because you save the costs by deleting them. But still, you want to ensure such decommissioning does not cause any trouble to the upstream systems. By leveraging DynamoDB on-demand mode, you can easily reduce the DynamoDB I/O costs first while you’re checking if it is adequate to delete the tables. After that, you can safely delete them if it is okay to do so.
For more details about cost optimization best practices, check out the Cost Optimization Pillar – AWS Well-Architected Framework.
About the authors
 Jongnam Lee is the Lead Solutions Architect of the AWS Well-Architected Analytics Lens program. As a tenured Amazonian who joined the company in 2012, he has served in various roles in both AWS and Amazon.com, including Amazon.com’s data lake operations and AWS cost optimization initiatives in 2018–2020. He returned to AWS in August 2020 to help customers and partners build well-architected analytics solutions.
Jongnam Lee is the Lead Solutions Architect of the AWS Well-Architected Analytics Lens program. As a tenured Amazonian who joined the company in 2012, he has served in various roles in both AWS and Amazon.com, including Amazon.com’s data lake operations and AWS cost optimization initiatives in 2018–2020. He returned to AWS in August 2020 to help customers and partners build well-architected analytics solutions.
 Masudur Rahaman Sayem is a Specialist Solution Architect for Analytics at AWS. He works with AWS customers to provide guidance and technical assistance on data and analytics projects, helping them improve the value of their solutions when using AWS. He is passionate about distributed systems. He also likes to read, especially classic comic books.
Masudur Rahaman Sayem is a Specialist Solution Architect for Analytics at AWS. He works with AWS customers to provide guidance and technical assistance on data and analytics projects, helping them improve the value of their solutions when using AWS. He is passionate about distributed systems. He also likes to read, especially classic comic books.