AWS Partner Network (APN) Blog
Best Practices for Structuring Data Lake Analytics with Starburst Galaxy on AWS
By Monica Miller, Developer Advocate – Starburst
By Antony Prasad Thevaraj, Sr. Partner Solutions Architect, Data & Analytics – AWS
 |
| Starburst |
 |
As one of an organization’s most precious resources, data has become the backbone of decision making—a shift that is representative through the surge of data-driven organizations.
With the rise of cloud storage, gone are the days where organizations must prioritize various data streams due to storage scarcity constraints. Now, every relevant data point can be investigated to capture business insight that was previously inconceivable.
The modern data lake has solved a number of challenges associated with the traditional data warehouse, such as the ability to store unstructured, semi-structured, and structured data in one cost-efficient location.
The current data climate underscores the importance a data lake can have as a scalable storage repository, in addition to all of the benefits that can be gained from achieving insights from analytics on a data lake.
Some organizations are already capitalizing on these benefits and are constantly ingesting unstructured, semi-structured, and structured data to one centralized location. However, many are hesitant to fully adopt a centralized data lake model because of performance detriment and lack of transaction support, both of which are found within a data warehouse.
In this post, we will discuss the best practices for structuring your data lake analytics with Starburst Galaxy and Amazon Web Services (AWS). Starburst is an AWS Data and Analytics Competency Partner that provides enterprise-ready features including performance, connectivity, management, and security.
Operationalizing the Data Lake
Utilizing the power of Starburst Galaxy, your AWS data lake can be operationalized and managed for the purpose of data analytics. Starburst Galaxy is a cloud-native service which provides fast access and flexible management of data, without adding the complexity of data movement.
Implementing a data lakehouse architecture with Starburst Galaxy on AWS capitalizes on the low-cost object storage of Amazon Simple Storage Service (Amazon S3) and the ability to load all types of data, while implementing the data warehousing principles of performance, reliability, and ease of use.
A data lakehouse allows you to optimize your data architecture to meet specific organizational needs through the balance of cost-based optimizations and scalability, while also implementing a reporting structure to operationalize your analytics.
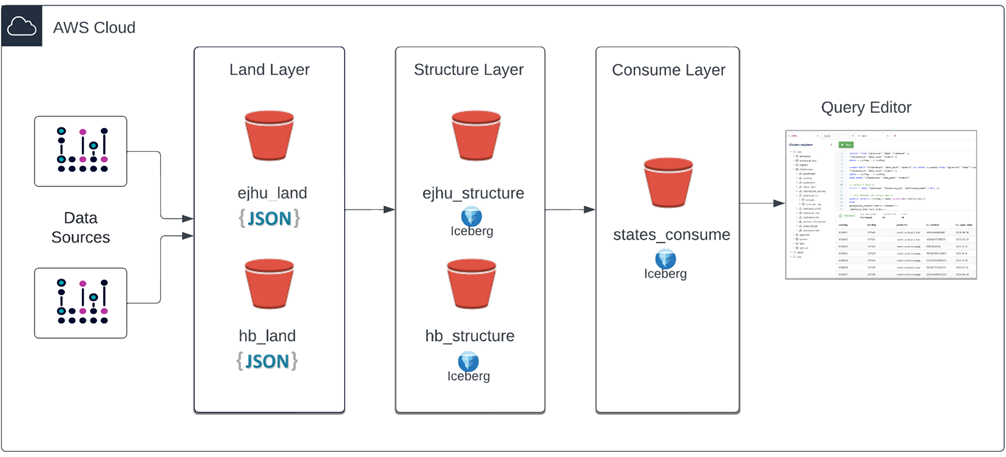
Figure 1 – Example of a Starburst data lakehouse on AWS.
Benefits of a Starburst Data Lakehouse on AWS
There are three benefits organizations will see when implementing the Starburst Data Lakehouse on AWS: optionality, flexibility, and performance/scalability.
Optionality
Your chosen data lake analytics platform should be agile enough to adapt to changing environments and infrastructures. Ideally, a data lake analytics engine should allow you to maintain architectural freedom, and you should be able to query your data where it lives.
Connecting to many popular data sources such as Snowflake, MongoDB, Elasticsearch, and Amazon S3, Starburst Galaxy lets you choose the storage solution that makes sense for your organization. Not only does Starburst currently support access to your sources and formats, but you can be sure there will be support for future innovations as well.
Flexibility
In reality, critical enterprise datasets are often distributed across two or more systems, ranging from traditional legacy warehouses to modern cloud data lakes. Optimizing or operationalizing your data lake requires an analytics platform matched to the realities of modern data architectures that can provide a holistic view of all the data in the ecosystem.
An effective data lake analytics engine must be able to connect to and query multiple modern and legacy enterprise sources. Starburst’s extensive ecosystem of connectivity allows data lake users to only pay for what they use and minimize data duplication.
Starburst Galaxy also lets you run both interactive and long-running queries, while utilizing ANSI SQL for any data transformations.
Performance and Scalability
A data lake query engine should be built for speed and performance at scale while allowing enterprises to control query response times and costs. Ultimately, the engine should improve analyst productivity by enabling faster queries on larger and more comprehensive datasets.
With connections to multiple on-premises and cloud-based storage locations and a highly-performant query engine built at scale, Starburst Galaxy is optimized to power your data lakehouse.
Galaxy is built on Trino, which is designed to query data at a petabyte scale and high concurrency and has multiple cost-based optimizations built in to improve time to insight.
Capitalizing on the separation of storage and compute, Galaxy customers have the ability to tune performance efficiency through the ability to scale compute up or down depending on demand or cost.
Best Practices
Operationalizing your data lake with Starburst Galaxy focuses on three main topics:
- Implementing a reporting structure
- Incorporating open table formats
- Applying native security
Each of these puzzle pieces helps to build the Starburst Data Lakehouse on AWS and contributes to improved performance, reliability, and scalability.
Implementing a Reporting Structure
The flexibility of object storage locations, such as Amazon S3, allows for the implementation of user-defined reporting structures which mimic the common data structure practices previously built in data warehouses, but without the high price tag.
Starburst recommends creating three distinct layers within your reporting structure in order to optimally operationalize your data lake on AWS: land, structure, and consume. Each layer serves a unique purpose, and the data in each layer can be categorized by specific data processing types.
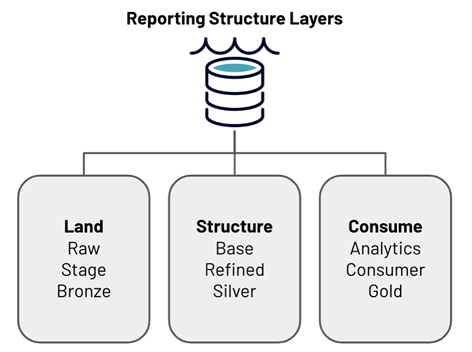
Figure 2 – Reporting structure layers in a data lakehouse.
The land layer holds raw data and stores any unmodified data from any source of any type of granularity. The structure layer is used for joining, enriching, and cleansing data. The consume layer contains aggregated data that’s ready to be queried.
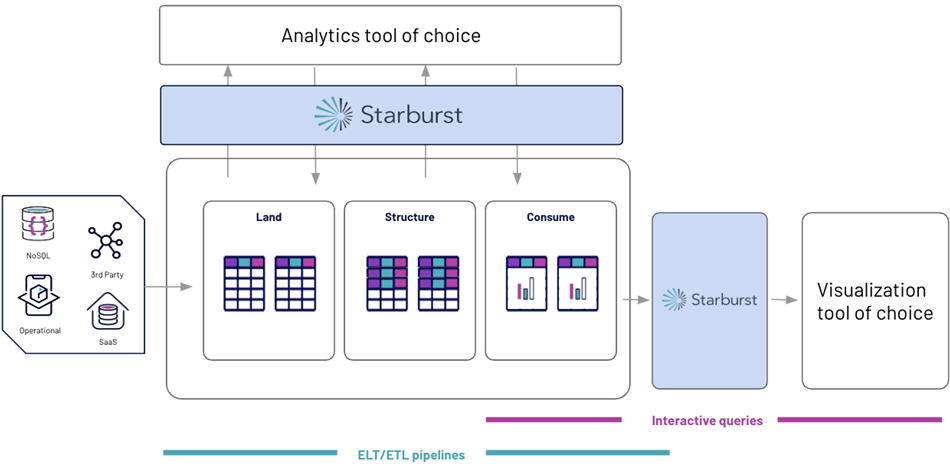
Figure 3 – Data lakehouse architecture with Amazon S3 and Starburst Galaxy.
Take this reporting structure, and the other components of the Starburst Data Lakehouse, and implement these strategies on your data lake on AWS.
Start by gathering data from external sources and landing that raw data in the land layer. If you have already adopted the data lake architecture, it’s likely this step already occurs.
Next, select your open table format of choice. Then, create your data pipeline using your format of choice and ANSI SQL to clean your data and create the structure layer.
Starburst has multiple connections to other tools such as Great Expectations, dbt, Airflow, and Dagster to assist as you develop comprehensive data pipelines. You can then create your consume layer, which are finalized reporting tables created from the structure layer.
Data analysts, business intelligence (BI) developers, and others requesting analytics insights are often granted read-only access to these finalized consume tables. These users often connect to their BI tool of choice and run interactive queries to create dashboards or reports.
Incorporating Open Table Formats
The Starburst Data Lakehouse has enabled Starburst Galaxy’s Great Lakes Connector to connect to multiple different open table formats such as Hive, Delta Lake, and Apache Iceberg.
Designed to implement simple SQL commands on your big data, increase reliability, and optimize performance, these table formats provide data warehouse-like functionality on the data lake.
Eliminating the grievances previously associated with the data lake, open table formats add transactional functionality such as MERGE, UPDATE, DELETE, and more. Additionally, incorporating your open table format provides increased performance benefits over traditional formats such as ORCFile and Parquet.

Figure 4 – Starburst Galaxy’s Great Lakes Connectivity.
Starburst Galaxy’s Great Lakes connectivity makes working with different file and table formats seamless by providing unified connectivity. This handles all of these formats but allows querying from them using regular SQL.
All you have to do is pick your format of choice when configuring your object storage catalog and Starburst Galaxy manages the rest.
Applying Native Security
To prevent your data lake turning into a data swamp, your data lakehouse analytics engine must support centralized and fine-grained control over data access, the ability to adhere to regulatory compliance standards at a global scale, and the capacity to integrate seamlessly with existing security standards and policies.
Starburst Galaxy is designed with security in mind, supporting many authentication types for both data sources (AWS IAM, Azure service, principal, Okta) and client integrations (OAuth, JMT). It includes a powerful role-based access control (RBAC) system, enabling administrators to configure the proper privileges to the corresponding users.
Starburst Galaxy’s RBAC lets you customize access for multiple roles, invoking granularity specific to the table-level or object storage location. With end-to-end encryption, and more security enhancements in development, Starburst Galaxy provides the foundation for a secure and flexible lakehouse.
Conclusion
If you are interested in exploring data lake analytics with Starburst Galaxy on AWS, complete the tutorial which explores two different datasets from the AWS Public COVID-19 Data Lake.
The first dataset revolves around the Daily Global and US COVID-19 Cases provided by Enigma. The second dataset shares information on US Hospital Beds, provided by Rearc.
The data lake analytics tutorial guides you through interactive analytics on the data lake in order to then identify which insights should reside in your data pipeline.
.

.
Starburst – AWS Partner Spotlight
Starburst is an AWS Data and Analytics Competency Partner that provides enterprise-ready features including performance, connectivity, management, and security.