AWS Partner Network (APN) Blog
Cloud Migration: Measurement at the Moment Of Truth
By Lee Atchison, Sr. Director of Strategic Architecture, New Relic
This is a guest post from New Relic, an Advanced APN Technology Partner and AWS Migration Competency Partner,
When migrating applications to AWS, it doesn’t matter if you are rehosting, replatforming, or planning a full refactor—as you take each step, you should know what’s working. Above all, you need to know if the user experience of your migrated app is what you expect it to be—especially at that moment when the workload has moved and everyone is watching.
How can you tell that a migration has successfully completed? How can you be sure that you haven’t introduced a problem or a looming concern into your application? How do you determine that you don’t need to do any further tuning or adjusting to ensure that your app that was previously running fine on-premises is stable and performing well in the cloud?
Ultimately, you can’t declare a migration successful until you’ve proven it works as expected in the new environment.
Defining Your Acceptance And Performance Goals
A big part of determining whether a migration has been successful or acceptable is to consider the user expectations, costs, and tolerances for application performance when the migration is complete. For example, the acceptance criteria for determining when a migration focused on cost reduction is complete might look something like this:
- Response time to end users should be within 5% of pre-migration levels.
- Steady state (i.e., non-peak) server utilization should be within 20% of pre-migration levels.
- Steady state (i.e., non-peak) infrastructure costs should be reduced by at least 10% compared to pre-migration levels.
- Service error rates should be equal to, or lower than, pre-migration levels.
- Application availability levels and performance should meet or exceed pre-migration levels.
Your plan will differ, depending on your migration goals. For more critical applications, you may have more goals with tighter tolerances. For less critical applications, you may have fewer and more general goals. You may be migrating to serve spiky traffic loads more easily, to allow the creation of additional data centers, to reduce infrastructure management burdens, or even to gain access to higher-performing servers. Whatever your goals, your plan should:
- Specify and quantify the desired improvements you expect from the migration.
- Identify other critical application metrics that you want to make sure remain acceptable and do not deviate a significant amount during the migration.
- Indicate that error rates and error types may not change significantly after the migration, to make sure that potential new errors have not been introduced into your system.
Make sure all the acceptance criteria goals you have established for yourself are goals that you can measure and monitor independently from any infrastructure. This is where New Relic comes into play. New Relic has a set of real-time monitoring capabilities that can measure the customer experience, code execution, and infrastructure behaviors that all report into a common platform. For example, in situations where you are moving a workload from an under-provisioned infrastructure to AWS, an improvement in user experience can be measured and proven. (see Figure 1)
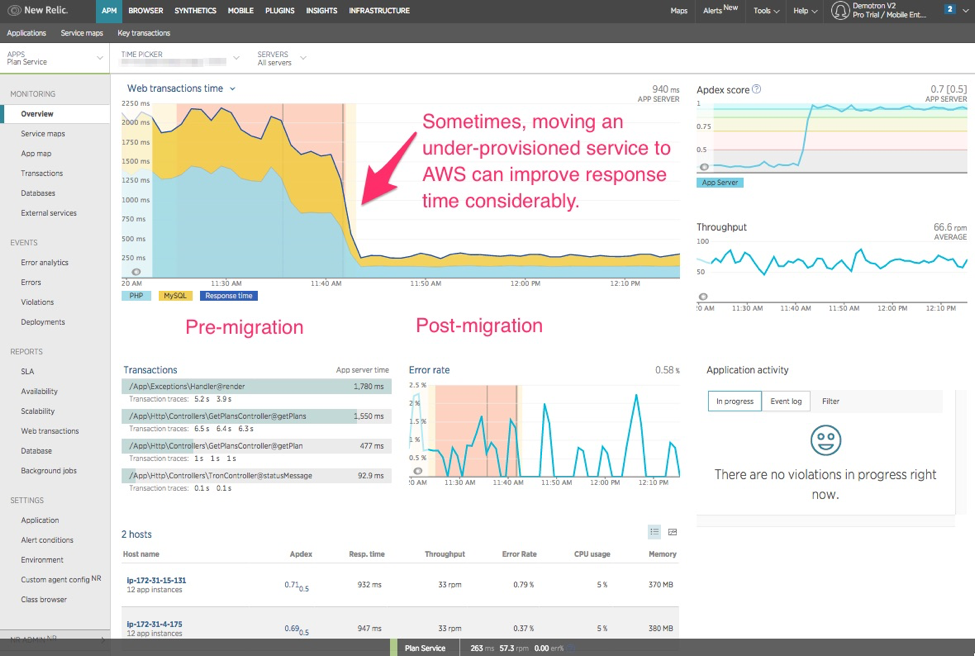
Figure 1 – When moving from an under-provisioned legacy infrastructure to AWS, New Relic application performance monitoring (APM) clearly shows a measurable improvement in user experience.
Baseline Your End-User Experience and Application Performance
Once you’ve established your goals, you must measure the baseline performance of your application. This is critical for two reasons:
- During the migration, deviations from the established baseline can be early indicators of bugs or problems created during the migration.
- After migration, you’ll need the pre-migration baseline and your established goals to judge the success of the migration and help determine when it can be considered complete.
What do you need to measure to create that baseline? The answer depends on your application and business needs, but typically covers applications and services, servers, and end-user experience – all measurable with New Relic:
- For end users: Time to glass performance, error rates, types of errors, browser-specific and mobile-specific performance, and latency from multiple geographic locations all need to be considered. Moving from a specific data center to a cloud-based infrastructure may impact individual users’ performance in different ways based on their locations. Tools such as New Relic Browser and New Relic Mobile can help measure changes to the end user experience during a migration. Additionally, setting up synthetic user monitors using New Relic Synthetics can capture data about specific types of user interactions with the back-end services being migrated.
- For each application/service: Response time, error rates, types of errors, latency, and call rates are all important to see how the services perform on their new infrastructure, and to detect code-level problems introduced by the new environment. New Relic’s Application Performance Monitoring (APM) is designed to help you measure this information so you can see how changes impact response times and errors in real time.
- For each server: CPU, memory, load average during various usage scenarios (different traffic loads), and how they perform relative to different traffic, help you see how load is impacted with new server types and configurations. For these measurements, New Relic Infrastructure provides capabilities for measuring the performance of the servers running your application. This step is particularly important to monitor how effectively the new servers are being used by the migrated application.
User experience is, by far, the most important aspect to preserve during a migration. Understanding how individual services work internally is important, particularly for identifying and resolving issues, but the end-user experience is the ultimate result you want to preserve. You will not be successful if your end-user’s experience is noticeably worse after the migration. Tools like New Relic Synthetics are especially valuable in determining if, and by how much, the end-user experience has changed.
You may want to use New Relic Insights to create a migration-specific dashboard that shows the specific metrics you are monitoring for your acceptance criteria. All the New Relic products mentioned above can feed data into dashboards created in New Relic Insights, which can present a single-page view of how your migration is advancing. But remember that such a dashboard is designed to present a high-level overview of your application performance. Don’t forget to drill down to the more detailed performance information within the individual products to determine how your application is performing during the migration.
You may need to establish multiple baselines based on your application’s usage patterns. If it experiences usage peaks and valleys, you’ll want to establish baselines at multiple points and correlate to the specified usage patterns.
This may seem like an excessive amount of performance information to collect, but changing the performance of a given service or system can impact the performance of the entire application and uncover hidden defects and faults that appear only under different conditions. You aren’t just changing the application’s performance, you may also be shaking loose existing bugs and shortcomings in your applications. That means you need to understand how the change impacts the performance of all the components in your system and all your users, as well as monitor for newly surfaced bugs and defects.
For packaged applications that you do not directly control, you may not be able to get all the application/service-level performance and error information described above. For these applications, focus on end-user performance and server-level performance. Use tools such as New Relic Synthetics and New Relic Infrastructure to give you good guidance on the most critical aspects of how these pre-packaged applications perform in the cloud.
During the Migration
Once your baselines are established, you can begin the migration, applying the exact same monitoring tools to allow for apples-to-apples performance comparisons. Begin to add in cloud-specific monitoring capabilities (such as Amazon CloudWatch) as incremental improvements to your migration story and to assist in problem diagnosis.
As the migration progresses, use your New Relic dashboards to keep an eye out for spikes in any of your critical performance metrics. Look for jumps where performance suddenly becomes, say, 20% worse than before. If you see any of these performance changes, immediately examine and determine the cause before moving to the next phase of the migration. Spikes and jumps are good indications of migration-related bugs or problems. Pay particular attention to error rates and response time values, as these are often the first indications of a problem.
If you have not already done so, I recommend you assign individual services and capabilities—and the monitoring associated with those services and capabilities—to individual teams. It then becomes that team’s responsibility to make sure their specific services are properly functioning during the migration, and to resolve issues that occur. This may or may not be part of a formalized DevOps process, but certainly performing a cloud migration provides a perfect opportunity to begin instilling DevOps practices into your organization.
During the migration, it’s important to prioritize migration-related issues at a higher level than new business requests. If you let a migration-related issue persist, you may lose visibility into the root cause of the issue. The issue could fester and cause more serious problems later. It is best to resolve the issues when eyes are on the problem and appropriate resolutions can be implemented.
The discipline required to prioritize migration-related activities can be challenging, but it is essential to make sure the migration completes successfully.
Don’t be afraid to undo a migration. If performance becomes unacceptable, don’t be afraid to back out the migration of a given service or module and reevaluate what’s needed before continuing. Implementing your migration using incremental steps helps limit the “blast zone” so it can be easily rolled back. This may not always be possible, but being able to quickly roll back changes should be a goal at every step.
Post-Migration
After you’ve moved your last service to the cloud, you’ll want to validate whether you’ve met your expectations and completed the migration. To do so, repeat the pre-migration baselining measurement process, examining your application using the same usage pattern times as you did before the migration.
Finally, compare the new baselines to the pre-migration baselines. Some metrics will likely have improved while others may have degraded. Compare the results to your plan to validate that the changes meet your expectations. If they don’t, you have a couple of options:
- Examine the deviations using your monitoring tools to determine the causes. If you’ve been doing this all along (as suggested above), you should already be aware of these issues.
- Determine if the deviation is acceptable to your business. You may decide that in the context of the overall improvements, a negative deviation in a specific metric is acceptable.
Your migration should be considered successful only after:
- All planned performance improvements have been validated in your new baselines.
- All (negative) performance deviations fall within planned acceptable levels.
- No unexpected migration-specific errors have been identified.
- Any remaining deviations from your plan can be explained and are deemed acceptable to your business.
Figure 2, below, shows an example dashboard with both pre- and post-migration data. Notice that some performance measurements have changed—some for the better and some for the worse. But if all your acceptance criteria goals have been met, or if you understand the deviations and can safely and knowingly live with them, you can safely consider the migration a success.

Figure 2: New Relic services all use a common analytics platform that can sort, filter, analyze, and alert on the all the raw data you decide to collect. This dashboard compares apps running on an on-premises data center vs AWS infrastructures. Availability data comes from New Relic Synthetics, Error Rate and Response Times pull from New Relic APM, and CPU Utilization from New Relic Infrastructure.
What Can Go Wrong?
Even a simple lift-and-shift of a seemingly unchanged application to a new environment can introduce concerns and performance deviations than can torpedo a cloud migration. These issues can greatly extend the migration process or even require a rollback to pre-migration systems.

Figure 3: Most services rely on connections to other services in some way. New Relic measures the individual transactions between every service.
Here are some things to watch for:
- Inter-service latency gets worse. (see Figure 3 above) Since you are moving services to a new environment, the expected latency between services is likely to change. Some values may improve, some may get worse. If a specific service-to-service latency gets significantly worse, it can trigger service availability problems and other errors.
- Inter-service volatility. Even if inter-service latency isn’t significantly degraded, an increase in volatility can play havoc on your services and impact availability and error rates. It can also complicate future problem diagnoses. (see Figure 3 above)
- Configuration changes. Even if you don’t plan to change your application, you’ll likely need to make some tweaks and adjustments to configuration values for the move to the cloud. These changes, even if you think they’re benign, can create hidden problems.
- Server performance. The servers running your applications in the cloud may be faster or slower than your pre-migration on-premise servers—or their performance could be more variable than before. These server performance changes can reveal previously hidden defects in your application.
Even if your applications are stable and functioning normally in your existing environment, moving them to a new environment can introduce unknowns and uncertainty to your system. Detecting and resolving issues stemming from that uncertainty early in the migration process will make the migration smoother and more likely to be successful.
Moving Beyond The Migration
After the workloads have moved and deemed stable and performant, the expectations of how the cloud can help evolve your apps will rise. Similar to understanding the changes that occur during a migration, understanding the impact of the changes that occur is also critical to making the daily data-driven decisions on adopting new cloud services, code changes, and optimizing infrastructure. New Relic’s tools are designed to help you monitor your apps and infrastructure as you refactor and re-architect your apps on AWS.
Next Steps
In this blog, we’ve discussed the needs, measurement techniques, and risks that need to be mitigated during a migration to AWS. For more details on the migration and acceptance testing, download this cloud migration measurement guide: Measure Twice, Cut Once, or to get started, head over to newrelic.com/aws to sign up for an account and get started today.