AWS Architecture Blog
A multi-dimensional approach helps you proactively prepare for failures, Part 1: Application layer
Resiliency of applications surpasses everything else in building customer trust. Because of this, it cannot be an afterthought. Instead of simply reacting to a failure, why not be proactive?
As your system expands, you’ll likely encounter issues that can hinder your ability to scale, like security and cost. So, it’s necessary to think about the correct architectural patterns beforehand to minimize your chances of enduring a failure without a recovery plan.
In this multi-part blog series, we’ll show you how to take a multi-dimensional approach to ensure your applications, infrastructure, and operational processes can detect points of failure and can gracefully react if (and inevitably when) a failure occurs.
In each part of the series, we recommend resiliency architecture patterns and managed services to apply across all layers of your distributed system to create a production-ready, resilient application. This post, Part 1, examines how to create application layer resiliency.
Example use case
To illustrate our recommendations for building an effective distributed system, we’ll consider a simple order payment system. Figure 1 shows our base implementation. The real-time part of the distributed system is built with:
- An Amazon Route 53 DNS server resolves the website IP address and forwards the request to an Amazon CloudFront cloud delivery network (CDN)
- The CDN caches and delivers the static website content stored in Amazon Simple Storage Service (Amazon S3) object storage
- Application Load Balancersserve dynamic content for the backend APIs with load balancing
- Amazon ElastiCache caches the response for quick retrieval
- Amazon Aurora, a persistent, purpose-built database, stores the response
- Amazon OpenSearch Service built-in text-search allows users to search the UI
This system is transactional so far, but we need to aggregate and analyze data. We do this using Amazon Simple Queue Service (Amazon SQS), AWS Lambda, AWS Step Functions, Amazon S3, and Amazon Athena. Amazon Kinesis Data Firehose and Amazon Redshift populate the data warehouse via their data pipelines. Amazon QuickSight helps us visualize the data.
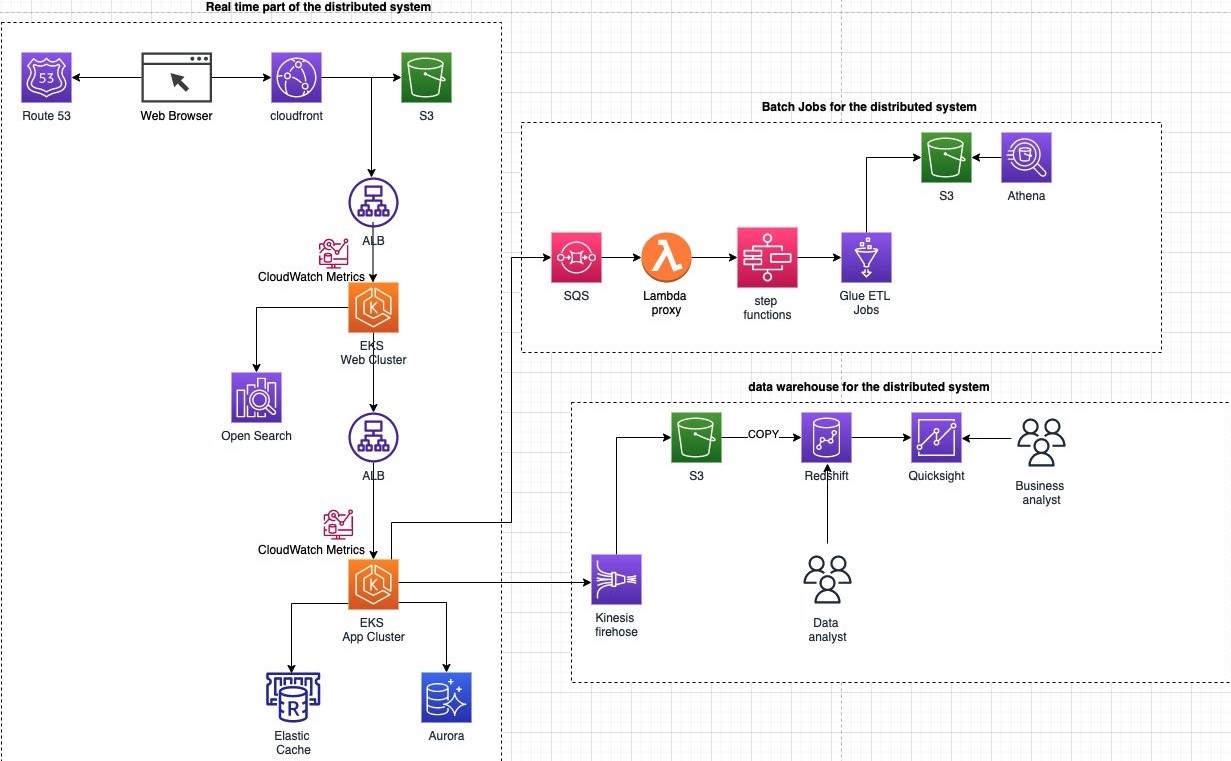
Figure 1. Architecture components of a distributed system
Next, let’s look into distributed architectural patterns we could apply to the base implementation to bolster resiliency and common tradeoffs you need to consider for each.
Pattern 1: Microservices
Microservices are building blocks for smaller, domain-specific services. As shown in the Microservices on AWS whitepaper, microservices offer many benefits. They reduce the blast radius of any failure, require smaller teams to manage them, and simplify deployment pipelines to get them into production.
Tradeoffs and their workarounds
If your distributed system is comprised of several smaller services, a failure or inability to respond to failures in one service might affect other services in the chain.
To help with this, consider implementing one or more of the following patterns.
Circuit breaker pattern
Like an electrical circuit breaker, the circuit breaker pattern stops cascading failures. You can implement it as an orchestrator, at an individual microservice level, and/or in a service mesh across multiple services to detect timeouts and track failures across services, which prevents a distributed system from getting overwhelmed.
Retries with exponential backoff and jitter
A common way to handle database timeouts is to implement retries. However, if all the transactions retry at the same interval, it might choke the network bandwidth and throttle the database.
We recommend introducing exponential backoff and jitter to the retries and to introduce an element of randomness in the retry interval.
Let’s see this in action. Consider the backend implementation of the order payment system in our example use case, as shown in Figure 2.

Figure 2. Backend processing of order payment system
For incoming orders, the payment process must succeed for the order to be processed. To ensure latency in the payments database writes does not affect the transactions that read from the database for the order processing UI:
- Isolate reads and writes with a read-replica
- Use an Amazon RDS Proxy to handle connection pools and use throttling to help with preventing database congestion and locking
- Introduce exponential backoff to increase the time between subsequent retries of failed requests. Combine this approach with “jitter” to prevent large bursts of retries
Figure 3 compares recovery time with exponential backoff to exponential backoff combined with jitter:

Figure 3. Recovery time graph for exponential backoff with and without jitter
Health checks and feature flags
If you’ve deployed new functionality in production and it doesn’t work as expected, use feature flags to turn it off rather than roll back the deployment. This helps you reduce operational complexity and downtime. See the Automating safe, hands-off deployments article for more information.
The load balancer uses periodic automatic health checks to determine if the backend service is healthy and can serve traffic. Figure 4 shows you where to use shallow and deep health checks:
- Use shallow health checks to probe for host/local failures on a server resource (for example, liveliness checks).
- Probing for dependency failures needs a deep health check. Deep health checks will give you a better understanding of the health of the system, but they’re expensive, and a dependency check failure can cause cascading failure throughout the system.

Figure 4. Shallow vs deep health checks
Pattern 2: Saga pattern
A saga pattern keeps your data consistent across microservices when a transaction spans multiple services. It updates each service with a message or event to prompt the service to move to the next transaction step.
For example, in our order payment system, a transaction is considered successful if the payment for that order is processed.
Tradeoffs and their workarounds
The saga pattern is great for long transactions. However, if a step in the process cannot complete, you’ll need compensating transactions in place to undo any changes from previous steps. For example, as shown in Figure 5, if the payment fails, the customer’s order must be canceled.
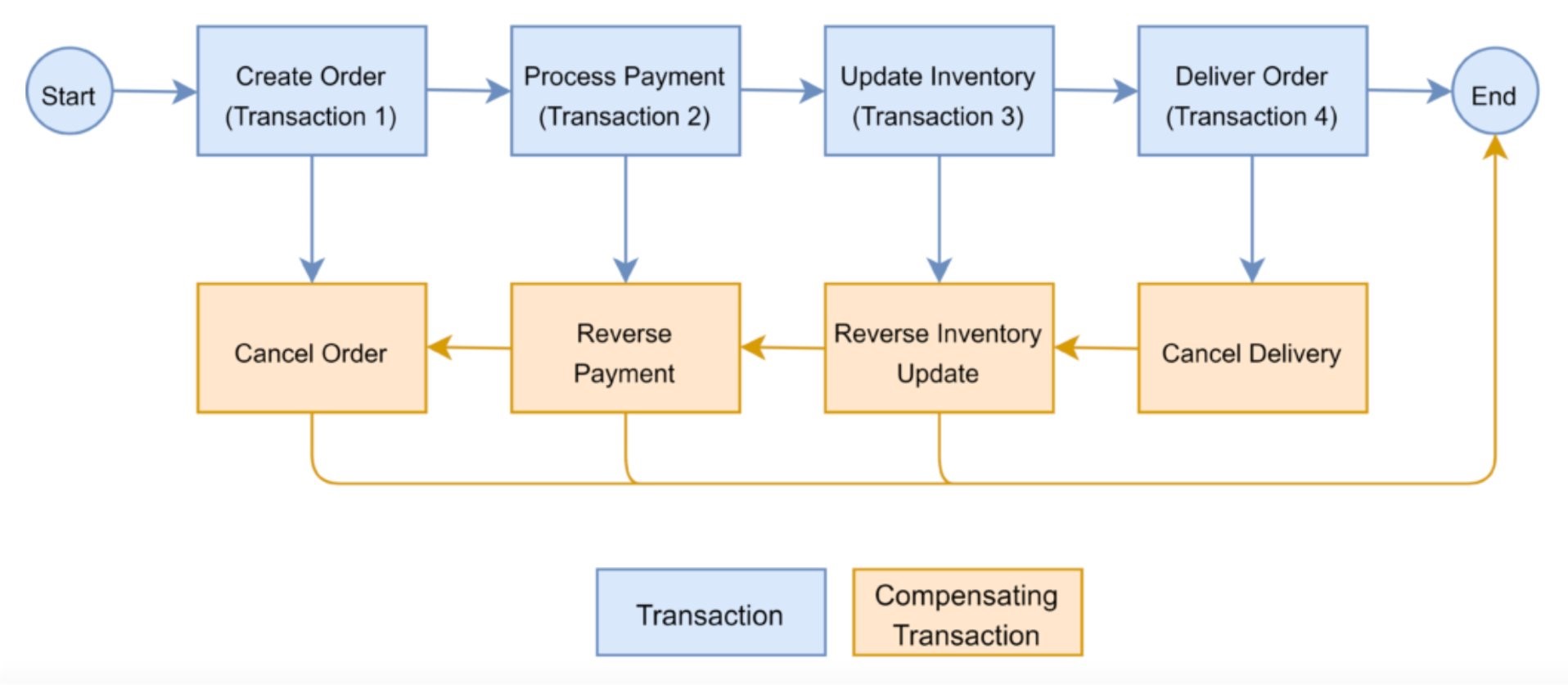
Figure 5. The saga pattern coordinates transactions across a system of microservices
Consider implementing the following pattern to set up compensating transactions.
Serverless saga pattern with Step Functions
We recommend using a serverless orchestrator in Step Functions to roll back to a previous step in an order. Figure 6 shows the serverless orchestrator and how its lightweight, centralized control service coordinates the flow across microservices. It performs compensating transactions during failure scenarios to ensure that if one microservice fails, the others will not.

Figure 6. Step Functions as serverless orchestrators
Pattern 3: Event-driven architecture
An event-driven architecture uses events to communicate between decoupled services. By decoupling your services, they are only aware of the event router, not each other. This means that your services are interoperable, but if one service has a failure, the rest will keep running. The event router acts as an elastic buffer that will accommodate surges in workloads.
Tradeoffs and their workarounds
An event-driven architecture provides multiple implementation options. Carefully consider your system’s distinct attributes and scaling and performance needs to decide on a suitable approach.
The mind map in Figure 7 shows when to use an event-driven pattern, our recommendations for implementation, tradeoffs and their workarounds, and anti-patterns:
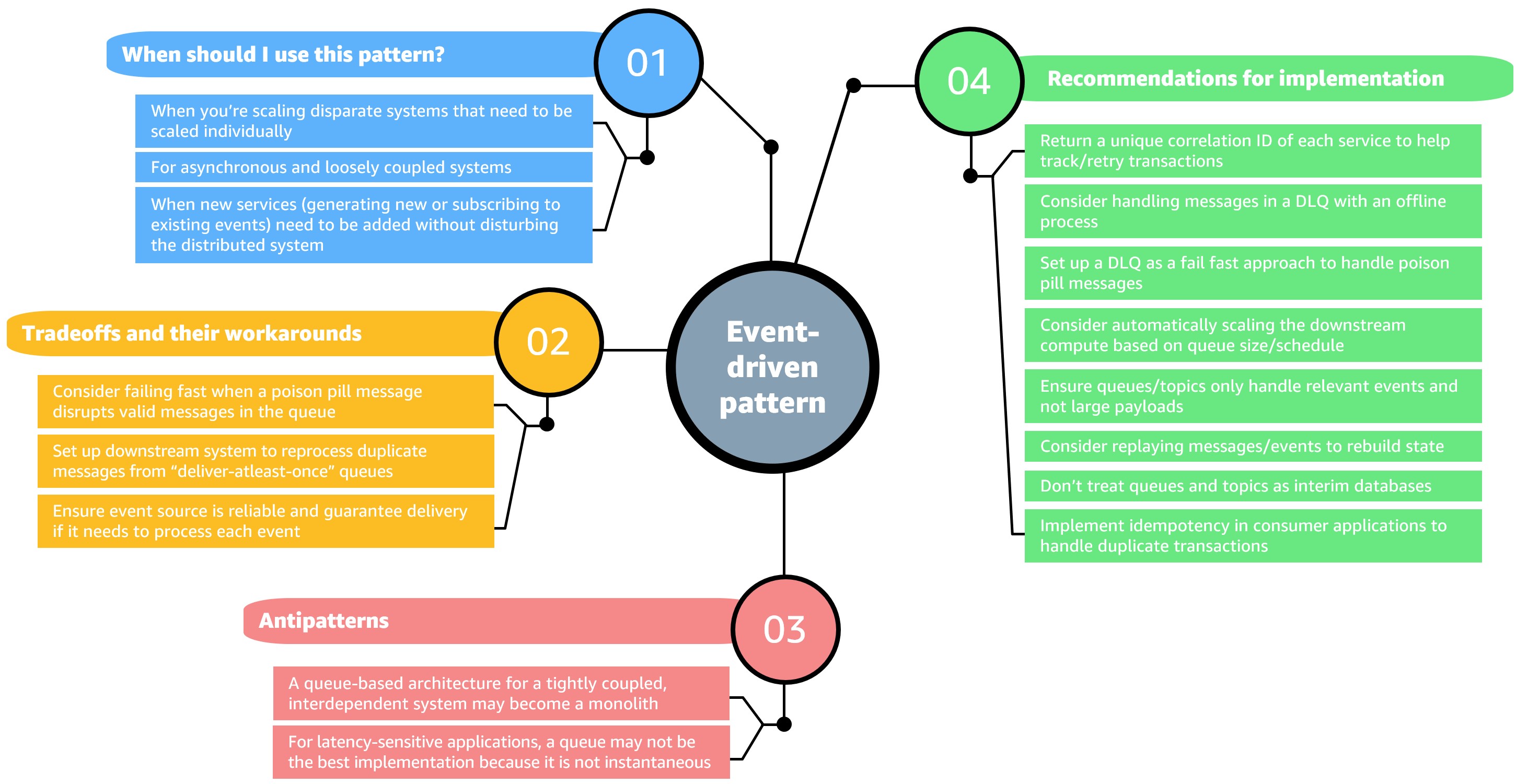
Figure 7. Decision criteria for event-driven architecture pattern (click the image to enlarge)
Pattern 4: Cache pattern
Deploying stateless redundant copies of your application components, along with using distributed caches, can improve the availability of your system. This allows your infrastructure to scale in response to user requests.
Tradeoffs and their workarounds
Caches have multiple configuration options. Carefully consider your system’s distinct attributes and scaling and performance needs to decide on a suitable approach.
The mind map in Figure 8 shows when to use a cache pattern, our recommendations for implementation, tradeoffs and their workarounds, and anti-patterns:

Figure 8. Decision criteria for cache pattern (click the image to enlarge)
Improving application resiliency with bounded contexts
Loosely coupled services improve availability more than only creating redundant copies of your applications. Figure 9 shows the benefits of a loosely coupled system versus a tightly coupled system.
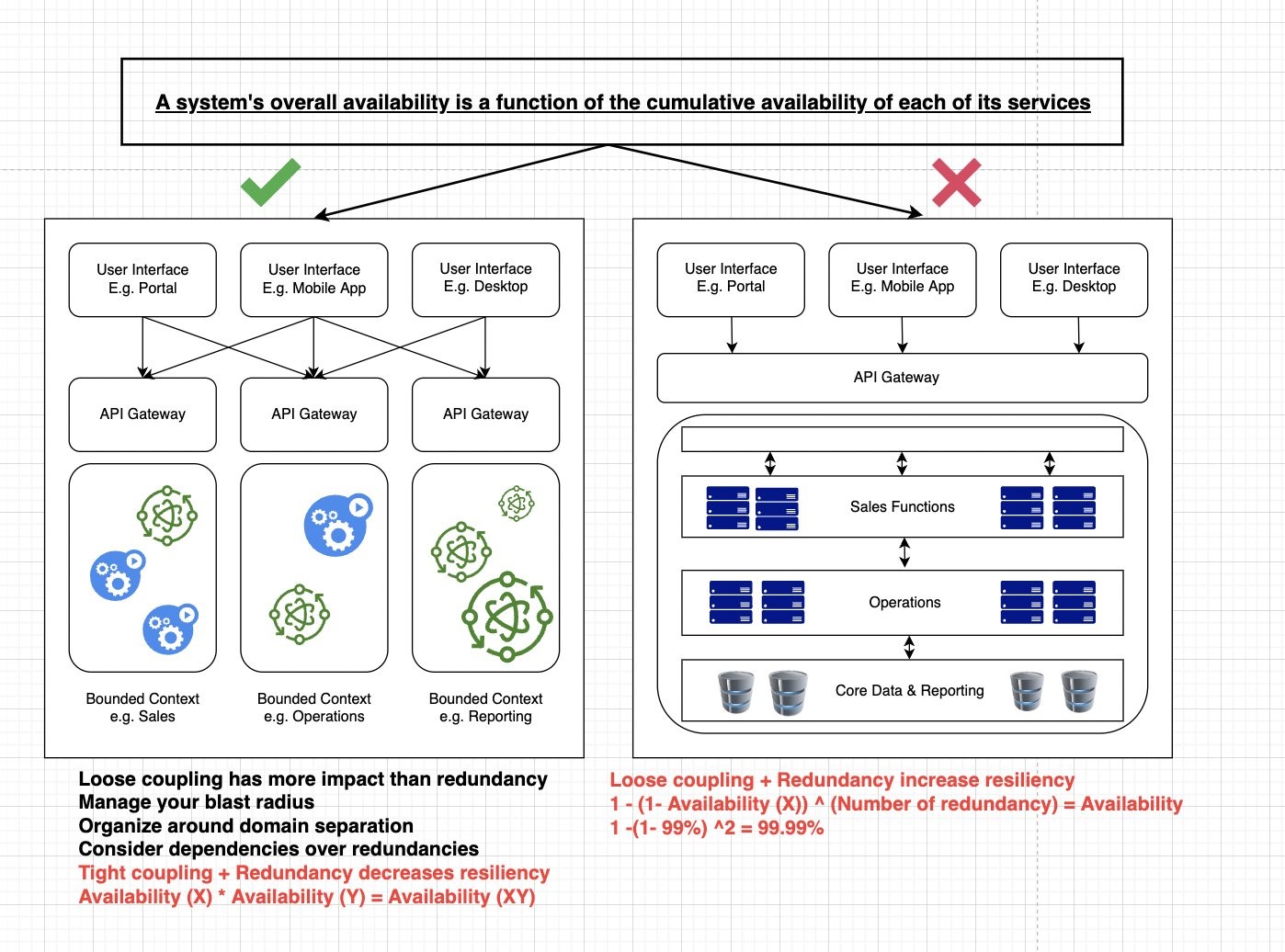
Figure 9. Relationship between loose coupling and availability
Conclusion
In this post, we learned about various architecture patterns and their tradeoffs, and provided recommendations on how to gracefully mitigate failures before they happen.
Distributed systems can use all of these patterns, which helps improve resiliency at the application layer. Applying these patterns, along with the Infrastructure and Operations improvements discussed in parts 2 and 3, will provide frameworks for resilient applications.