AWS Partner Network (APN) Blog
Accelerate Business Changes with Apache Iceberg on Dremio and Amazon EMR Serverless
By Jason Hughes, Director of Technical Advocacy – Dremio
By Veena Vasudevan, Sr. Partner Solutions Architect – AWS
 |
| Dremio |
 |
Enterprises powered by data and analytics solutions often go through changes in their evolution journey, such as surges in data volumes, modifications to schemas, unanticipated need for integration, and interoperability.
In traditional systems, when these changes occur to datasets or tables, it takes a lot of time and effort for businesses to adopt them safely. This inconveniences data teams by interrupting the continuous flow of data to the consumers.
In this post, we discuss how you can leverage Apache Iceberg capabilities with Dremio and Amazon EMR Serverless to scale your business by keeping up with various changes to your data and analytics portfolio.
Apache Iceberg is a high-performance, open table format for huge analytical tables specifically designed to mitigate the challenges introduced by unforeseen changes observed by enterprises. Iceberg enables data teams to quickly, easily, and safely keep up with data and analytics changes, which in turn helps businesses realize fast turnaround times to process the changes end-to-end.
Dremio is an AWS Data and Analytics Competency Partner and AWS Marketplace Seller whose data lake engine delivers fast query speed and a self-service semantic layer operating directly against Amazon Simple Storage Service (Amazon S3) data. Dremio combines an Apache Arrow-based query engine with acceleration technologies to provide 10-100x faster query performance.
Schema Evolution
Large datasets in enterprises often go through structural changes over time, which brings about the need for modifications to the table schema.
Traditionally, table schema is tightly coupled with the file format. These changes may even require having to rewrite and reprocess the entire table.
Also, different tools used to interact with the data may process this schema change differently, which may lead to different results. Using Apache Iceberg, you can safely and quickly change the table’s schema without having to rewrite the entire table. These changes are observed and processed by other engines and tools consistently.
Partition Evolution
For large enterprise tables, when there are changes to the querying or data ingestion pattern—from once a day to once an hour, for example—partition schemes of these tables may also need to be modified for achieving optimal performance.
Partitioning columns are chosen during the time of table creation. In traditional file formats, changing the partitioning scheme of a table entails rewriting the entire table, which can be expensive at scale and burdensome to both data producers and consumers.
Apache Iceberg offers a feature called partition evolution which enables users to change the partitioning scheme of a table without any negative impact to data producers or consumers. Iceberg’s hidden partitioning feature allows data producers and consumers to continuously use the table without any interruptions or downtimes, and without any prior knowledge about the changes made to the partitioning scheme.
Object Store File Layout
When large datasets are stored on top of cloud object storage solutions such as Amazon S3, there are specific limits imposed on how many requests can be made per second to files with the same prefix, analogous to the same directory.
With Amazon S3, you can achieve 3,500 PUT/COPY/POST/DELETE or 5,500 GET/HEAD requests per second, per partitioned prefix. There are no limits to the number of prefixes in a bucket.
Traditional table formats often lay files out on the storage under each partition of the table which corresponds to an S3 prefix. These partitions or prefixes are often not randomized enough to achieve the potential requests per second offered by S3. Hence, when the datasets grow larger in volume, scalability or performance issues may be observed at the storage layer, such as the 5xx errors.
Apache Iceberg solves those performance bottlenecks with object store file layout, which adds a randomized string of characters as the first prefix for each data file, effectively resolving the issue of the limited rate of requests the object storage places on table prefixes.
Make Business and Analytics Changes Fast, Easy, Safe
In this section, we leverage the fundamental capabilities of Apache Iceberg to apply business and analytical changes efficiently and reliably. For all of the examples, we have used a subset of the AWS Public Blockchain dataset from the AWS Registry of Open Data.
To create and modify Apache Iceberg tables, we have use Amazon EMR Serverless and Dremio to query the Iceberg tables. Please note you can also use Dremio to create and modify these datasets.
Let’s create an Amazon EMR Serverless application and submit a Spark job to create the databases and Iceberg tables on the AWS Public Blockchain datasets. Here’s how to get the commands we used for this setup.
Once the tables are created, we use Dremio to run interactive queries on the data. For example, we run the following query to get the token balance aggregated by addresses.
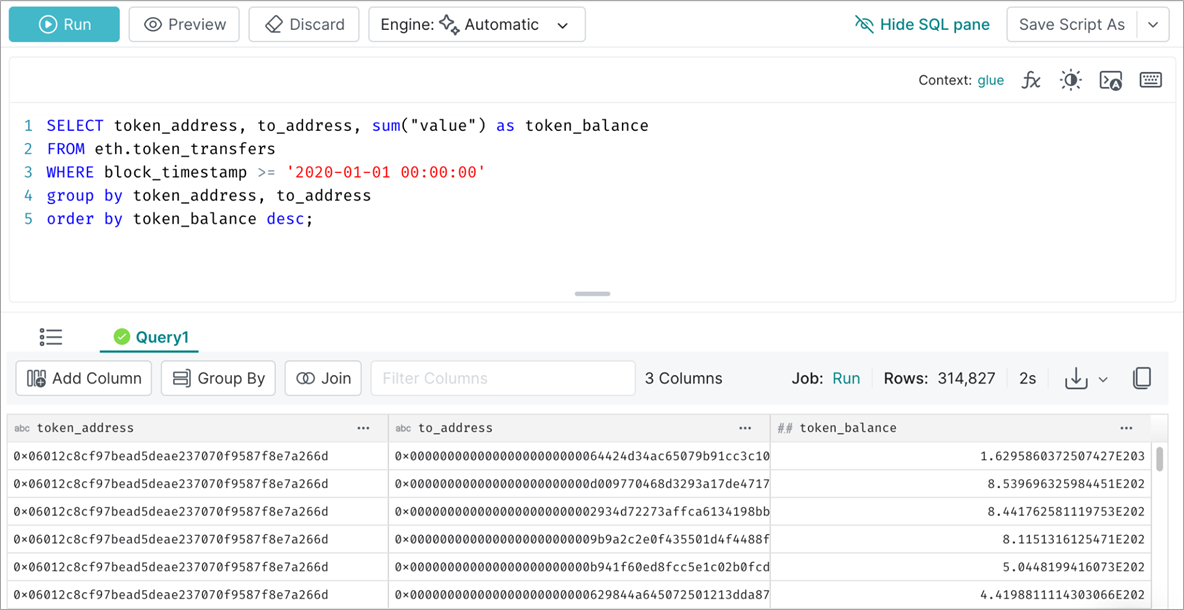
Figure 1 – Query the Ethereum token transfers Iceberg table from Dremio.
Changes in source applications may necessitate modifications to the table schema for both upstream reasons (for example, a new functionality implemented in the application) and downstream reasons (new business questions requiring additional data from the application). This results in requirements such as renaming a column, adding or removing a column, and changing data type of a column.
Next, we use Apache Iceberg to perform schema evolution required for changes in the source application. For this purpose, we use two of the tables created by the Spark job in AWS Glue Data Catalog. The schema of these two tables:
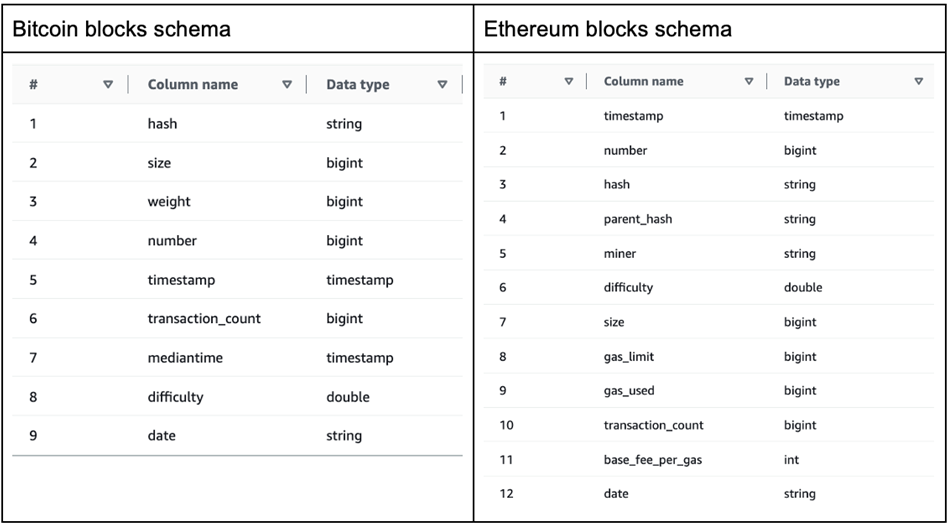
Figure 2 – Original table schemas of Bitcoin blocks and Ethereum blocks.
Let’s assume we have received the following requirements due to some unexpected changes in the upstream and downstream processes. These requirements can be accomplished with simple ALTER TABLE statements.
- Add an additional column named “difficulty_label” to indicate the level of mining difficulty and remove the “weight” column to comply with the changes in the querying patterns from the data consumers.
- Rename “timestamp” and “mediantime” columns as it’s reported to be confusing for the data consumers. Meanwhile, “timestamp” provides the exact time when a block has been mined and validated by the network, and “mediantime” is the median of past 11 timestamps.
- Change the datatype of column “base_fee_per_gas” from INT to BIGINT since the fees have increased considerably. The column “base_fee_per_gas” will start receiving “long” type input.
We ran this EMR Serverless Spark job to apply the above schema changes to our Iceberg tables. After this, we observe the table schema changes.
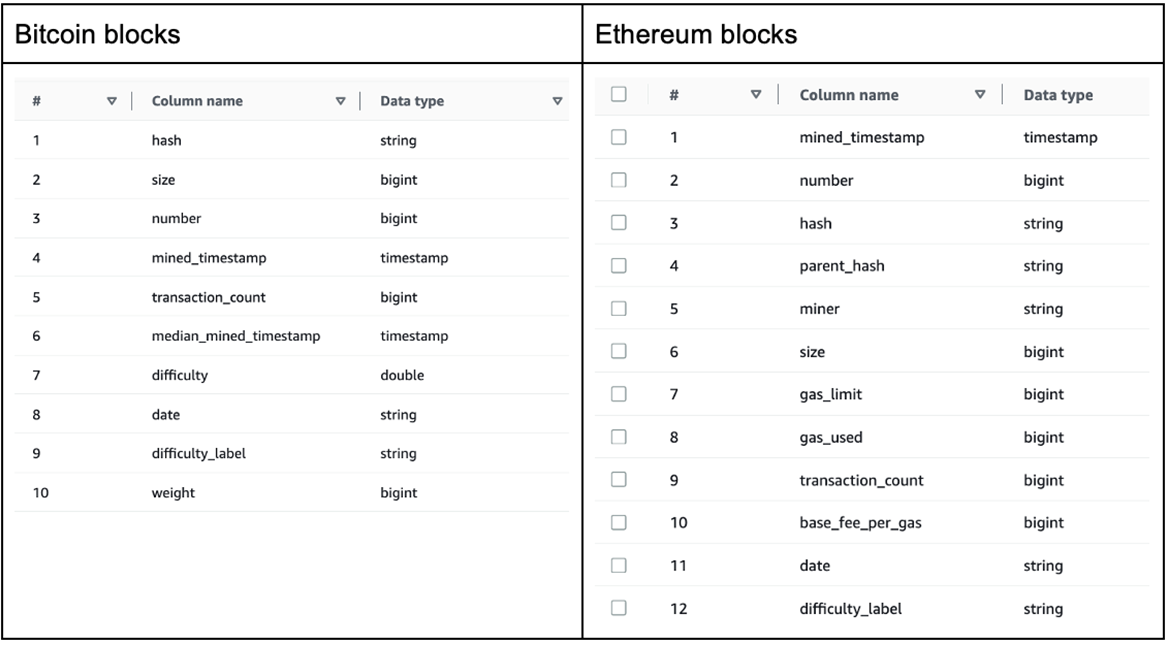
Figure 3 – Table schemas of Bitcoin blocks and Ethereum blocks after evolution.
Dremio can now pick up these changes and continue to work with the tables without any downtimes.
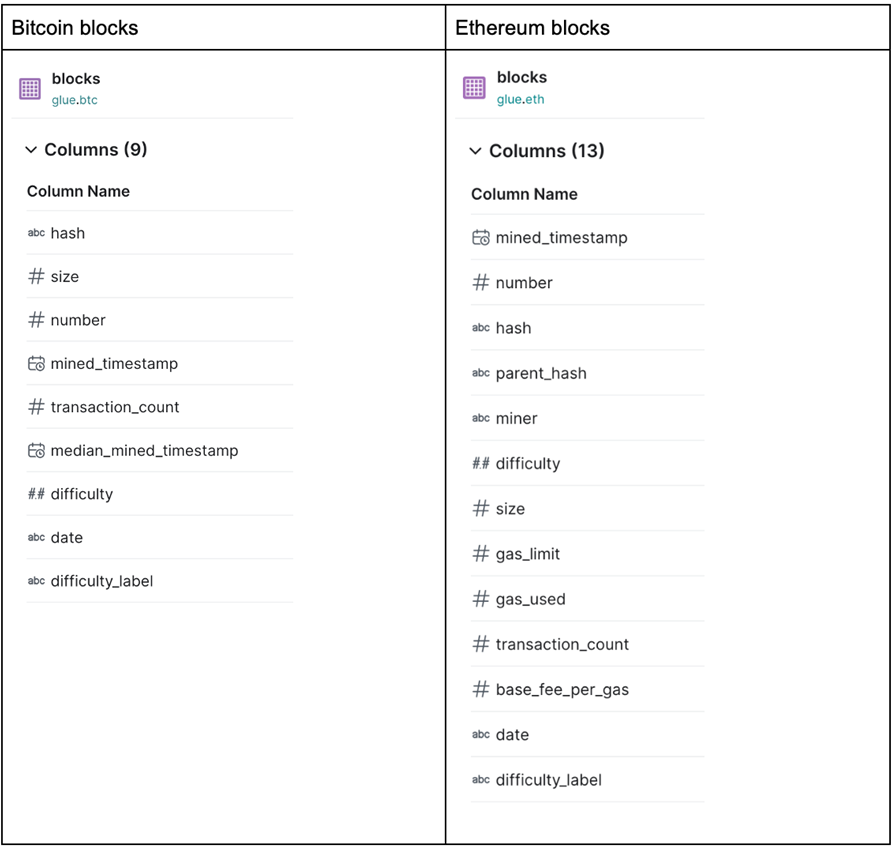
Figure 4 – Bitcoin blocks and Ethereum blocks schema changes observed from Dremio.
Data Scale Increases
Drastic changes in data volumes are commonplace in enterprises. Technologies supporting business use cases should be able to scale quickly in accordance with the surges in data volumes, and provide the same capabilities and performance expected, irrespective of the growth rate.
Because Apache Iceberg was created at Netflix to solve many of the problems they were seeing at the scale, multiple capabilities are built into Iceberg to ensure seamless scalability.
Let’s assume the data volume in a business-critical table has increased rapidly over the past few days, to the point where analytics consumers of the table are getting significantly backlogged.
With data coming in so quickly, even a dashboard that only needs a couple hours of data has started to miss the load time service-level agreement (SLA) accentuated by the fact the table is partitioned on the “date” column. With Apache Iceberg, we can easily modify the partitioning scheme of the table from daily to hourly partitions with a simple query.
Once the table is altered, any new rows inserted into the table will adhere to the hourly hidden partitioning strategy. We ran this EMR Serverless Spark job to apply hidden partitioning on our dataset. The table schema and layout of the older prefixes have not changed.
We then ran the following INSERT query from the Spark job we submitted.
Now, the partition prefix “mined_timestamp_hour” is added in the underlying dataset on S3.
With the hidden partitioning strategy, enterprises are able to take full advantage of the new performance optimizations without having to make any application changes on the consumer side. There is no change to the underlying partition structure on the existing datasets.
Hence, we’ll be able to continue using the date partition column for queries on the old datasets. When we query the table as a consumer, Dremio handles the hidden partitioning automatically and optimizes the query accordingly.

Figure 5 – Read the Blocks table with hidden partitioning applied from Dremio.
Let’s assume that the Ethereum transfers have been increasing exponentially over the past few days. In order to handle these sudden and unexpected data surges, we make use of the object store file layout capability of Iceberg. We created a table called “eth.token_transfers” from the first Spark job we ran which uses the object store file layout.
To use this layout, we specify the options “write.object-storage.enabled” and “write.data.path” during table creation.
Under the write data path, we observe the hash prefixes are created in S3 corresponding to each data file, such that every file is mapped to a single hash prefix.
Despite the changes in the storage layout of the underlying data files, no application change is required in the readers and writers. This feature can be leveraged seamlessly by Dremio.
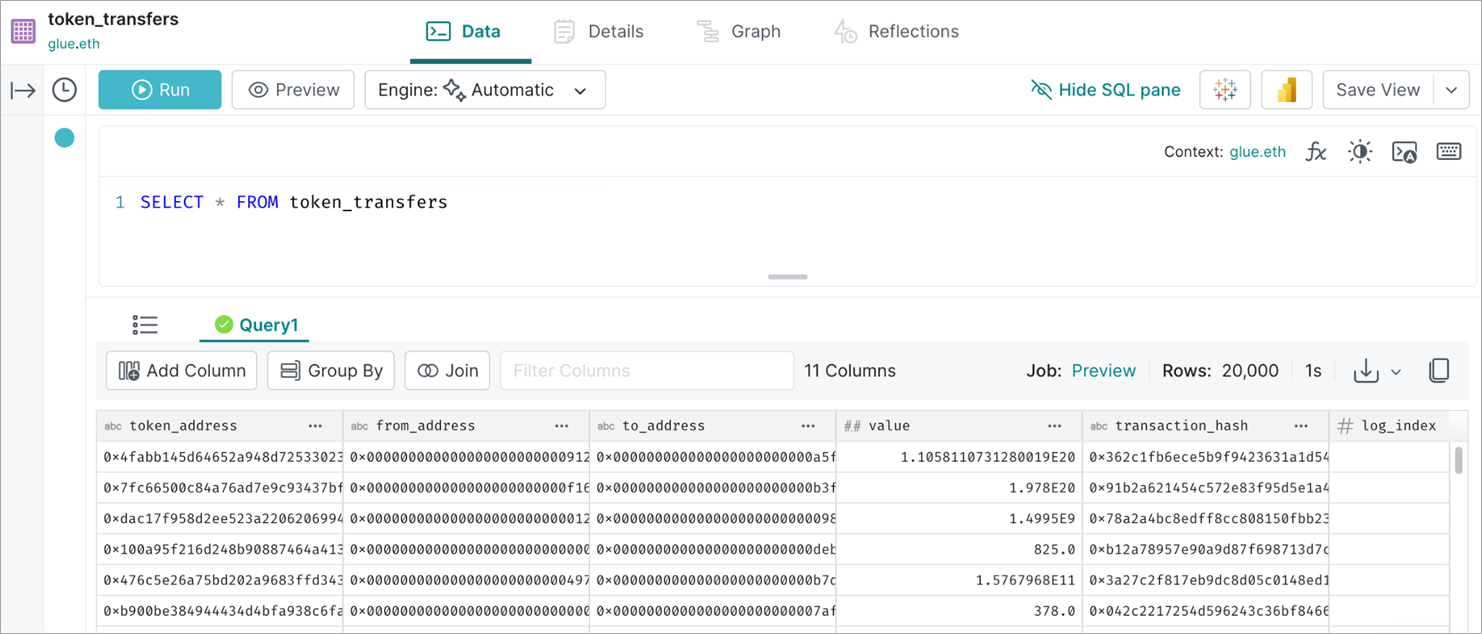
Figure 6 – Read the Ethereum transfers table created by EMR Serverless from Dremio.
New Engines and Tools
With more and more organizations looking to implement data mesh principles of domain ownership, broad interoperability at the data level has become essential for both data producers and consumers in large organizations.
This capability is important for the following reasons:
- Different tools may work better for different business units. Hence, all of these tools should be compatible with the datasets and tables.
- Existing business units may want to change or upgrade their tools due to changes in their needs.
- New business units bringing their own tools that need to be plugged in with the existing systems to start providing value from data as soon as possible.
- Need to prevent vendor or tool lock-in or lock-out.
Apache Iceberg offers extensive support for data producers and consumers, with many tools supporting both reads and writes, such as Dremio, Amazon Athena, and Amazon EMR.
As of the time of writing, Apache Iceberg has the broadest write and read support of any of the three modern table formats. Since Iceberg is a fully open, Apache-governed project, there is no risk of vendor lock-in or lock-out.
Conclusion
In this post, we discussed the capabilities of Apache Iceberg that enable data teams to quickly, easily, and safely keep up with different types of changes in data and analytics portfolios. With Apache Iceberg, you will be well equipped to handle bursts of changes to large datasets and tables without downtimes.
For more information on how to get started using Apache Iceberg for your analytical workloads, refer to the Dremio and Amazon EMR Serverless documentations. You can also learn more about Dremio in AWS Marketplace.
Special thanks to Sri Raghavan, Principal Partner Development Manager – AWS; and Sathisan Vannadil, Sr. Partner Solutions Architect – AWS
.

.
Dremio – AWS Partner Spotlight
Dremio is an AWS Data and Analytics Competency Partner and data lake engine that delivers fast query speed and a self-service semantic layer operating directly against Amazon S3 data. Dremio combines an Apache Arrow-based query engine with acceleration technologies to provide 10-100x faster query performance.
Contact Dremio | Partner Overview | AWS Marketplace | Case Studies