AWS Partner Network (APN) Blog
Orchestrating Multi-Region Apps with Red Hat Advanced Cluster Management and Submariner
By Mehdi Salehi, Sr. Partner Solutions Architect – AWS
By Konstantin Rebrov, Hybrid Cloud Solutions Architect – IBM
 |
| IBM |
 |
Customers have different reasons to run multiple Red Hat OpenShift clusters. Apart from the need to manage and synchronize dev, staging, and prod environments separately, there are other reasons like having separate clusters per geographical locations, setting a cluster-level boundary between mission-critical applications, data residency, and reducing latency for end users.
Therefore, it is not surprising to see hundreds or even thousands of OpenShift clusters running in some organizations. Now, the question is how to centrally manage the lifecycle and security of these clusters regardless of where they reside, and monitor them from a single pane of glass. This is where Red Hat Advanced Cluster Management for Kubernetes (RHACM) comes into play. It provides a single console which extends the value of OpenShift by deploying applications, managing multiple clusters, and enforcing policies across multiple clusters at scale.
Leveraging the power of Red Hat OpenShift on Amazon Web Services (AWS), IBM enables a powerful and fast digital transformation platform to help customers with their cloud journey across multi-cloud, on-premises, and edge environments. This helps customers focus on their core business, and generate value for their end-users faster.
In this post, we explore how Red Hat Advanced Cluster Management for Kubernetes extends the value of Red Hat OpenShift for hybrid environments. IBM is an AWS Premier Tier Services Partner that offers consulting services and software solutions.
Red Hat Advanced Cluster Management at a Glance
RHACM provides end-to-end visibility and control to manage your Kubernetes environment. It consists of a hub cluster as the central controller and one or more managed clusters, which are created or imported into the RHACM environment. The managed clusters communicate with the hub through their Klusterlet, pulling whatever configuration or information is needed.
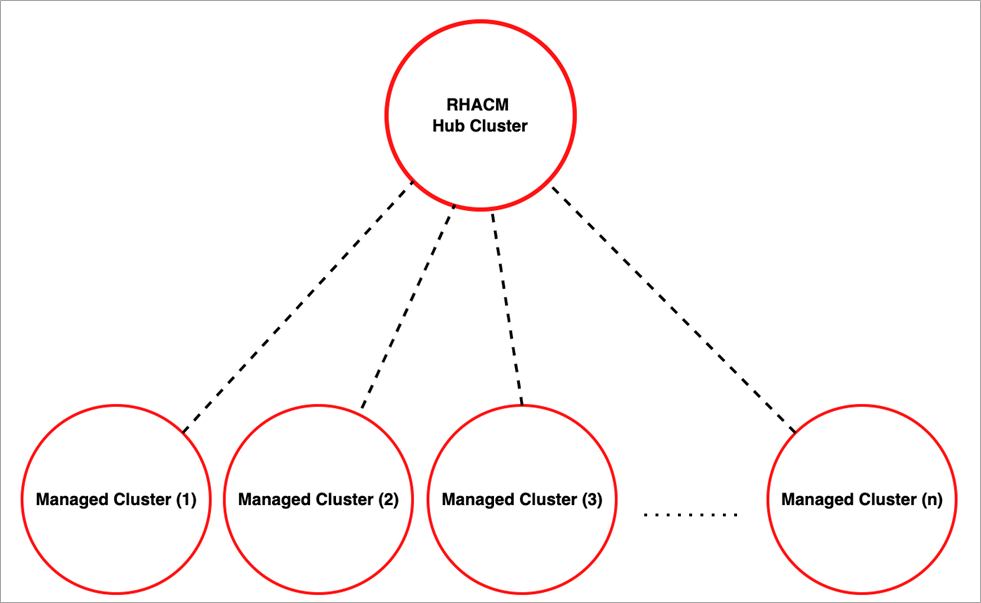
Figure 1 – The hub and managed clusters in RHACM.
The hub is an OpenShift cluster which has an Operator for Advanced Cluster Management for Kubernetes installed. In the following test scenario, OpenShift Container Platform (OCP) on AWS has been used to host both the hub and managed clusters. Please refer to the RHACM documentation for the list of other supported platforms.
RHACM has several additional components compared to a normal OpenShift environment. For example, Hive Controller interacts with cloud providers like AWS to provision clusters. Another component is Klusterlet, which has a controller on the hub cluster and an agent on each of the managed clusters. This enables cluster lifecycle, application lifecycle, governance, and observability on the managed cluster. To learn more about the architecture, review the product documentation.
When it comes to running applications, the managed clusters can host their own independent container workloads. The applications can also be designed and set up in an active/passive (as well as active/active) multi-cluster scenario.
This is why a cross-cluster network connectivity like Submariner is key. As an open-source tool, Submariner flattens the networks between the connected OpenShift clusters and enables IP reachability between the pods and services. Submariner will be covered in more detail later in this post.
RHACM addresses several challenges and considerations for different personas within an organization, including:
- Developers: RHACM allows application workloads to be portable between Kubernetes clusters wherever they are (on premises or on the hyperscalers). This makes it easy to create OpenShift clusters for different purposes like test and dev environments.
- Operations: A single pane of glass for cluster management, logging, and monitoring helps the team operate the clusters consistently. RHACM also provides application placement rules for different environments like dev, prod, and disaster recovery (DR).
- Security team: Central security management and compliance enforcement of RHACM helps security teams enforce policies and mitigate security risks. It also gives better visibility for auditing applications and clusters.
Creating an RHACM Environment on AWS
In this section, you will learn how to create an RHACM environment. To follow the steps, please make an OpenShift Cloud Platform (OCP) cluster ready on AWS.
Hub Cluster
The hub can be a new or existing OpenShift cluster on premises or on the cloud. This demo uses an existing OCP cluster, which was created on the Red Hat Hybrid Cloud Console.
In the OperatorHub of the hub cluster, find and install Advanced Cluster Management for Kubernetes. Add a MultiClusterHub and wait a few minutes until the environment is fully configured.

Figure 2 – Installing the operator on the hub cluster.
After the operator is created successfully, obtain a URL of the Advanced Cluster from the newly-created route. This can be found in the hub cluster, under Networking or through the command line interface (CLI):
# oc get route multicloud-console -n open-cluster-management -o jsonpath='{.spec.host}{"\n"}'
The URL is based on the cluster name and a random string. For example: multicloud-console.apps.<cluster-name>.xxxx.p1.openshiftapps.com
Managed Clusters
As previously mentioned, the managed clusters can be existing clusters running anywhere, either on premises or on the cloud. For simplicity, provision two new OCP clusters on the Red Hat Advanced Cluster Management console.
First, a credential needs to be created. This is based on the AWS access key and secret access key. Then, follow the installation wizard.
Figure 3 shows local-cluster is the hub cluster where the RHACM operator has been installed, and the other two are the managed clusters created afterwards.
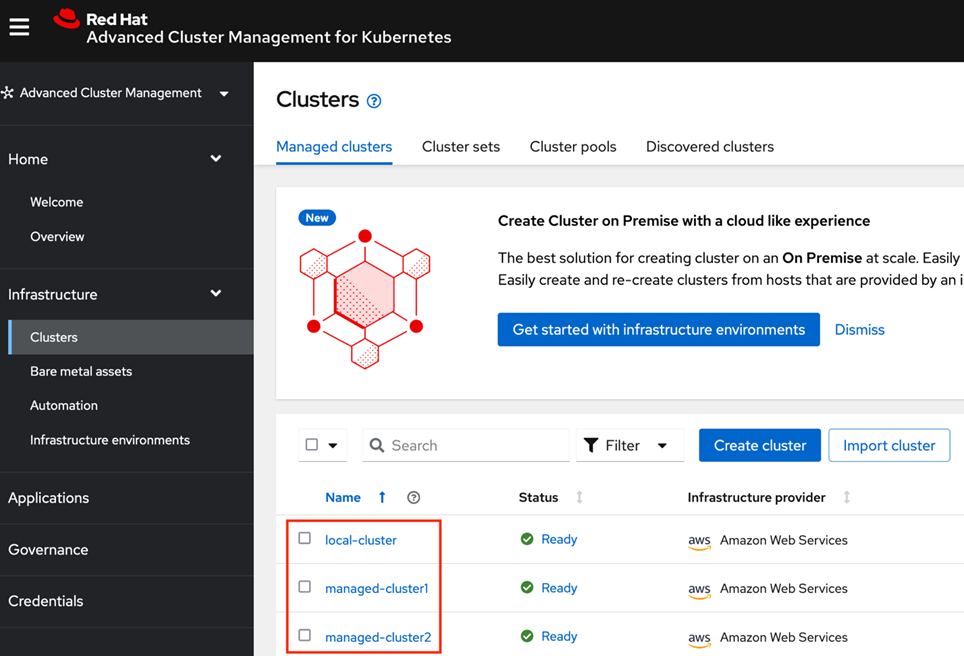
Figure 3 – Red Hat Advanced Cluster Management console.
Placement rules are used to determine which cluster(s) should host an application on RHACM. This works in a similar way to labels and selectors for pod placement. Depending on the use case, customers may choose to run an application on one or more clusters.
To demonstrate the behavior of multi-cluster applications on RHACM, host a sample Etherpad application. If configured properly, Etherpad will provide an online collaborative platform to edit documents regardless of the managed cluster the application is running on.
To create an application, follow the instructions on rhacm-labs. After specifying the application name and its source repository, the placement should be configured. There are a few options to choose from, but as depicted in Figure 4, create a new Placement Rule based on a label. This means that the application will be added to any cluster that has environment=dev label.

Figure 4 – Red Hat Advanced Cluster Management console.
If the managed clusters have the right label (environment=dev) the app will be automatically deployed on them. This can be easily done from the RHACM console or by editing the clusters from the CLI.
In the next step, find the name of the managed clusters and add the required label (environment=dev) to them:
Then, do the same for managed-cluster2:
The Etherpad app contains a few OpenShift resources, including a route. To check if the route has been configured properly, get the application URL first:
Using the above URL (and a similar route for manage-cluster2), an independent instance of the Etherpad app will be available on each of the managed clusters through their corresponding routes:
Figure 5 – The Etherpad app on the managed clusters.
Inter-Cluster Communication
Submariner can be used with RHACM to provide direct networking between pods across two or more clusters. Submariner architecture consists of different components to manage the inter-cluster virtual private cloud (VPC) tunnels, routing, service discover, and more. It even has an optional component (Globalnet) that handles interconnection of clusters with overlapping CIDRs.
Submariner supports heterogenous OpenShift environments, which means you can enable it on OCP clusters that are hosted on a number hyperscalers, like AWS and IBM Cloud, as well as OpenShift clusters running on VMware. The following section covers how to install and configure Submariner on AWS.
Install and Configure Submariner
Installing Submariner manually takes several steps, but RHACM and OpenShift operators have made this process easy for customers.
Step 1: Create a Cluster Set and Add the Managed Clusters
ManagedClusterSet resources allow the grouping of cluster resources, which enables role-based access control (RBAC) management across all of the resources in the group.
To create the cluster sets from the RHACM console, select Clusters. Then, choose Cluster sets.
Once the cluster set is created and one or more nodes are added into it, new objects, like ManagedClusterSet, ClusterRole, and ClusterRoleBinding will be created in the hub cluster.
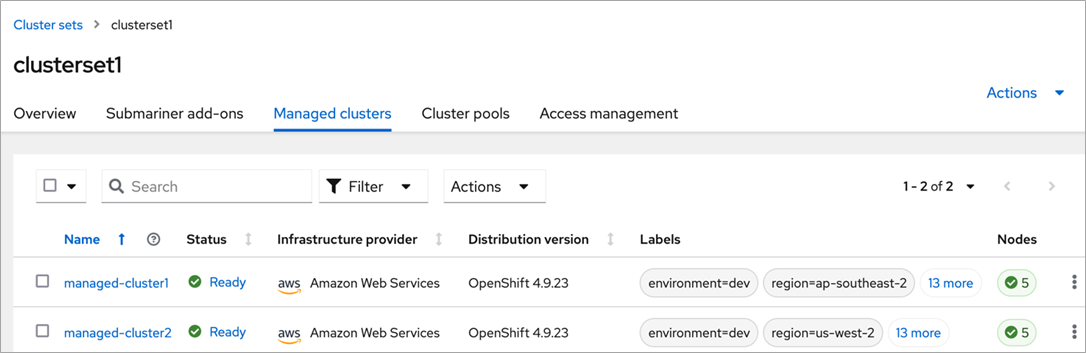
Figure 6 – Cluster set and its managed clusters in the RHACM console.
Now, double check the recently-created resources from the command line by finding out the cluster set name first:
Each managed cluster should now have a label indicating the cluster set name:
Step 2: Install the Submariner Add-On
To begin forming a multi-cluster network, at least two clusters in the cluster set must have the Submariner add-on installed. Installing Submariner takes several steps if you do it manually, but RHACM makes the process easy.
Figure 7 shows where the Submariner add-ons installation process begins. This creates a gateway node (a c5d.large instance by default) on each of the managed clusters. In this demo, t3a.large is selected to save 25% cost on the gateway nodes.

Figure 7 – Installing Submariner add-on on managed clusters console.
As a result, the Submariner operator will be installed on the managed clusters in the cluster set. This can be verified from the console of each managed cluster or from the following CLI:
Submariner is now deployed on the clusters. The next step is to configure a multi-cluster application and demonstrate how Submariner works.
Sample Multi-Cluster Application on Submariner
This section shows you how to deploy an active/passive PostgreSQL database on two OpenShift clusters which are running in two different AWS Regions. This scenario requires cross-cluster communication to be configured on RHACM.
In Figure 8 below, managed-cluster1is an OpenShift cluster running in ap-southeast-2 (Sydney), and managed-cluster2 is another cluster in us-west-2 (Oregon) region. Changes on the primary database will be replicated to the secondary database across the Submariner link, and as a result the Kubernetes applications will be able to access the database regardless of the location of the active database:
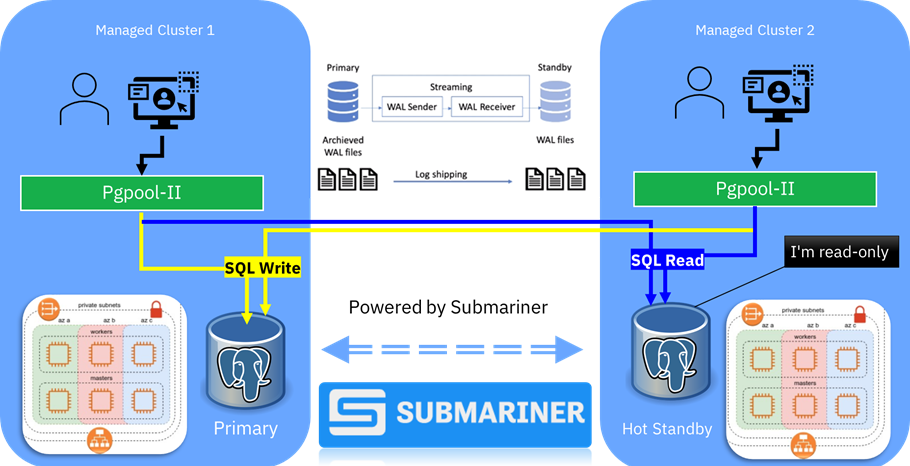
Figure 8 – An active/hot-standby app on a multi-cluster environment.
Pgpool-II is a middleware that works between PostgreSQL servers and a PostgreSQL database client and provides several features, including replication and connection pooling load balancing. When the application connects to the PostgreSQL service, the connection goes through Pgpool-II. This means the Kubernetes applications will get a consistent database experience, no matter which database instance is active and which one is hot standby.
Configuring the Database Layer
The following sample specification can be used to configure a deployment. This will be the database layer in Figure 9, highlighted in green:
StatefulSet is a Kubernetes component used specifically for stateful applications. The following yaml specification represents the StatefulSet used in this demo.
Configure a Client Application Which Uses the Database:
Since Pgpool-II acts as a proxy between the application clients and the database layer, in the following sample deployment, DB_HOST has been set to a service called “pgpool”, not the individual databases on the managed clusters:
Failover Test
So far, you have set up a two-node Pgpool-II environment across two OpenShift clusters. Before simulating the failover process, check the status of Pgpool-II nodes. Figure 9 shows cluster1 and cluster2 have primary and standby roles, respectively:

Figure 9 – The primary and standby database nodes.
The managed clusters in this scenario have been created through the Advanced Cluster Management console, therefore they can be hibernated to simulate cluster failure. For further information about the hibernate feature, read this article.
As shown in Figure 10, when cluster1 fails, the status of the primary database will be set to down.

Figure 10 – Cluster1 is down.
There are several options (outside the scope of this post) to automate the process of promoting a standby Pgpool-II node to a read/write primary. For simplicity, use the following command:
As a result, cluster2 takes the primary role and serves the read and write requests, as shown in Figure 11.

Figure 11 – Failover succeeded.
Cleanup
Red Hat Advanced Cluster Management for Kubernetes consists of a hub cluster and one (or more) managed clusters. The easiest way to clean up the environment is to delete the managed clusters from the RHACM console. This will subsequently remove all the underlying AWS resources.
To delete the hub cluster, treat it as if it’s a standalone cluster. Since the hub in this demo is an OCP cluster, use the OpenShift installer utility to delete the cluster:
# openshift-install destroy cluster --dir hub-cluster
To retain the hub cluster, but clean up the Advanced Cluster footprint, remove its operator from the OperatorHub. This can be done from the console or using the CLI. For more details, review the OpenShift documentation.
Conclusion
In this post, we demonstrated Red Hat Advanced Cluster Management for Kubernetes and covered how it extends the value of Red Hat OpenShift for hybrid environments. We explored different scenarios where having a multi-cluster environment is beneficial. In addition to providing a single pane of glass for cluster management and compliance, we also discussed how to set up a secure private network across the nodes for scenarios like data replication and global applications.
Finally, we demonstrated how a stateful application can rely on data replication across two OpenShift clusters for availability and business continuity.
To learn more, visit the RHACM product documentation and consider taking the Red Hat official course: Multicluster Management with Red Hat OpenShift Platform Plus.
For further information—including OpenShift migration projects and advanced-level consultations—contact IBM and/or Red Hat.
.
 .
.
IBM – AWS Partner Spotlight
IBM is an AWS Premier Tier Services Partner that offers consulting services and software solutions. IBM has assembled an ecosystem of highly experienced professionals dedicated to deploying customer solutions on AWS.