AWS for SAP
Deploying SAP HANA on AWS — What Are Your Options?
Sabari Radhakrishnan is a Partner Solutions Architect at Amazon Web Services (AWS).
Are you planning to migrate your SAP applications to the SAP HANA platform or start a new implementation with SAP HANA? If so, you might be wondering what options Amazon Web Services (AWS) provides to run your SAP HANA workloads. In this blog post, I want to discuss the core infrastructure components required for SAP HANA and the building blocks that AWS provides to help you build your virtual appliance for SAP HANA on AWS. I hope that that this information will help you understand deployment options at a high level. This is the first in a series of blog posts that we will be publishing about various SAP on AWS topics, so check back frequently.
If you’re following the SAP HANA Tailored Data Center Integration (TDI) model, memory, compute, storage, and network are the four key infrastructure components that are required for SAP HANA. Among these, memory is the only variable that depends on your data size. Requirements for compute, storage, and network are either preset or derived from the memory size. For example, there are standard core-to-memory ratio requirements that SAP has put in place to determine the number of cores you need for compute, based on the memory size. When it comes to storage, regardless of memory size, you need to be able to meet certain throughput requirements for different block sizes and other KPIs, as laid out in the SAP HANA Hardware Configuration Check Tool (HWCCT) guide. Finally, for network, especially for scale-out scenarios, you need to be able to drive a minimum of 9.5 Gbps of network throughput between the SAP HANA nodes, regardless of memory size.
Over the past several years, AWS has worked closely with SAP to certify compute and storage configurations for running SAP HANA workloads on the AWS platform. How have we been able to achieve that? The answer is that AWS has engineered Amazon Elastic Compute Cloud (Amazon EC2) instances with different memory sizes to meet all of SAP’s stringent performance requirements for SAP HANA, including proper core-to-memory ratios for compute. In addition, Amazon Elastic Block Store (Amazon EBS) meets, and, in many cases, exceeds, the storage KPIs of the TDI model. Finally, the network bandwidth of EC2 instances meets or exceeds the 9.5 Gbps requirement for internode communications in scale-out mode.
Let’s take a closer look at these building blocks and configuration options.
Memory and compute
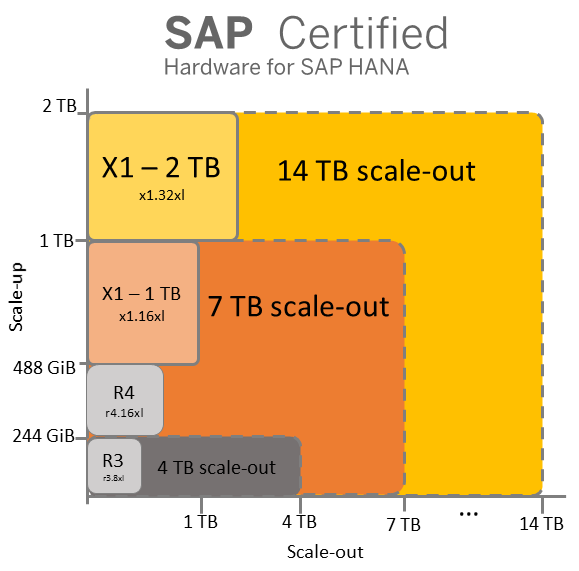
AWS provides several EC2 instance types to support different types of workloads. There are two EC2 instance families that are well suited for SAP HANA workloads: memory-optimized R3 and R4 instances, and high-memory X1 instances. These instance families have been purpose-built for in-memory workloads such as SAP HANA. These instance families and the instance types they contain give you a variety of compute options for running your SAP HANA workload. For online analytical processing (OLAP) workloads (for example, SAP Business Warehouse on HANA, SAP BW/4HANA, data marts, etc.), you can scale vertically starting from 244 GiB to 2 TB, and horizontally all the way to 14 TB with full support from SAP. Note, too, that we have tested up to 25-node deployments or a total of 50 TB of RAM successfully in the AWS lab. For online transaction processing (OLTP) workloads (for example, SAP Business Suite on HANA, SAP S4/HANA, SAP CRM, etc.), you can scale vertically from 244 GiB to 2 TB today. As AWS continues to introduce new instance types with the latest CPU generations, we will be working closely with SAP to certify these instance types for SAP HANA workloads. Check the Certified IaaS Platforms page in the Certified and Supported SAP HANA Hardware Directory from SAP to see all the certified AWS instance types that you can use in production for SAP HANA workloads. You can always use smaller instance sizes such as r3.2xlarge, r4.2xlarge, etc. within a given instance family for non-production workloads to reduce your total cost of ownership (TCO). Remember, these are cloud native instances that give you the flexibility to seamlessly change the memory footprint of your SAP HANA system from 64 GiB to 2 TB and vice versa in a matter of minutes, which brings unprecedented agility to your SAP HANA implementation.
The following diagram and table summarize the memory and compute options that I just described.
| Options for production workloads | |||
| Instance type | Memory (GiB) | vCPU | SAPS |
| x1.32xlarge | 1952 | 128 | 131,500 |
| x1.16xlarge | 976 | 64 | 65,750 |
| r4.16xlarge | 488 | 64 | 76,400 |
| r3.8xlarge | 244 | 32 | 31,920 |
| Additional options for non-production workloads | |||
| Instance type | Memory (GiB) | vCPU | SAPS |
| r4.8xlarge | 244 | 32 | 38,200 |
| r4.4xlarge | 122 | 16 | 19,100 |
| r4.2xlarge | 61 | 8 | 9,550 |
| r3.4xlarge | 122 | 16 | 15,960 |
| r3.2xlarge | 61 | 8 | 7,980 |
Storage
AWS provides multiple options when it comes to persistent block storage for SAP HANA. We have two SSD-backed EBS volume types (gp2 and io1) for your performance-sensitive data and log volumes, and cost-optimized / high-throughput magnetic EBS volumes (st1) for SAP HANA backups.
- With the General Purpose SSD (gp2) volume type, you are able to drive up to 160 MB/s of throughput per volume. To achieve the maximum required throughput of 400 MB/s for the TDI model, you have to stripe three volumes together for SAP HANA data and log files.
- Provisioned IOPS SSD (io1) volumes provide up to 320 MB/s of throughput per volume, so you need to stripe at least two volumes to achieve the required throughput.
- With Throughput Optimized HDD (st1) volumes, you can achieve up to 500 MB/s of throughput with sequential read and write with large block sizes, which makes st1 an ideal candidate for storing SAP HANA backups.
One key point is that each EBS volume is automatically replicated within its AWS Availability Zone to protect you from failure, offering high availability and durability. Because of this, you can configure a RAID 0 array at the operating-system level for maximum performance and not have to worry about additional protection (RAID 10 or RAID 5) for your volumes.
Network
Network performance is another critical factor for SAP HANA, especially for scale-out systems. Every EC2 instance provides a certain amount of network bandwidth, and some of the latest instance families like X1 provide up to 20 Gbps of network bandwidth for your SAP HANA needs. In addition, many instances provide dedicated network bandwidth for the Amazon EBS storage backend. For example, the largest X1 instance (x1.32xlarge) provides 20 Gbps of network bandwidth and 10 Gbps of dedicated storage bandwidth. R4 (r4.16xlarge) provides 20 Gbps of network bandwidth in addition to dedicated 12 Gbps of storage bandwidth. Here’s a quick summary of network capabilities of SAP-certified instances.
| Instance type | Network bandwidth (Gbps) | Dedicated Amazon EBS bandwidth (Gbps) |
| x1.32xlarge | 20 | 10 |
| x1.16xlarge | 10 | 5 |
| r4.16xlarge | 20 | 12 |
| r3.8xlarge | 10* | |
* Network and storage traffic share the same 10-Gbps network interface
Operating system (OS)
SAP supports running SAP HANA on SUSE Linux Enterprise Server (SLES) or Red Hat Enterprise Linux (RHEL). Both OS distributions are supported on AWS. In addition, you can use the SAP HANA-specific images for SUSE and Red Hat in the AWS Marketplace to get started easily. You also have the option of bringing your own OS license. Look for details on OS options for SAP HANA on AWS in a future blog post.
Building this all together
You might ask, “It’s great that AWS offers these building blocks for SAP HANA similar to TDI, but how do I put these components together to build a system that meets SAP’s requirements on AWS?” AWS customers asked this question a few years ago, and that’s why we built the AWS Quick Start for SAP HANA. This Quick Start uses AWS CloudFormation templates (infrastructure as code) and custom scripts to help provision AWS infrastructure components, including storage and network. The Quick Start helps set up the operating system prerequisites for the SAP HANA installation, and optionally installs SAP HANA software when you bring your own software and license. Quick Starts are self-service tools that can be used in many AWS Regions across the globe. They help provision infrastructure for your SAP HANA system in a consistent, predictable, and repeatable fashion, whether it is a single-node or a scale-out system, in less than an hour. Check out this recorded demo of the SAP HANA Quick Start in action, which was presented jointly with SAP during the AWS re:Invent 2016 conference.
We strongly recommend using the AWS Quick Start to provision infrastructure for your SAP HANA deployment. However, if you can’t use the Quick Start (for example, because you want to use your own OS image), you can provision a SAP HANA environment manually and put the building blocks together yourself. Just make sure to follow the recommendations in the Quick Start guide for storage and instance types. For this specific purpose, we’ve also provided step-by-step instructions in the SAP HANA on AWS – Manual Deployment Guide. (The manual deployment guide will be updated soon to include instructions for the latest OS versions, including RHEL.)
Backup and recovery
The ability to back up and restore your SAP HANA database in a reliable way is critical for protecting your business data. You can use native SAP HANA tools to back up your database to an EBS volume, and eventually move the backed up files to Amazon Simple Storage Service (Amazon S3) for increased durability. Amazon S3 is a highly scalable and durable object store service. Objects in Amazon S3 are stored redundantly across multiple facilities within a region and provide the eleven 9s of durability. You also have the choice to use enterprise-class backup solutions like Commvault, EMC NetWorker, Veritas NetBackup, and IBM Spectrum Protect (Tivoli Storage Manager), which integrate with Amazon S3 as well as the SAP HANA Backint interface. These partner solutions can help you back up your SAP HANA database directly to Amazon S3 and manage your backup and recovery using enterprise-class software.
High availability (HA) and disaster recovery (DR)
HA and DR are key for your business-critical applications running on SAP HANA. AWS provides several building blocks, including multiple AWS Regions across the globe and multiple Availability Zones within each AWS Region, for you to set up your HA and DR solution, tailored to your uptime and recovery requirements (RTO/RPO). Whether you are looking for a cost-optimized solution or a downtime-optimized solution, there are some unique options available for your SAP HANA HA/DR architecture — take a look at the SAP HANA HA/DR guide to learn more about these. We will dive deeper into this topic in future blog posts.
Migration
When it is time for actual migration, you could use standard SAP toolsets like SAP Software Provisioning Manager (SWPM) and the Database Migration Option (DMO) of the Software Update Manager (SUM), or third-party migration tools to migrate your SAP application running on any database to SAP HANA on AWS. The SAP to AWS migration process isn’t much different from a typical on-premises migration scenario. In an on-premises scenario, you typically have source and target systems residing in the same data center. When you migrate to AWS, the only difference is that your target system is residing on AWS, so you can think of AWS as an extension of your own data center. There are also a number of options for transferring your exported data from your on-premises data center to AWS during migration. I recommend that you take a look at Migrating SAP HANA Systems to X1 Instances on AWS to understand your options better.
Additional considerations include operations, sizing, scaling, integration with other AWS services like Amazon CloudWatch, and big data solutions. We will discuss these in detail in future blog posts. In the mean time, we encourage you to get started with SAP HANA on AWS by using the AWS Quick Start for SAP HANA. To learn more about running SAP workloads on AWS, see the whitepapers listed on the SAP on AWS website.
Finally, if you need a system to scale beyond the currently available system sizes, please contact us. We’ll be happy to discuss your requirements and work with you on your implementation.
– Sabari