AWS News Blog
Auto Scaling Update – New Scaling Policies for More Responsive Scaling
Auto Scaling helps you to build systems that respond to changes in the demand for compute power by launching additional Amazon Elastic Compute Cloud (Amazon EC2) instances or terminating existing ones.
As I was thinking about this post, I thought it would be fun to deconstruct Auto Scaling to ensure that I (and you) have a full understanding of how it works and how it makes use of other parts of AWS (in practice most of our customers use Auto Scaling to launch and terminate instances on their behalf; this is more of a look behind the scenes and an illustration of how different parts of AWS depend upon and build on each other). Here are the moving parts:
Resource Creation – In order to be able to implement Auto Scaling, we need to have the ability to launch and terminate EC2 instances as needed. Of course, AWS is API-driven and these operations are handled by the RunInstances and TerminateInstances actions, assisted by DescribeInstances:
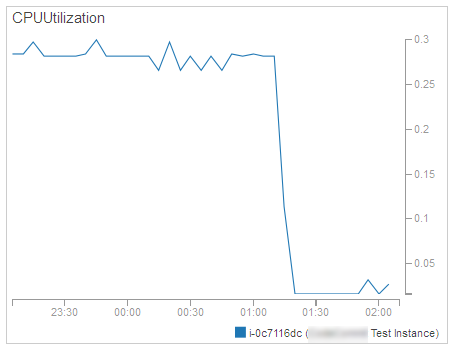
Resource Monitoring – We need to measure and track how busy (in terms of CPU utilization, network traffic, or other metrics) our instances are (both individually and collectively) in order to be able to make informed scaling decisions. This is handled by Amazon CloudWatch:
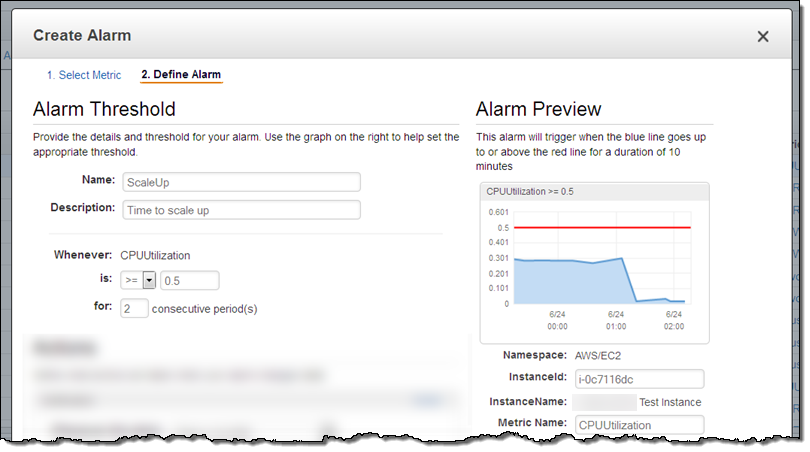
Alarms – Now that we are tracking resource utilization, we need to know when the operating conditions dictate a scale-out or scale-in operation. This is also handled by CloudWatch:
Scaling Actions – The final step is to actually take action when an alarm is raised. This is handled by Auto Scaling, as directed by a CloudWatch Alarm:
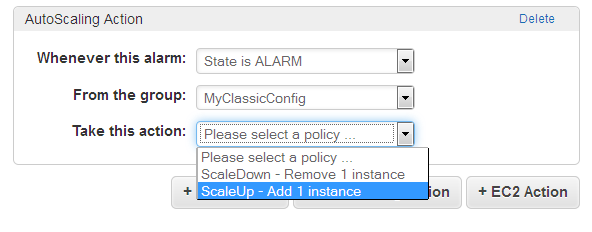 The actions are defined within a particular Auto Scaling Group, and can add or remove a specific number of instances. They can also adjust the instance count by a percentage (add 20% more instances) or set it to an absolute value.
The actions are defined within a particular Auto Scaling Group, and can add or remove a specific number of instances. They can also adjust the instance count by a percentage (add 20% more instances) or set it to an absolute value.
New Scaling Policies With Steps
Today we are making Auto Scaling even more flexible with the addition of new scaling policies with steps.
Our goal is to allow you to create systems that can do an even better job of responding to rapid and dramatic changes in load. You can now define a scaling policy that will respond to the magnitude of the alarm breach in a proportionate and appropriate way. For example, if you try to keep your average CPU utilization below 50% you can have a standard response for a modest breach (50% to 60%), two more for somewhat bigger breaches (60% to 70% and 70% to 80%), and a super-aggressive one for utilization that exceeds 80%.
Here’s how I set this up for my Auto Scaling group:
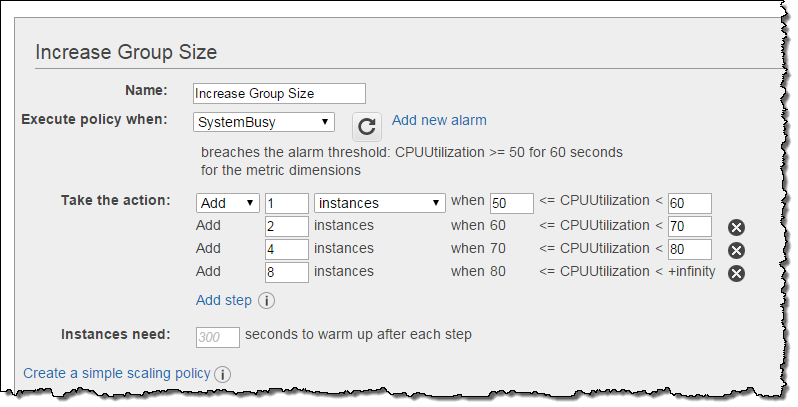
In this example I added a fixed number (1, 2, 4, or 8) of instances to the group. I could have chosen to define the policies on a percentage basis, increasing the instance count by (say) 50%, 100%, 150%, and 200% at the respective steps. The empty upper bound in the final step is effectively positive infinity. You can also define a similar set of increasingly aggressive policies for scaling down.
As you can see from the example above, you can also tell Auto Scaling how long it should take for an instance to warm up and be ready to start sharing the load. While this waiting period is in effect, Auto Scaling will include the newly launched instances when it computes the current size of the group. However, during this scaling time, the instances are not factored in to the CloudWatch metrics for the group. This avoids unnecessary scaling while the new instances prepare themselves to take on their share of the load.
Step policies continuously evaluate the alarms during a scaling activity and while unhealthy instances are being replaced with new ones. This allows for faster response to changes in demand. Let’s say the CPU load increases and the first step in the policy is activated. During the specified warm up period (300 seconds in this example), the load might continue to increase and a more aggressive response might be appropriate. Fortunately, Auto Scaling is in violent agreement with this sentiment and will switch in to high gear (and use one of the higher steps) automatically. If you create multiple step scaling policies for the same resource (perhaps based on CPU utilization and inbound network traffic) and both of them fire at approximately the same time, Auto Scaling will look at both policies and choose the one that results in the change of the highest magnitude.
You can also create these new scaling policies using the AWS Command Line Interface (AWS CLI) or the Auto Scaling API.
This new functionality is available now and you can start using it today.
— Jeff;