AWS Partner Network (APN) Blog
Accelerating Healthcare Data Management for Digital Transformation with Emids CoreLAKE
By Muz Syed, Sr. Partner Solutions Architect – AWS
By Gandhi Raketla, Sr. Partner Solutions Architect – AWS
By Kaustubh Kane, Director of Platforms – Emids
 |
| Emids |
 |
The healthcare industry is going through a transformative shift towards creating a digitally connected ecosystem. Healthcare organizations are looking to implement an approach for re-engineering existing architectures to iteratively adopt new technologies, and establish seamless integrations with existing systems internally as well as with their partner and client ecosystems.
In this post, we will describe how CoreLAKE, a managed service offering from Emids Technologies, can help organizations address their healthcare data needs.
Emids CoreLAKE is a low-code data management platform built by practitioners with years of experience in healthcare. It’s a suite of accelerators with pre-built capabilities having specific focus on accelerating the data modernization agenda.
CoreLAKE comes with two managed services offerings:
- Interface as a Service: This offering comes with configurable connection templates, parsers, and converters for FHIR, HL7, and EDI, as well as interoperability playbooks and knowledgeable clinical professionals that allow healthcare organizations to configure complex interfaces at scale. For this service, Emids runs the data extraction, cleansing, transformation, and standardization, guaranteeing there will be high-quality data flowing into the receiving layer.
- Data Management as a Service: Provides a unified data model complete with master data management, data cataloguing, lineage, and outbound connectors to enable advanced analytics.
Emids is an AWS Select Tier Services Partner that helps clients envision, build, and run more innovative and efficient solutions for their business problems with its industry-based, consultative approach.
Industry Challenges
Some of the leading trends emerging in the healthcare data field include:
- HealthTech companies are looking for accelerated data onboarding for their new enterprise customers.
- Large-scale data migrations from legacy systems to new systems as healthcare companies go through mergers, acquisitions, and digital transformations.
- Surge of new digital technology solutions need integration with existing healthcare workflows.
- Establishing enterprise-grade data strategies to create a unified data model to enable data products creation and business analytics.
- Adopting interoperability and having a strategy to establish seamless data interchange across payers, providers, and patients.
Healthcare organizations are overwhelmed with a multitude of different applications, ever-increasing volumes of data, and a variety of different systems to integrate the data from. Developing scalable and reliable data integrations needs an agile approach with a focus on delivering quick wins that can expedite customers’ go-to-market strategies.
Selecting the right partner to help you navigate this journey is essential.
Emids CoreLAKE Use Cases
Some of the key use cases addressed by CoreLAKE are:
- Interoperability between disparate data streams: Establish bi-directional data exchange pipelines between different source and target systems with the ability to interoperate data across different formats, such as HL7, EDI, FHIR, XML, JSON, and Delimited.
- Data migration from legacy to new systems: Large-scale data movement from a source format to different target formats with business rules and quality checks.
- Manage multi-tenant data pipelines on same platform: Ability to separate data pipelines by line of business, use case, and customer with interoperability maintained. Easy cloning from existing pipeline to rapidly set up new pipelines.
- Reusable multi-modal data ingestion from variety of sources: Avoid re-inventing connectors to data sources, get data, and run factory data quality rules and common healthcare-specific transformations.
- Managing and automating data governance: Execute an “ingest once, use multiple times” philosophy. Define access rules and data rights management to control which group gets to see what data groups.
- Low-cost maintenance of data pipelines in production: Leverage user interface-driven data pipeline creation, and reduce complexity of maintenance using pre-built reports for troubleshooting and fixing issues in production data pipelines.
CoreLAKE Architecture
The CoreLAKE architecture is built leveraging native AWS services and is a low-code framework with healthcare-specific, pre-built data management capabilities. This includes data ingestion, data quality, data standardization, data mapping, master data management, healthcare-specific data models, and a variety of data distribution mechanisms.
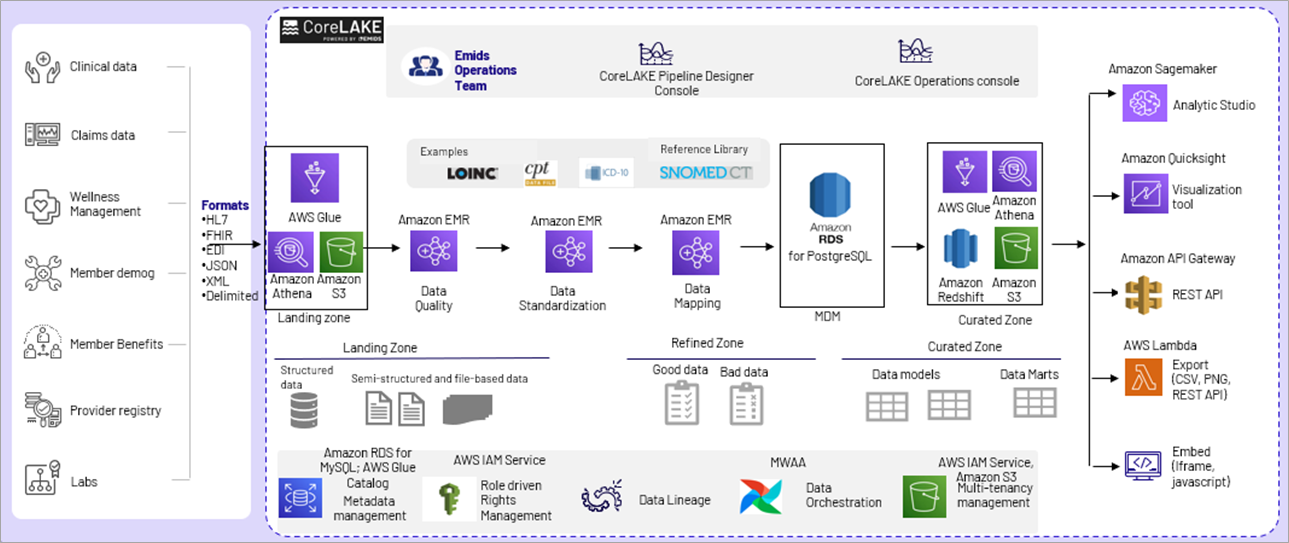
Figure 1 – CoreLAKE architecture on AWS.
Details below illustrate key features and capabilities of CoreLAKE’s multi-tenant metadata-driven architecture
Data Ingestion
Data ingestion integrates data from different types of systems, such as Secure File Transfer Protocol (SFTP), cloud, databases, Hadoop, Cache DBs, and APIs. CoreLAKE supports initial load, incremental load, full load, and reprocessing-based data ingestion scenarios to cover different use cases.
Data Quality
CoreLAKE provides out-of-the-box data quality capabilities to validate data and detect anomalies. It supports different pre-built rule types, including validations for lookup, date, format, range, zip code, phone number, as well as mandatory data checks and more.
Data Enrichment
Healthcare data typically has different types of incoming codes, such as diagnosis, observation, procedure, lab, gender, and race. CoreLAKE helps to enrich the source data with additional information required for downstream data needs, and performs data enrichment by using lookup and crosswalk tables.
Data Curation
Data curation involves parsing, transforming, and linking data across multiple sources to create a single version of truth. CoreLAKE has pre-built parser modules to parse different data formats, including HL7, EDI, XML, JSON, and Delimited. The platform’s data transformation and data linking modules have a library of transformation functions that are used to create expressions to map and link the data to target data formats.
Data Pipelines
CoreLAKE supports real-time streaming as well as batch-based data pipelines.
- Real-time streaming is an in-memory framework that processes data in micro-batches to perform transformation, validation, and standardization. It integrates data to the target layer or downstream with real-time workflows and analytics.
- Batch data processing is the ability to integrate and process datasets using scheduled or on-demand jobs execution. Batch datasets are configured to process known and finite volumes of data in every execution.
Data Repositories
CoreLAKE establishes target data repositories in the form of an enterprise data warehouse. The platform has pre-built healthcare data models to expedite customer implementations including clinical, claims, and disease registry.
Data Distribution
CoreLAKE supports data distribution in the form of data extracts and API integration. Data extracts create extract files by exporting the required data from CoreLAKE data repositories. Meanwhile, API-based integration is done by integrating with downstream systems using the APIs it exposes.
Conclusion
Healthcare is embracing the vast possibilities of digital transformation, but many organizations are finding out that a true shift towards digital will fundamentally require a modernization of the data landscape.
Having been an integral part of numerous large-scale data modernization programs and gaining invaluable experience, Emids made a strategic decision to invest in CoreLAKE. With the help of its factory-pattern accelerators, CoreLAKE aims to expedite healthcare data modernization programs, effectively reducing time-to-value for our clients.
.

.
Emids – AWS Partner Spotlight
Emids Technologies is an AWS Partner that helps clients envision, build, and run more innovative and efficient solutions for their business problems with its industry-based, consultative approach.