AWS Partner Network (APN) Blog
Re-Writing a Mainframe Software Package to Java on AWS with Ippon Technologies
 |
 |
By Austin Tilman, Consultant at Ippon
By Kevin Wrigglesworth, Senior Consultant at Ippon
By Dennis Sharpe, Chief Technology Officer at Ippon
Our team at Ippon Technologies, an AWS Partner Network (APN) Advanced Consulting Partner, has successfully re-written a large mainframe third-party software package to Java Angular Spring Boot microservices.
The package supported 130 TPS and 1,800 MIPS, catered to over 5,000 users, and housed more than 5 TB of business-critical data.
Our target architecture relies on Amazon Web Services (AWS) Java microservices, and we helped the customer define the approach and architecture, and then developed the microservices along with the Continuous Integration/Continuous Delivery (CI/CD) pipeline on AWS.
In this post, we’ll describe the project’s technical aspects, methodologies used, and lessons learned from our mainframe package re-write experience.
Approach
Our customer wanted to reduce costs and improve time-to-market for a mainframe workload, so the primary tasks required on this project were to migrate the mainframe data to the new system, recreate the business logic with some improvements, and build a completely new web user interface.
We strived to adhere to the characteristics of a microservice architecture, and included Domain-Driven Design for complex domains, the Strangler Pattern, and Hexagonal Architecture. The project’s microservices were designed as components and organized around business capabilities.
The governance of our services was decentralized with a you-build-it-you-own-it model, empowering the teams and engineers behind the platform to make technical decisions that differed between services. Infrastructure deployment and testing was also fully automated via a CI/CD pipeline and testing frameworks.
The Strangler pattern worked especially well for data migration and feature development, and we chose the lowest impact parts of the system to build in the new application first.
Mainframe Requirements Gathering
The product owners all had knowledge of the existing mainframe package and business processes the system was responsible for supporting. We used a fully Agile methodology that we scaled with the Scaled Agile Framework (SAFe). Because of this, we did not need to spend much time up-front to understand every aspect of the mainframe package.
We defined a Minimum Viable Product (MVP) broken into features (epics), and product owners were assigned to every Agile team provided with detailed specifications. At the beginning, and then after every three or four sprints, we had all-day Program Increment (PI) planning sessions where work was distributed to the teams.
This approach enabled us to migrate application logic while enhancing and improving existing business processes in an Agile manner.
Technical Architecture on AWS
The primary interface for the application was for internal customer service representatives. However, there were quite a few heavy batch processes required to integrate with other systems in the data center and third parties.
Since much of the code was shared between batch and online processes, each microservice had only one codebase that supported both types of processes. The microservices were created using Spring Boot by APN Partner Pivotal, and were then deployed as jar files with an embedded server. The batch processes were started using REST endpoints and Kafka messages that triggered Spring Batch jobs.
Early in the project, we developed and maintained one data model shared by all microservices and teams. Eventually, this ever-growing single data model became overwhelming to update and maintain. It had to be separated into bounded contexts (ideally one bounded context per microservice) that each team could own and maintain, while making sure it was still compatible with the data models produced by other teams. This process took several iterations before the data model was usable and evolved throughout the project.
Each microservice managed its own datasource, and the only way to modify that datasource was through the REST APIs or events for asynchronous communication. Events were designed to alert other microservices to make API calls to get the data they needed, or contained data that needed to be updated. Apache Avro schemas were developed for each event, and an API call could be made to get the schema for any event.

Figure 1 – Microservices architecture on AWS.
AWS Services
The primary AWS services used in the architecture were Amazon Elastic Compute Cloud (Amazon EC2), Auto Scaling Groups, Elastic Load Balancer, and Amazon Simple Storage Service (Amazon S3). We used Amazon S3 for third-party integrations as well as for transferring large amounts of data between microservices. The Spring Boot microservices ran in multiple Amazon EC2 instances with an Elastic Load Balancer in front. They were auto-scaled to always maintain at least two running instances.
Application testing was almost entirely automated on AWS. The CI/CD pipeline is a critical part of a microservices-based system, and this project required JUnit tests to perform 95 percent of code coverage with no issues (major or minor) allowed, which was enforced by SonarQube. Acceptance tests used Cucumber.
The pipeline used dynamically-created AWS environments separated from development environments. The Consumer-Driven Contracts pattern verified that no microservice violated its contract with other services. Code was automatically moved from development to Quality Assurance (QA) with all test results documented for a manager to approve prior to production deployment.
Many times, we had very large features that spanned multiple teams, microservices, and even Agile Release Trains (ARTs) and departments. While these features were tested heavily via the automated frameworks, we also made sure to manually test the integration of these features in pre-production environments as a final step before release. This was particularly helpful when it came to ensuring that all communication between microservices worked as expected.
Mainframe-to-AWS Migration
Data migration and feature development were tightly coupled with the implementation of the Strangler pattern to gradually replace parts of the legacy system. We approached the migration process by organizing groups of accounts by the risk associated with that account population, and the functionality required to adequately service that account.
We started with the population with the lowest risk and required functionality—essentially a “read-only” population—and began designing and developing the features necessary to service those accounts. This included a user interface and microservice backend.
Features were focused around building our account-centric domain model, displaying that account information in the user interface. Each feature that added fields and data to our domain model also included one-time batch jobs that were responsible for loading all required data from accounts in the legacy system.
For tracking mainframe package continuous data updates in DB2 z/OS, we created an Amazon RDS for PostgreSQL database, which was batch-updated every morning to reflect the previous day’s DB2 z/OS change log. A Kafka message then kicked off a “sync” job for all interested microservices that read and applied their own data changes.

Figure 2 – Data synchronization from mainframe-to-AWS microservices.
Once an epic was complete (all features required to service a specific population had been finished), accounts were converted to being serviced on the new system. In a nutshell, the conversion process purged all data from the live legacy system ending any “sync” updates that would come through, and preventing users from accessing that account on the legacy system.
This process was repeated over and over again with each population of accounts, steadily building out functionality in the new system, while at the same time strangling the functionality out of the old system. This empowered the business to migrate, enhance, and improve their processes in an Agile-friendly manner.
Teams and Sprints
An entirely new ART was formed for the development of the new AWS microservices platform. The existing mainframe development team remained intact and continued to provide support for the mainframe package in addition to supporting our migration needs.
The new ART was initially formed of six engineering teams. Each had a Product Owner, Scrum Master, and four or five engineers of varying skill levels. Each team was responsible for designing, building, and maintaining their own microservices, and were empowered to do so.
Sprints were broken down into 10 working days. A PI was initially comprised of four sprints, but this fluctuated over time as management and the Release Train Engineer (RTE) adjusted the interval to fit our project and goals. Eventually, we found that two sprint PIs were more effective for our ART when it came to planning and delivering on intent.
Project Plan Overview
The project had a budget and timeline for two-and-a-half years. A large part of the initial effort was building the complete CI/CD pipeline. Phases were defined according to the Strangler pattern by migrating sequentially accounts of increasing criticality.
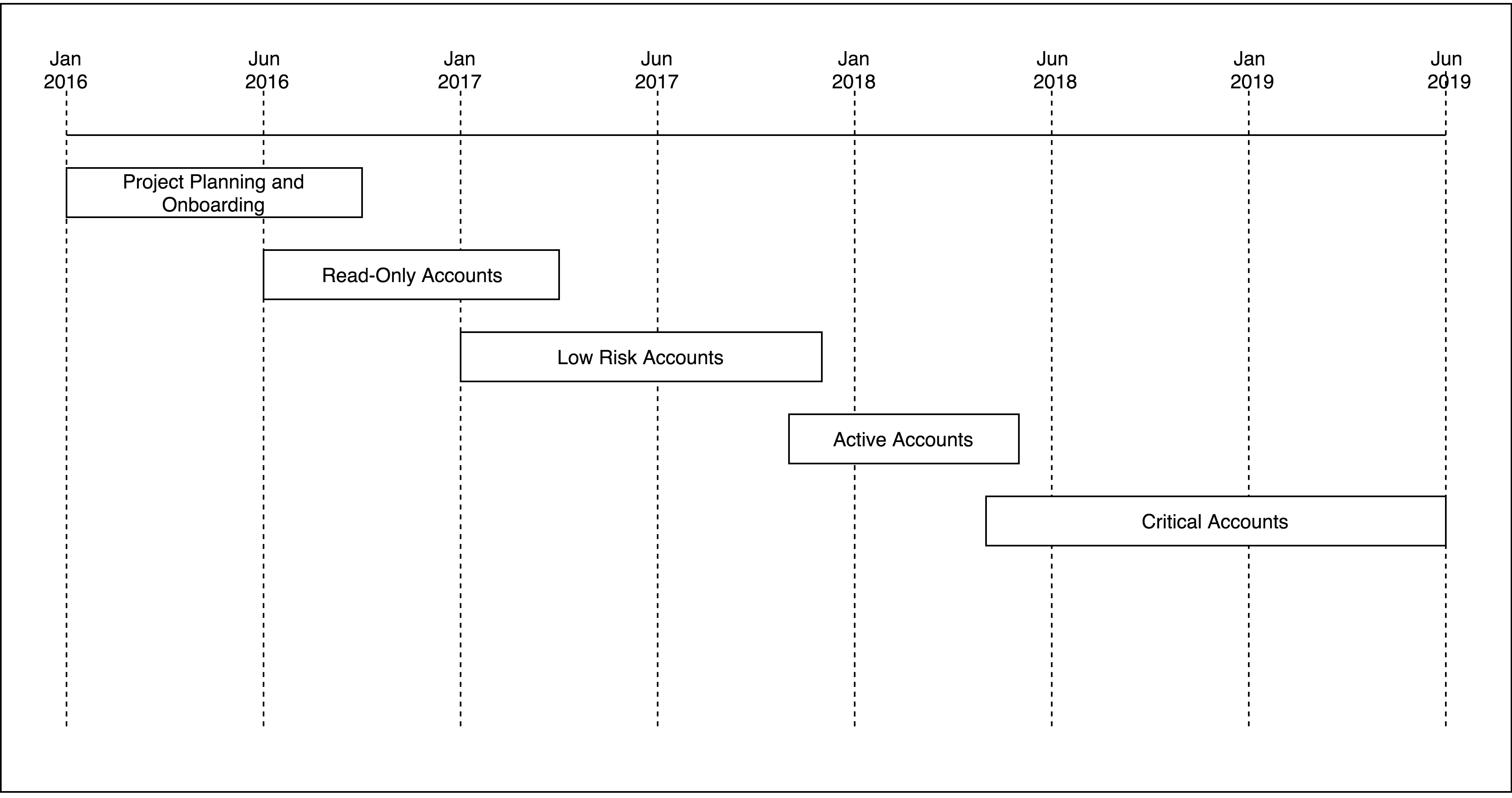
Figure 3 – Project plan phases.
Best Practices and Lessons Learned
In addition to best practices that come with a microservice architecture and Domain-Driven Design, the platform strived to adhere to many principles such as the Twelve-Factor App methodology and SOLID five design principles.
Command Query Separation (CQRS) was a common design pattern we followed, as it fit well with REST and messaging principles chosen as the preferred methods of communication for the new platform. When history and auditing was a requirement, we opted for the Event Sourcing Pattern. Code and packaging was organized around a Hexagonal Architecture (also known as ‘Clean Architecture’), as this was a good fit with our Domain-Driven Design standards.
From a data quality perspective, the legacy system seemed to follow strange standards and practices. It’s worth recommending that you take the time to analyze the data you plan to migrate for each feature without making assumptions.
We wanted to operate on our data as much as possible on AWS, so this was an early practice we adopted to avoid blindly loading TBs of data before realizing most of it needed a cleanup. When data cleanup was a requirement, it was done during data load and synchronization within the AWS microservice applications.
From a microservice size perspective, an anti-pattern worth mentioning regards nanoservices. We recommend you don’t draw your boundaries around logical scopes that are too small.
We made this mistake initially by maintaining an account-centric microservice that held all account-related information, and placing customer-centric information in its own customer microservice. But we were never going to need to access customer information without also needing the account information at the same time. Shortly into development, we realized the pain we had caused ourselves and had to stop to merge the two services into one.
Customer Benefits
Our customer is seeing many benefits from this mainframe-to-AWS migration:
- Mainframe exit: Our customer had an enterprise-wide initiative to exit their on-premises mainframe datacenter. This project made a significant contribution to that effort as we actively developed the new platform in the cloud.
- Control: The legacy mainframe package was a vendor product that had hefty licensing costs and strict terms, with limited control over system modification. The customer’s business was shaped rather extensively by the legacy system, and this was beginning to cause strain on their operations. Our application handed control over their processes back to them, and allowed the customer to enhance and automate parts of their business that had previously been reliant on massive spreadsheets and convoluted macros.
- Cost: The maintenance cost of the microservices application was much lower than maintaining the legacy mainframe system. The migration eliminated the hefty mainframe licensing fees, and once the AWS Cloud environment was tuned and optimized, operational costs were considerably lower in comparison to the cost of operating a mainframe.
Next Steps
Ippon Technologies specializes in Agile development, data engineering, and DevOps on the AWS Cloud. We can help you with critical java, big data, blockchain and decentralized solutions, software development, mobile, and API project delivery.
We also assist with Agile coaching or the creation of Agile delivery centers. Learn more about Ippon >>
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.
|
Ippon – APN Partner Spotlight
Ippon is an APN Advanced Consulting Partner. They specialize in Agile development, data engineering, and DevOps on the AWS Cloud. Ippon helps with critical java, big data, blockchain and decentralized solutions, software development, mobile, and API project delivery.
Contact Ippon | Practice Overview
*Already worked with Ippon? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.