AWS Partner Network (APN) Blog
Leveraging Neo4j and Amazon Bedrock for an Explainable, Secure, and Connected Generative AI Solution
By Ezhil Vendhan, Sr. Cloud Partner Architect – Neo4j
By Antony Prasad Thevaraj, Sr. Partner Solutions Architect – AWS
 |
| Neo4j |
 |
Amazon Bedrock is a fully managed service that enables customers to build and scale generative artificial intelligence (AI)-based applications using foundation models (FMs), democratizing access for all builders. Neo4j is a graph data platform that, together with Amazon Bedrock, offers a compelling value add to any enterprise.
Amazon Bedrock offers a choice of high-performing FMs from Amazon and leading AI startups including AI21 Labs, Anthropic, Cohere, Meta, and Stability AI accessible via single API, along with a broad set of capabilities you need to build generative AI applications. This simplifies development while maintaining privacy and security.
Generative AI has the potential to lower the barrier to entry to build AI-driven organizations. Large language models (LLMs) in particular can bring tremendous value to enterprises seeking to explore and utilize unstructured data. Beyond chatbots, LLMs can be used in a variety of tasks such as classification, editing, summarization, and drafting.
With Amazon Bedrock, you can easily experiment with a variety of top FMs, privately customize them with your data using techniques such as fine-tuning and retrieval augmented generation (RAG), and create managed agents that execute complex business tasks—from booking travel and processing insurance claims to creating ad campaigns and managing inventory—all without writing any code.
Since Amazon Bedrock is serverless, you don’t have to manage any infrastructure and can securely integrate and deploy generative AI capabilities into your applications using the AWS services you’re already familiar with.
Neo4j is an AWS Specialization Partner and AWS Marketplace Seller with the Data and Analytics Competency. Neo4j has defined the graph database space, and in this post we’ll cover how Neo4j integrates with Amazon Bedrock and aids in providing relevant and contextual responses using an enterprise’s private data.
Making LLMs Better with Neo4j
Large language models can be made more accurate by fine-tuning, few shot prompting, and grounding. Fine-tuning an LLM can be used to steer it to perform narrower tasks, while few shot prompting and other prompt engineering techniques teach an LLM to improve the way it responds to a particular request. These approaches alone will not suffice to meet the demands of enterprises, however.
Grounding minimizes hallucinations, eliminates bias, and provides explainability and data access controls. This is where Neo4j brings value, as knowledge graphs (KG) can be a memory layer for an LLM and enable factual data retrieval in real-time.
Questions in the real world often involve making multiple hops as they help uncover insights from connected data, and native graphs excel in multi-hop retrievals. Along with multi-hop retrievals, Neo4j acts as a vector database to perform vector similarity search. Both can be combined to bring more relevancy to RAG, and vectors can bring in similar data and multi-hop retrieval to facilitate filtering and fetch additional context.
With role-based access control (RBAC) support, enterprises have complete control over data retrieval, while there is also explainability in the retrieval. Moreover, knowledge graphs are transformative solutions that can be leveraged to solve a multitude of use cases.
Knowledge Retrieval Using Vector Search
Retrieving from Neo4j as a memory layer using LLMs can be advantageous as graphs provide a human-readable representation of data, allowing highly complex questions involving multiple hops to be answered with ease. With RBAC in Neo4j, access to nodes and relationships can be controlled.
Since Neo4j supports vector indexes, similar search algorithms can be applied for retrieval. Neo4j vector indexes are powered by Apache Lucene indexing and search library; Lucene implements a hierarchical navigable small world (HNSW) graph to perform a k approximate nearest neighbors (k-ANN) query over the vector fields.
When combined with retrieving-related nodes in the graph, there can be considerable improvements in contextuality, accuracy, and explainability to drive relevant and accurate responses.
For example, a query about budget-friendly cameras for teenagers will return low-cost, durable options in fun colors by interpreting the contextual meaning. That question would be turned into an embedding by a text-embedding model and passed into the Cypher (Neo4j’s query language) query for the search.
The snippet below finds the top five products using vector similarity search, and then enriches each product with their category, brand, and (optionally) with reviews by customers who bought and rated them a 5:
A RAG workflow using Neo4j as vector database can include both similar and semantic matches, which can ground the LLM better than a vector-only approach.
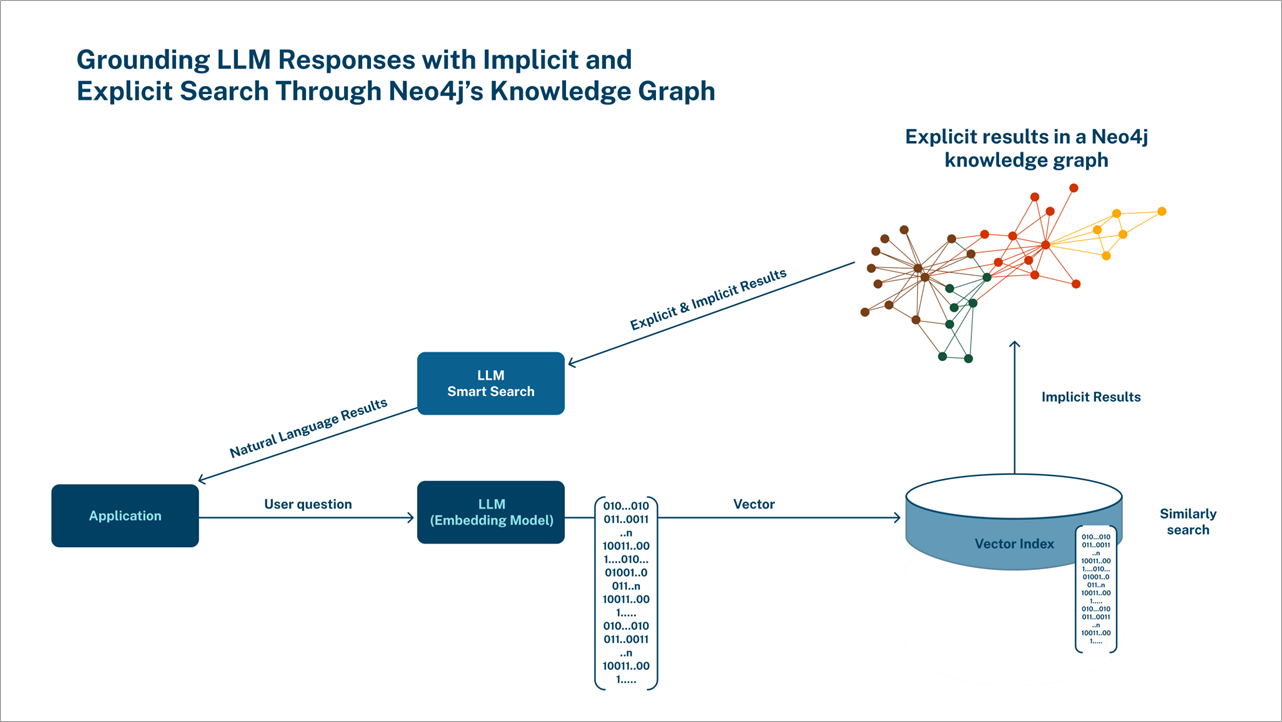
Figure 1 – RAG using Neo4j as a vector store.
Knowledge Retrieval Using Generated Cypher
Another RAG flow involves using LLMs to convert natural language queries to Cypher using prompt engineering. Given a Neo4j schema information, a user’s question can be converted to relevant Cypher query accordingly. This query can then be executed in the database, and results are retrieved and sent as context to answer the question back to the LLM.
Using few-shot prompting or fine-tuning, accuracy can be improved. This kind of RAG flow is demonstrated in Figure 2.
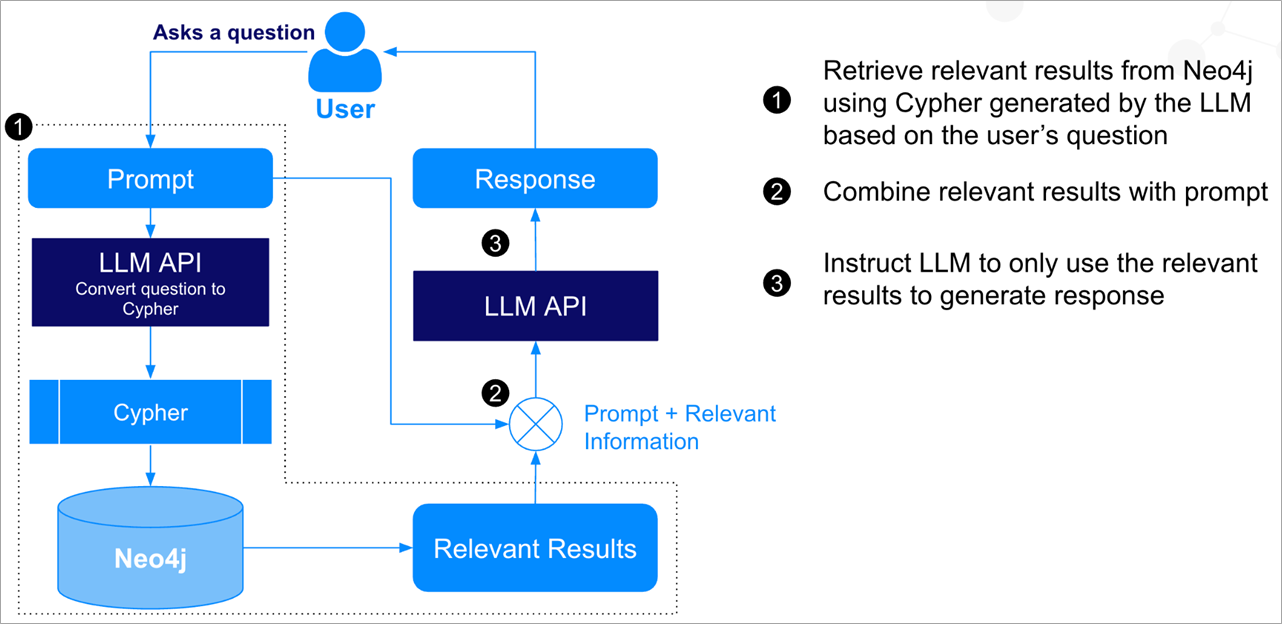
Figure 2 – RAG using natural language to Cypher on Neo4j.
Let’s consider a graph of Security Exchange Commission (SEC) Form 13 quarterly filings, which typically looks like this:

Figure 3 – Graph data model representing SEC Form 13 filings.
To convert an English-language query to retrieve results from Neo4j, we can use this prompt to convert English to Cypher query. In this prompt, we’ll be passing the Neo4j schema information so that the Anthropic Claude LLM running on Amazon Bedrock can generate relevant Cypher.
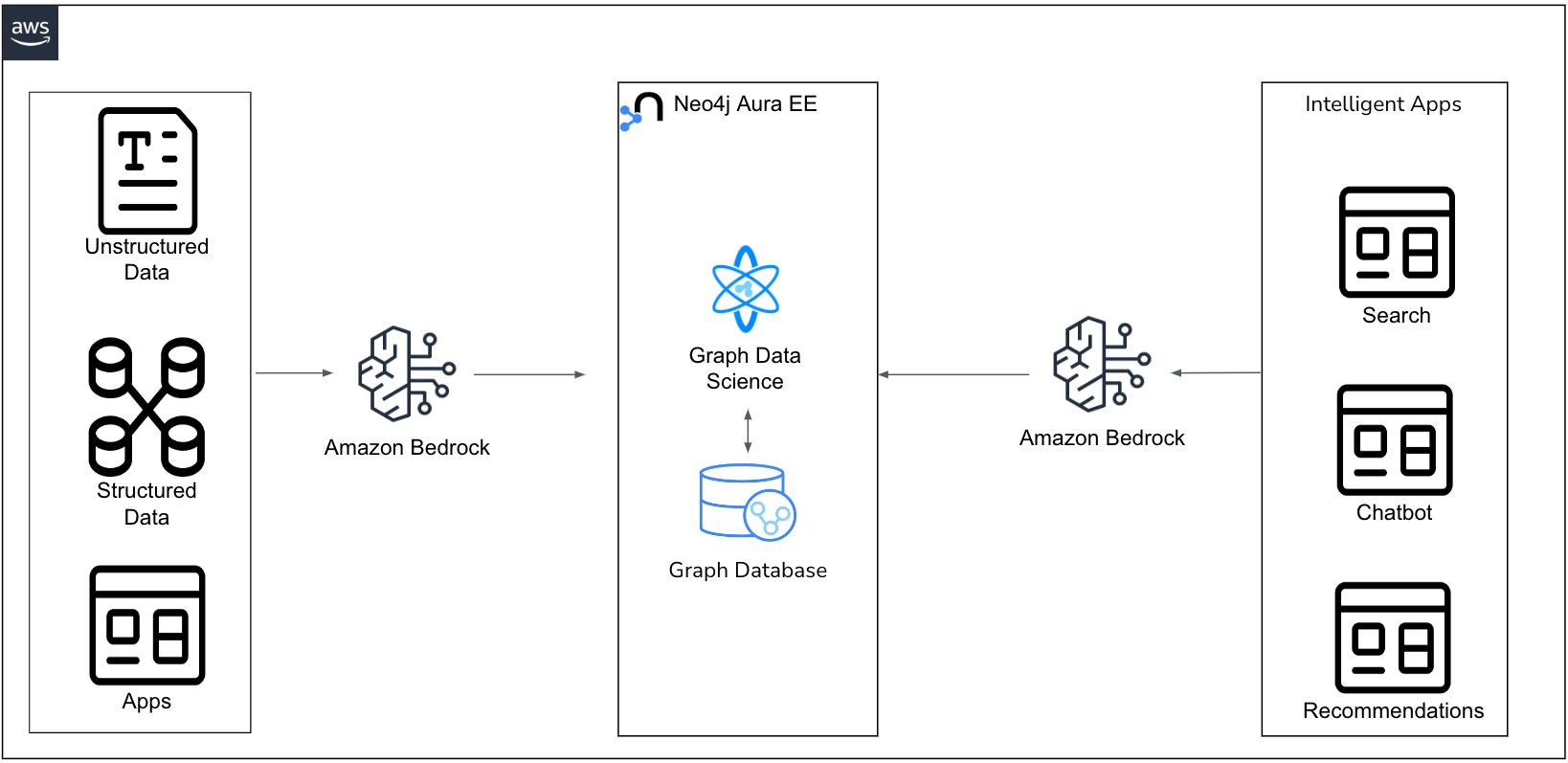
Figure 4 – Amazon Bedrock and Neo4j-powered data ingestion and RAG flow.
The prompt below instructs the LLM to generate Cypher from the user’s query based on the Neo4j schema adhering to certain rules. It also provides a few examples (few shot prompting) to guide the LLM on how to respond:
When asked this question – “How many managers own more than 100 companies and who are they?” – the LLM on Amazon Bedrock will generate this Cypher query:
The query can then be executed in Neo4j to retrieve the following results:
- BROOKFIELD CORP /ON/ owns 649 companies
- BERKLEY W R CORP owns 236 companies
- Granahan Investment Management, LLC owns 165 companies
- GENEVA CAPITAL MANAGEMENT LLC owns 123 companies
- DEERFIELD MANAGEMENT COMPANY, L.P. (SERIES C) owns 106 companies
- ARBOR CAPITAL MANAGEMENT INC /ADV owns 106 companies
- NEW ENGLAND ASSET MANAGEMENT INC owns 101 companies
Building a Knowledge Graph
With the help of connectors, it’s fairly straightforward to build knowledge graphs using data pipelines from structured and semi-structured data. Note that unstructured data involves complicated natural language processing (NLP) pipelines. LLMs can understand unstructured data and can be prompt engineered to extract entities and relationships in accordance to a predefined graph schema.
Going back to the SEC example, we can prompt the LLM to extract entities and relationships according to the schema we want, and then build a knowledge graph to extract filing information, as demonstrated here:
Once ingested to Neo4j, the data will look like this:
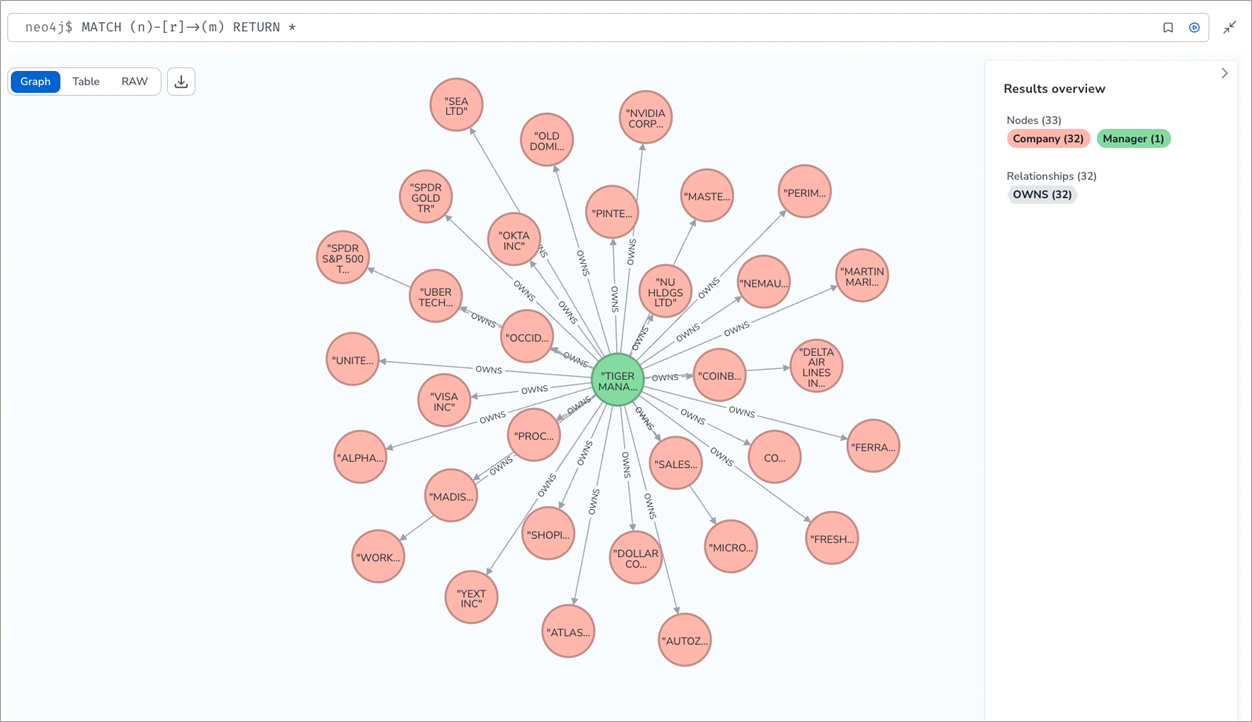
Figure 5 – Ingested SEC Form 13 filing.
Potential applications of this knowledge graph in the capital markets space includes creating graph embedding features that can be used for algorithmic trading, understanding tail risk, securities master data management, and so on.
Conclusion
In this post, we walked through knowledge retrieval and extraction processes using Amazon Bedrock and Neo4j, and reviewed a couple of retrieval augmented generation (RAG) application architectures.
Using Amazon Bedrock, we simplified the knowledge extraction process which can be more complex and manual using traditional NLP libraries. Neo4j provides options to do RAG using vector indexes and an enriched data, LLM-generated Cypher. Thus, enterprises can build intelligent systems that are consistent, accurate, and explainable.
Using Neo4j as a memory layer with an LLM provides leverage to tackle multiple use cases. It’s not just an endpoint-specific solution; it can be transformative for enterprises to solve challenges like:
- Finance: Financial documents can be complex to navigate for customer service professionals. Semantic search can help answer questions from semantically connected data stored in a knowledge graph.
- Manufacturing: Warranty analytics using technical and warranty documentations can help service engineers understand history of issues, search for solutions from similar incidents, and uncover unseen connections and trends.
- Supply chain: Enterprises use Neo4j for a wide variety of supply chain use cases like demand sensing, supply management, and channel shaping. LLMs can be used to enrich data from real-time news events to social media.
The example we worked through in this post can be explored in GitHub. We hope you fork it and modify it to meet your needs. Pull requests are always welcome!
If you have any questions, reach out to ecosystem@neo4j.com.
.

.
Neo4j – AWS Partner Spotlight
Neo4j is an AWS Partner that enables organizations to unlock the business value of connections, influences, and relationships in data.