AWS News Blog
AWS Data Pipeline Update – Parameterized Templates
AWS Data Pipeline helps you to reliably process and move data between compute and storage services running either on AWS on on-premises. The pipelines that you create with Data Pipeline’s graphical editor are scalable and fault tolerant, and can be scheduled to run at specific intervals. To learn more, read my launch post, The New AWS Data Pipeline.
New Parameterized Templates
Today we are making Data Pipeline easier to use by introducing support for parameterized templates, along with a library of templates for common use cases. You can now select a template from a drop-down menu, provide values for the specially marked parameters within the template, and launch the customized pipeline, all with a couple of clicks.
Let’s start with a quick tour and then dig in to details. The Create Pipeline page of the AWS Management Console contains a new menu:
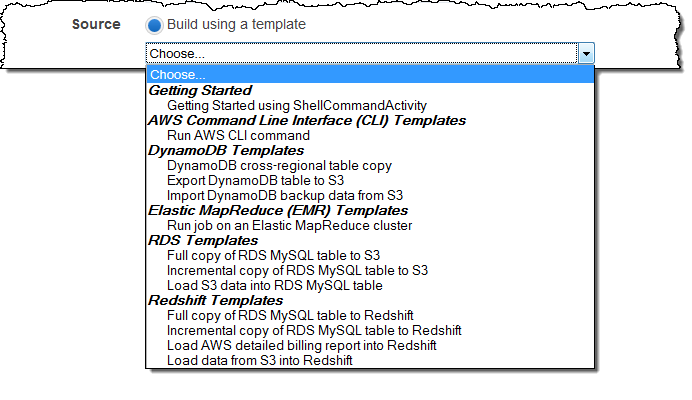
As you can see from the menu, you can access templates for jobs that use the AWS Command Line Interface (AWS CLI), Amazon DynamoDB, Amazon EMR, Amazon Relational Database Service (RDS), and Amazon Redshift. We plan to add more templates later and are open to your suggestions!
I chose Run an Elastic MapReduce job flow. Now all I need to do is to fill in the parameters for the job flow:
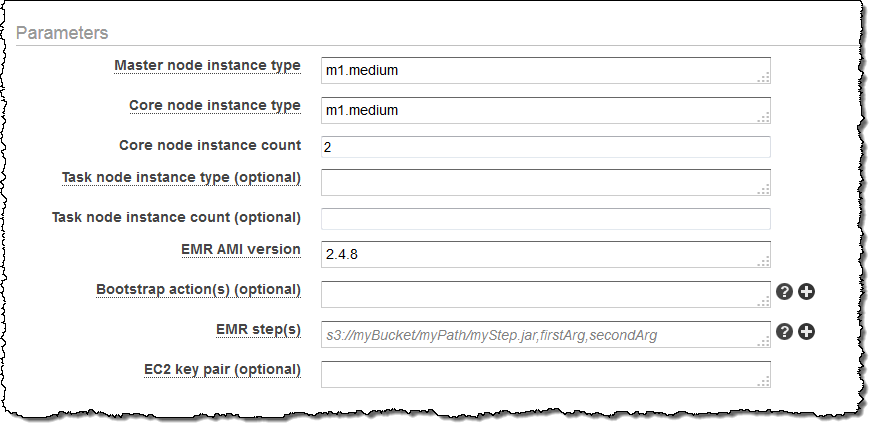
The “+” next to some of the parameters indicates that the template makes provision for an array of values for the parameter. Clicking on it will add an additional data entry field:

You can use these templates as a starting point by editing the pipeline before you activate it (You can download them from s3://datapipeline-us-east-1/templates/).
How it Works
Each template is a JSON file. Parameters are specified like this (this is similar to the syntax used by AWS CloudFormation):
{
"parameters":[
{
"id": "mys3OutputBucket",
"type":"AWS::S3::ObjectKey",
"description":"S3 output bucket",
"default ":"s3://abc"
},
{
"id" : "myobjectname"
"type" : "String",
"description" : "Object name"
}
]
}
Parameters can be of type String, Integer, or Double and can also be flagged as isArray to indicate that multiple values can be entered. Parameters can be marked as optional; the template can supply a default value and a list of acceptable values if desired.
The parameters are very useful for late binding of actual values. Organizations can identify best practices and encapsulate them in Data Pipeline templates for widespread use within and across teams and departments.
You can also use templates and parameters from the command line and the Data Pipeline API.
Available Now
This feature is available now and you can start using it today.
— Jeff;