AWS Partner Network (APN) Blog
How to Export a Model from Domino for Deployment in Amazon SageMaker
By Igor Marchenko, Sr. Sales Engineer at Domino Data Lab
 |
Data science is driving significant value for many organizations, including fueling new revenue streams, improving longstanding processes, and optimizing customer experience.
As organizations try to scale their data science capacity, they often become limited by inadequate or unreliable compute resources, difficulty collaborating on and reproducing past work, and production challenges that leave data scientists spending too much time on DevOps and other mechanics.
Domino Data Lab empowers code-first data science teams to overcome these challenges of building and deploying data science at scale. Domino Data Lab is an AWS Advanced Technology Partner with AWS Competencies in Machine Learning and Financial Services.
In this post, I will walk you through the steps to build and export a model from the Domino platform for deployment in Amazon SageMaker. The Amazon SageMaker export is available in Domino 4.2 and above.
About the Domino Data Platform
Domino’s open data science platform enables organizations to accelerate research by giving data scientists self-serve access to the latest tools and scalable compute.
As a system of record for data science, it automatically tracks all work to ensure reproducibility, collaboration, and governance best practices are followed, while giving data science leaders visibility into all projects that are in flight inside their organization.
Within Domino, you can leverage all of the tools you are most familiar with—such as Python, R, SAS, or MATLAB—to analyze and clean up data, train and publish predictive models, and monitor their performance over time.
You can deploy and host models in Domino on AWS infrastructure, which provides an easy, self-service method for API endpoint deployment.
Deploying models within Domino provides insight into the full model lineage down to the exact version of all software used to create the function that calls the model.

Figure 1 – Options for deploying and hosting models created in Domino.
The Domino platform also provides an overview of all production assets (APIs, applications, etc.) and links those assets to individuals, teams, and projects so usage can be tracked and assets can be easily reused within other projects.
While Domino itself supports model publishing, there are situations where you may want to:
- Provide massive scale for your model.
- Isolate your model deployment from your Domino research and development environment.
- Secure your model using your own methodology.
- Perform A/B and multivariate testing on your published models.
To support these situations, Domino can use a set of APIs to export a model in a format compatible with Amazon SageMaker.
What is a Model in Domino?
Domino model publishing involves three main components:
- Software environment (i.e. a base Docker image) that contains the necessary software and libraries to run your model.
- Your trained model, source code, and any associated files.
- Web service layer to provide HTTP/S access to your model.
The software environment (or Compute Environment as it’s called in Domino) is the base Docker layer. Domino then adds your associated files and configures a web service layer into a bundled Docker image on top of the software environment Docker layer.
This Docker image is deployed on the Domino infrastructure to provide HTTP/S access to your model.
How to Build a Model in Domino
When you build a model in Python or R, a common approach is to save the trained model in a file-based format such as a Pickle file in Python or RDS file in R. Then, you create a wrapper function to process inputs for your trained model.
This function will load and call your prediction function that is saved in the Pickle or RDS file.
Note that I have published sample notebooks on Github for easy access to the code samples in this post.
Let’s say you are responsible for building a customer churn model for a wireless phone network. You have a trained model using a GradientBoostingClassifier algorithm from the Python sklearn library.
This model needs four features:
dropperc– Percent of dropped calls.mins– Minutes used per month.consecmonths– Consecutive months as a customer.income– Customer’s yearly income.
Save the model in the file path results/gb1.pkl. You can write the following Python prediction function wrapper code to leverage this model (see the full script here).
You can then publish this model in Domino:
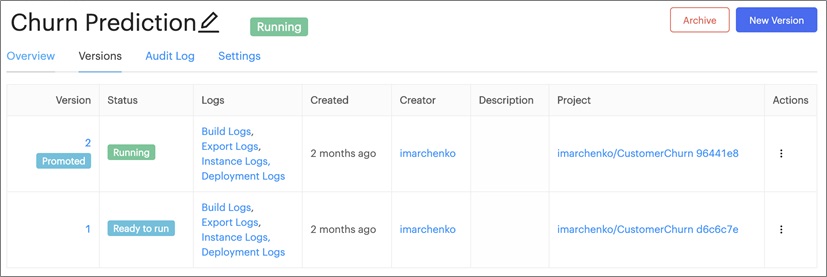
Figure 2 – Domino manages each model version so you can publish and replace it as needed.
Then, call the model with test parameters:

Figure 3 – Models can be tied into applications using token-secured APIs.
This published model can be tied into other business applications using the token-secured APIs. For more details on how to create and build a model in Domino, please see the appropriate Domino Get Started Guide for Python or R.
How to Publish a Model
This section describes how to publish a model to Amazon Elastic Container Registry (Amazon ECR) from Domino for deployment in Amazon SageMaker.
Once your model is available in Domino and you have buy-in from users who want to incorporate it into monthly reporting:
- You need to ensure customer information is only available as part of an automated pipeline, so you need to deploy this model on an isolated infrastructure.
- The model needs to scale up on-demand to handle processing hundreds of millions of customer records for reporting.
- You need to perform A/B testing on your model as it evolves.
Amazon SageMaker model endpoints are a great solution to these challenges.

Figure 4 – The process to export a model using Domino’s model export APIs.
The first step is to export your Domino model to Amazon ECR so it can be easily retrieved by the Amazon SageMaker endpoint services. The Docker image that Domino publishes to Amazon ECR is in a format compatible with Amazon SageMaker Model Endpoints.
For more details about this API call, please refer to the Domino documentation.
To begin, create an Amazon ECR repository and identity and access management (IAM) credentials to access this ECR repository. Set your AWS credentials as part of your Domino project.
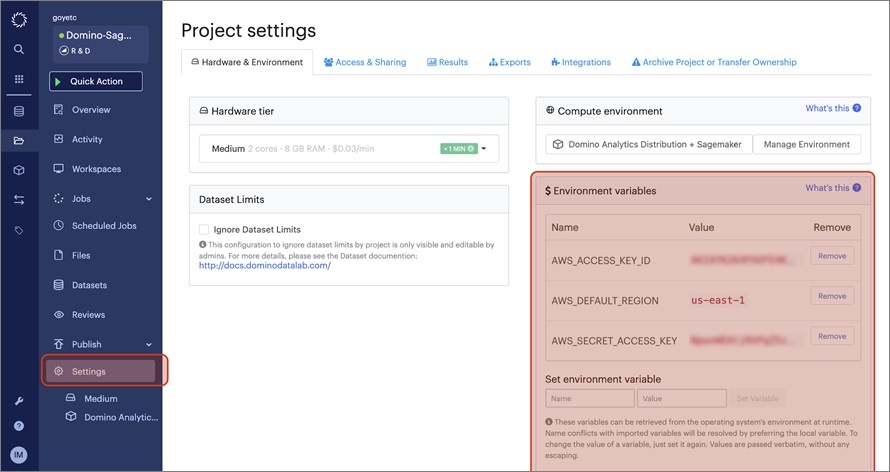
Figure 5 – Storing AWS credentials in Domino.
For more information, see:
Next, spin up a Jupyter or JupyterLab notebook in Domino to execute your API code (link to full notebook).

Figure 6 – Launching a workspace in Domino.
Now, you need to set up Domino API credentials. Since you’re running this Python code inside a Domino workspace, you can pull these credentials directly from the environment variables. If you run this code outside of Domino, you must manually populate these variables.
Next, set up some Amazon ECR variables. In these code samples, domino-sagemaker-exports is a sample Amazon ECR repository. Create your own ECR repository in your AWS account.
As a last step, select the model you want to export. Use this code to create a visualization of the models associated with your current Domino Project:

Figure 7 – Pandas table showing two versions of the model.
The Domino SageMaker Export API require you to use the Model ID and Model Version. In this case, select model ID 5ed7dadecdfc18044c36d381 and model version 2.
Finally, call the model export API with the above parameters:
Then, wait in a loop until the export is finished.
The status looks something like this:
If you do encounter any issues, you can always look at the logs with the following code.
Create the Amazon SageMaker Endpoint Using the AWS Console
Now that the model is in Amazon ECR, you can use it as an Amazon SageMaker endpoint. First, navigate to the ECR console to get your uniform resource identifier (URI) for the Docker image you exported from Domino.
Copy this URI to your clipboard.
In our example, the URI is XXXXXXXXXXX.dkr.ecr.us-east-1.amazonaws.com/domino-sagemaker-exports:domino-imarchenko-CustomerChurn-5ed7dadecdfc18044c36d381-2:
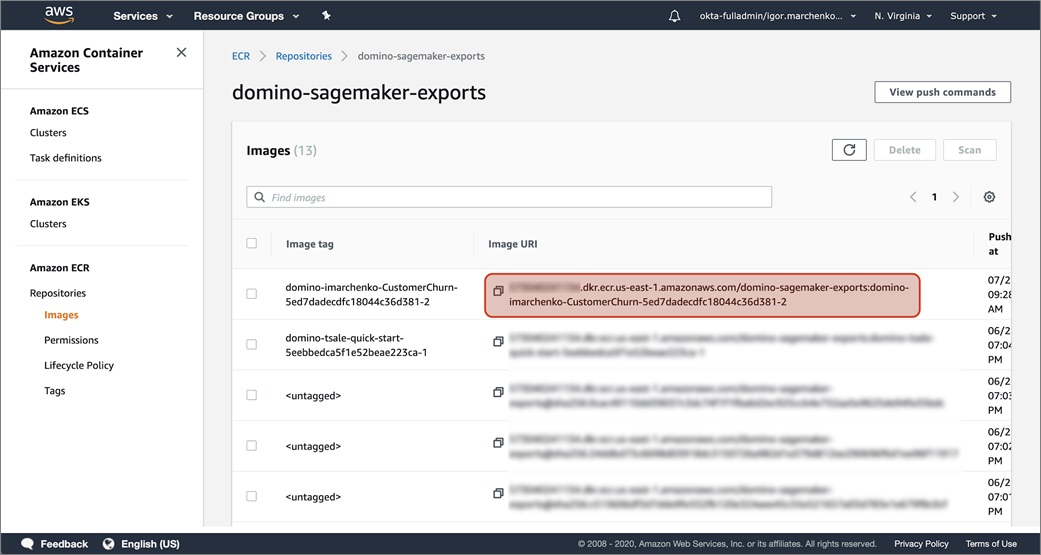
Figure 8 – Creating the Amazon SageMaker endpoint in the Amazon ECR console.
In your Amazon SageMaker console, navigate to SageMaker > Inference > Models, and then Create a new model.
Configure your new model as a Single Model and specify your Amazon ECR URI.
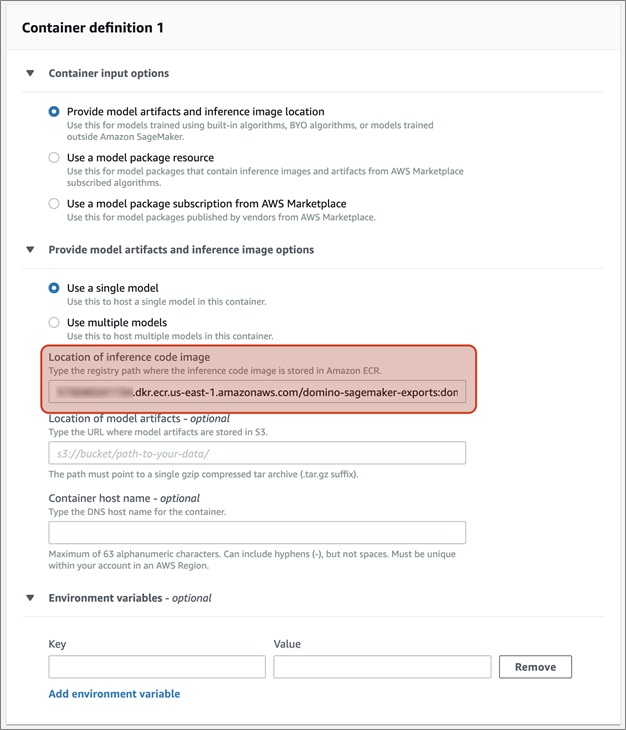
Figure 9 – Configuring a model and setting the location of the inference code.
Next, navigate to SageMaker > Inference > Endpoint Configuration. Create a new Endpoint configuration using the model you previously created.
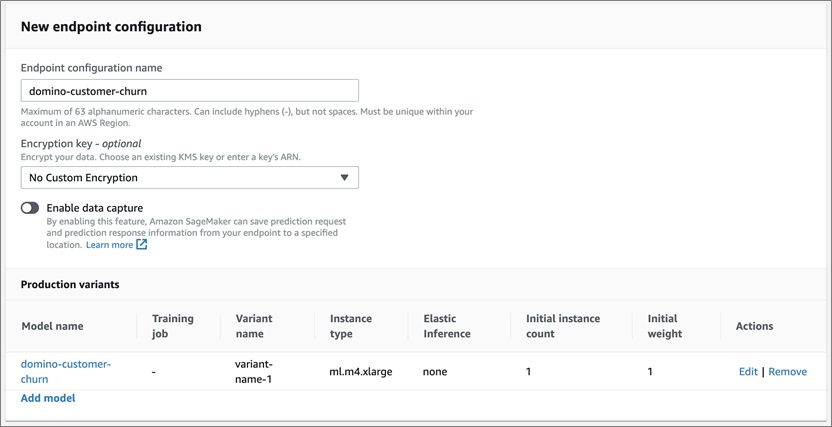
Figure 10 – Creating a new endpoint configuration using the Amazon SageMaker console.
Now, you can publish the endpoint using this endpoint configuration. Navigate to SageMaker > Inference > Endpoints and create a new endpoint.

Figure 11 – Publishing an endpoint using the Amazon SageMaker console.
You can test this model out from your Domino Jupyter/JupyterLab notebook or an Amazon SageMaker notebook with the following code (link to full notebook):
For this test case, we were able to get the following output from the model:
Tear Down Your Amazon SageMaker Endpoint
Now that your model is in production as an Amazon SageMaker Endpoint, keep an eye on it. Although it’s beyond the scope of this post, the Domino Model Manager (DMM) allows you to monitor your model for performance and data drift over time.
When you notice your model performance degrade, you will likely want to publish a new version of your model.
I’ll quickly go through the process of removing your model from Amazon SageMaker to ensure resources are freed up when your model is no longer needed, or when you want to perform general hygiene after the exercises in this post.
There are three things you need to clean up:
- Amazon SageMaker Endpoint
- Amazon SageMaker Endpoint Configuration
- Amazon ECR Image
In the Amazon SageMaker console, navigate to Inference > Endpoints. Select the endpoint you created in the previous steps. Then, navigate to Actions > Delete.
Next, delete the Amazon SageMaker Endpoint Configuration by navigating to Inference > Endpoint configurations. Following the same process as before, select the Endpoint configuration created in the prior steps, then go to Actions > Delete.

Figure 12 – Deleting an Amazon SageMaker Endpoint Configuration.
For the final step, you can delete the Amazon ECR image that Domino exported. Though not mandatory, this is generally a good hygiene practice to ensure your ECR registry isn’t littered with unused images that get forgotten over time, leading to additional storage costs.
Navigate to the Amazon ECR console. From there, navigate in your repository (domino-sagemaker-exports in our example). On the repository image browser page, select the image that was exported by Domino and select the Delete button.

Figure 13 – Deleting the Domino-exported image from Amazon ECR.
Conclusion
With this guide, you should be able to export a Domino model for deployment in Amazon SageMaker. For more information, or other examples of how code-first data scientists at Fortune 100 companies use Domino, please visit the Domino Data Science Blog.
Additional Resources
- Model Management: A Framework to Build a Model-Driven Business (Domino whitepaper)
- Domino product demo
- Domino product documentation
- Free trial of Domino
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
Domino Data Lab – AWS Partner Spotlight
Domino Data Lab is an AWS Advanced Technology Partner that empowers code-first data science teams to overcome these challenges of building and deploying data science at scale.
Contact Domino | Partner Overview | AWS Marketplace
*Already worked with Domino? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.