AWS Partner Network (APN) Blog
How Gremlin’s Chaos Engineering Platform Validates AWS Operational Excellence and Reliability
By Eugene Wu, Partner Solutions Architect at Gremlin
 |
 |
Chaos engineering is the discipline of experimenting on a software system or service to build confidence in its capability to withstand turbulent and unexpected conditions. Its goal is to reveal weaknesses before they break.
Because chaos engineering applies to more than just technology, the system it operates on includes team members who deploy code or operate infrastructure.
Gremlin’s chaos engineering platform takes this one step further by validating your service’s compliance with two pillars of the Amazon Web Services (AWS) Well-Architected Framework: operational excellence and reliability.
If you have a cloud service that is preparing for, or has performed, an AWS Well Architected Review (WAR), Gremlin’s suite of infrastructure and application failure injection methods can help in several ways.
First, it validates the resilience of your services in their current state. Second, it aids in fixing and optimizing changes you put in place after implementing recommendations from the review.
This validation applies whether you have performed the review with AWS Solutions Architects or the AWS Well-Architected Tool. In addition, practicing chaos engineering helps your teams reliably maintain and operate their infrastructure and services by revealing operational gaps and preventing regressions.
Gremlin, Inc. is an AWS Partner Network (APN) Advanced Technology Partner with a cloud service that lets you run chaos experiments on your AWS systems.
In this post, I’ll walk through the process Gremlin follows to validate both the operational excellence and reliability of your AWS Cloud services in accordance with Well-Architected Review.
Pillars of the AWS Well-Architected Framework
The AWS Well-Architected Framework helps cloud architects build secure, high-performing, resilient, and efficient infrastructure for their applications. It provides a consistent approach for customers and APN Partners to evaluate architectures and implement designs that will scale over time.
The Well-Architected Framework includes strategies to help you compare your workload against AWS best practices, and obtain guidance to produce stable and efficient systems. The framework is built on five pillars:
- Operational excellence
- Security
- Reliability
- Performance efficiency
- Cost optimization
Learn more about the five pillars of AWS Well-Architected >>
Gremlin’s chaos engineering platform is optimized for two pillars of AWS Well-Architected: operational excellence and reliability. Let’s take a look at each pillar and how chaos engineering fits in.
Operational Excellence
The operation excellence pillar focuses on your ability to prepare, operate, and evolve your workloads. To prepare means to evaluate an application and whether it—and the team maintaining it—has the means to efficiently operate the application, especially when it encounters problems.
In short, achieving operational excellence encourages you to:
- Refine operations procedures frequently.
- Anticipate failure.
- Learn from all operational failures.
Reliability
The reliability pillar focuses on your ability to recover from a disruption. More specifically, in regards to technology reliability, the pillar encourages you to:
- Test recovery procedures.
- Automatically recover from failure.
- Scale horizontally to increase aggregate system availability.
- Stop guessing capacity.
- Manage change in automation.
Chaos Engineering
Chaos engineering performs thoughtful, planned experiments designed to reveal weaknesses in systems. It enables us to test proactively, instead of waiting for an outage. When practiced regularly, chaos engineering finds weaknesses in a system earlier in the build process.
Additionally, running through the routine of disaster recovery with simulated real-world scenarios helps tune monitoring and alerting systems, and prepare teams for inevitable failures. The result is reduced downtime, fast time to resolution, and raised engineering velocity and reliability.
Gremlin and Chaos Engineering
At Gremlin, we empower organizations to adopt chaos engineering and run reliability tests against all of their systems, services, and applications. We feature a full suite of infrastructure and application failure modes so organizations can test and validate reliability across their entire stack.
Gremlin has helped a wide range of customers build resilience into their systems, ranging from startups to Fortune 100 companies in industries such as retail, finance, high tech, and media and entertainment.
We understand that, as systems have become more complex, demands on service providers are increasing. Therefore, it’s important to regularly test for failures proactively rather than hoping that nothing happens.
When conducting a Well-Architected Review, engineering groups are likely to ignore the results if nothing appears glaring. A WAR all by itself may not be convincing enough to drive meaningful action before a fault occurs. This is where Gremlin comes in—by simulating the failures that can cause these incidents.
How Gremlin Validates for AWS Operational Excellence
It’s always a good practice to use a Well-Architected Review to validate the configurations of the applications you have running on AWS. For example, within the operational excellence pillar, you’ll find questions related to your application’s readiness, as shown in Figure 1.
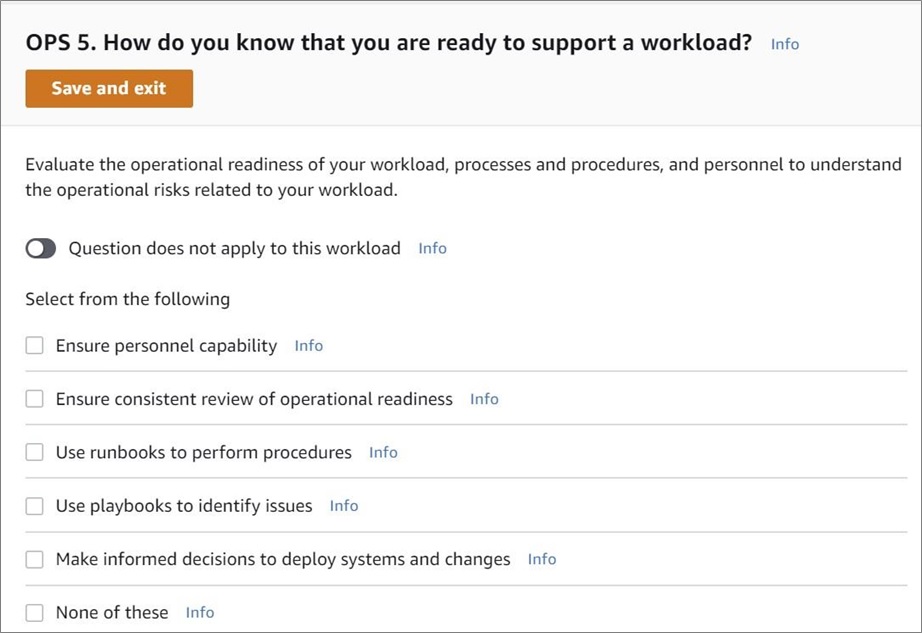
Figure 1 – Well-Architected Review questions to determine your operational readiness.
When you adopt chaos engineering, your teams can individually validate their application’s reliability by, for instance, using a playbook to respond to an issue.
Gremlin validates the actions in your playbook by orchestrating the failure in a precise, controlled way. For example, you might have a playbook that details recovery mechanisms when you need to perform a region failover.

Figure 2 – Example of a playbook with recovery mechanisms.
In the Gremlin platform, you can use our Region Evacuation Scenario to simulate this scenario.
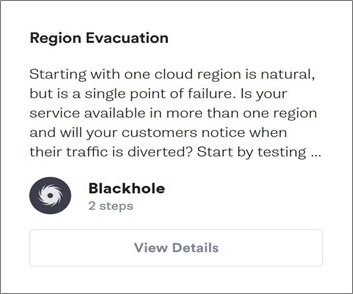
Figure 3 – Gremlin Region Evacuation Scenario.
Once you select this particular scenario, you can choose your targets, and then click Run Scenario to execute. The example in Figure 4 performs a region evacuation for all hosts deployed in the us-east-1 region.
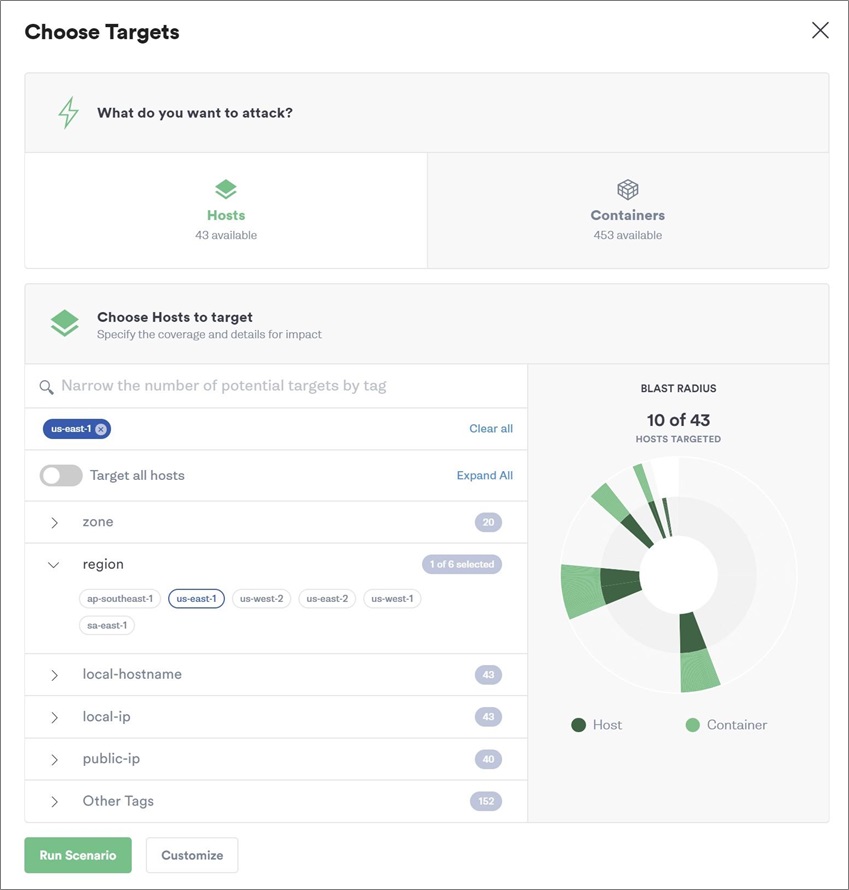
Figure 4 – Example of region evacuation.
Once this scenario is executing, operators and service owners should:
- Measure detection and alerting mechanisms, such as how long it takes to detect and alert this failure in the region where it’s happening.
- Execute playbook procedures to perform a region evacuation.
- Measure the success, and the time for this evacuation exercise to complete.
How Gremlin Validates for AWS Reliability
The reliability pillar of the AWS Well-Architected Framework has a requirement to continuously test the resilience of your workloads. For example, it asks you to evaluate your resiliency testing procedures, as shown in Figure 5.

Figure 5 – Example of AWS Well-Architected reliability questions.
Chaos engineering can generate and execute individual tests, run coordinated GameDays to proactively and regularly test the resilience of your workloads, or build in automated testing to ensure all continuously delivered builds are reliable.
Gremlin adds the capability to create custom scenarios. This is a sequence of attacks you can run against your system. It has a free-form format that lets you specify the exact scenario, describe it (perhaps it’s to replay a previous incident), and form a hypothesis.
You can run each custom scenario through a sequence of attacks with an expanding blast radius (number of hosts included in the attack) and magnitude (intensity of the attack). After each run, you can easily record your observations.
You can use Gremlin’s custom scenarios to recreate a past outage, or to automate a sequence of attacks to iteratively grow the blast radius of a chaos engineering experiment. A Gremlin custom scenario has no pre-built constructs that limit which failure you can inject, so you have much more freedom to configure attacks and attack stages. You also have the responsibility to ensure they expose the right weaknesses.
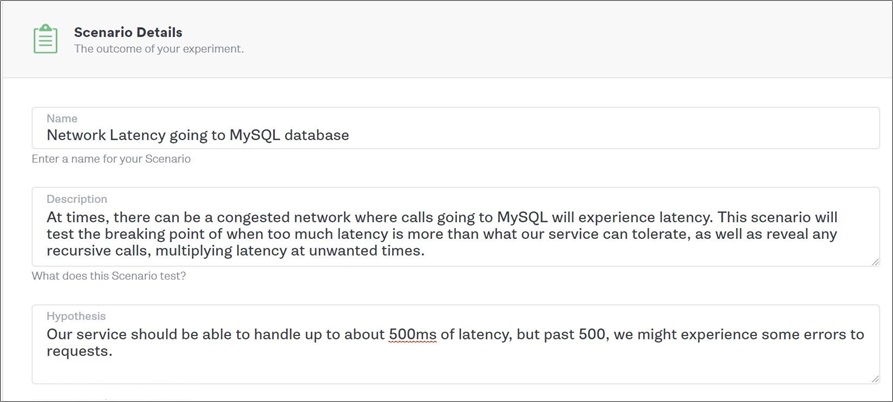
Figure 6 – Gremlin scenario details.
Working with the hypothesis shown in Figure 6, you would then select all of the hosts running the service you intended to attack.

Figure 7 – Choosing the hosts to target.
Finally, you would select Latency gremlin, set the length to run for five minutes per attack, and target egress port 3306 to affect all traffic going to MySQL.

Figure 8 – Specifying the parameters of the attack.
Now, within scenarios, you can stack additional latency attacks so you can find out exactly where the threshold of failure is. To do that, add attacks similar to the previous ones, varying only the latency.
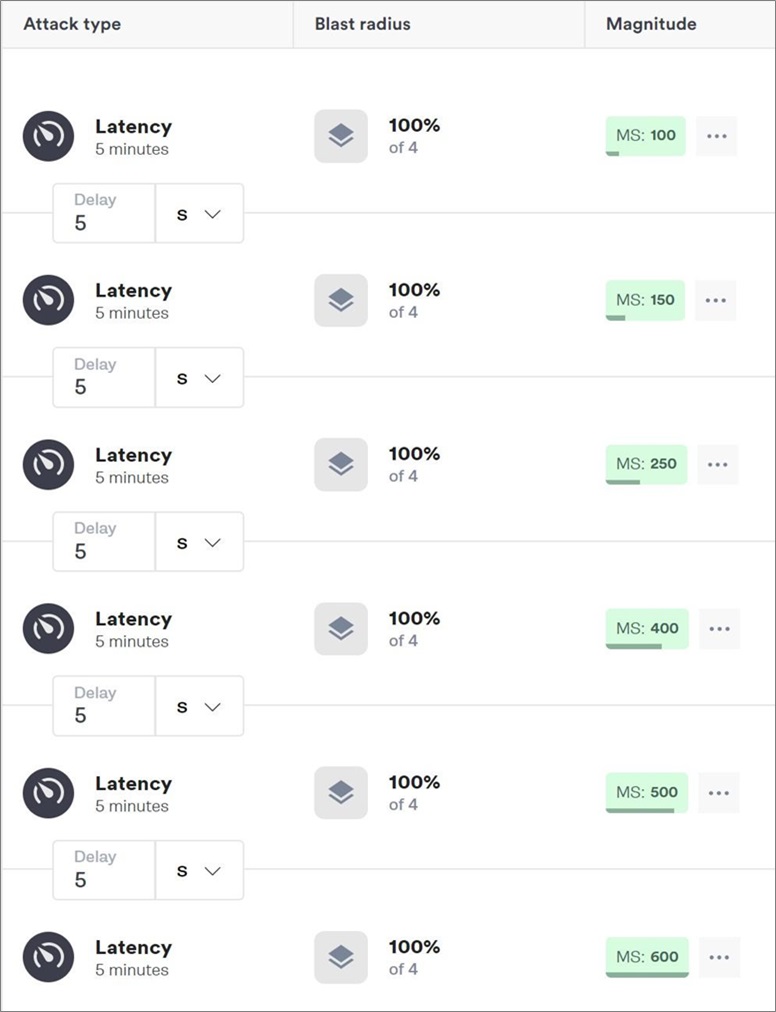
Figure 9 – Adding additional attacks with different latencies.
What we described is just one scenario that can be run in the form of a GameDay. In a GameDay, teams gather to observe what happens to their service when these tests are conducted, and to share their perspectives and observations.
Once a test finishes, teams identify other types of dependencies and run similar tests, such as the request paths to get images, item description, and customer reviews (if you own and operate an e-commerce site).
Automating for Reliability
Environments and applications change frequently, and they can have several deployments a day. So it’s important to continuously validate your findings to maintain the resilience of your system.
To help with this, Gremlin offers two methods of automation:
- Gremlin Scheduler to automate attacks so they run on regular schedules.
- An API for integration into your Continuous Integration/Continuous Deployment (CI/CD) pipeline.
Before using either one, we recommend you first conduct a few tests manually to verify your systems are reliable. Once the individual tests reveal no weaknesses, automate them so they are always running without manual intervention.
Using Gremlin’s scheduler, you can set a regular time and number of executions to run for any test you select.
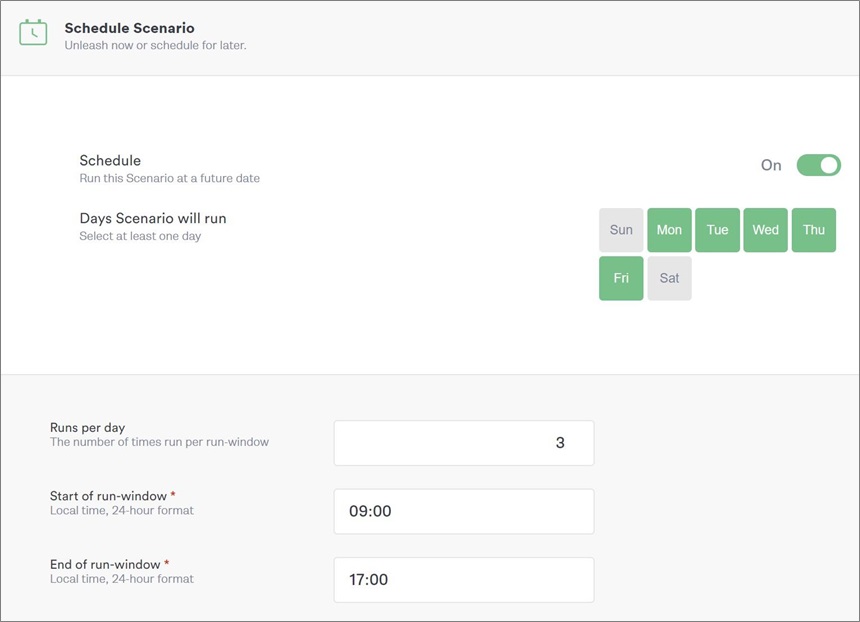
Figure 10 – Using Gremlin Scheduler to automate attacks.
The preceding screenshot shows a scenario that will be run Monday through Friday, three times a day between the hours of 9 a.m. and 5 p.m.
Alternatively, you can use our API to execute a test in your CI/CD pipeline, so that every build will go through a suite of reliability tests before being fully deployed.
Conclusion
The best way to ensure your cloud services meet AWS goals for operational excellence and reliability is to act on the AWS Well-Architected Review recommendations. Then, use Gremlin to validate the results. If you find any faults, remediate them before they create problems.
With Gremlin, engineering and operations teams can take control of the entropy of their systems, and proactively test for any failures across their entire stack, either manually or through automation.
The AWS Well-Architected Review and chaos engineering go hand-in-hand. With Gremlin, you can begin helping your customers validate every WAR, for every application, so they can rest easier at night.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.

.
Gremlin – APN Partner Spotlight
Gremlin is an APN Advanced Technology Partner. Its chaos engineering platform proactively inject faults to reveal bugs and issues before they happen.
Contact Gremlin | Solution Overview | AWS Marketplace
*Already worked with Gremlin? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.