AWS Big Data Blog
AWS Glue streaming application to process Amazon MSK data using AWS Glue Schema Registry
Organizations across the world are increasingly relying on streaming data, and there is a growing need for real-time data analytics, considering the growing velocity and volume of data being collected. This data can come from a diverse range of sources, including Internet of Things (IoT) devices, user applications, and logging and telemetry information from applications, to name a few. By harnessing the power of streaming data, organizations are able to stay ahead of real-time events and make quick, informed decisions. With the ability to monitor and respond to real-time events, organizations are better equipped to capitalize on opportunities and mitigate risks as they arise.
One notable trend in the streaming solutions market is the widespread use of Apache Kafka for data ingestion and Apache Spark for streaming processing across industries. Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully managed Apache Kafka service that offers a seamless way to ingest and process streaming data.
However, as data volume and velocity grow, organizations may need to enrich their data with additional information from multiple sources, leading to a constantly evolving schema. The AWS Glue Schema Registry addresses this complexity by providing a centralized platform for discovering, managing, and evolving schemas from diverse streaming data sources. Acting as a bridge between producer and consumer apps, it enforces the schema, reduces the data footprint in transit, and safeguards against malformed data.
To process data effectively, we turn to AWS Glue, a serverless data integration service that provides an Apache Spark-based engine and offers seamless integration with numerous data sources. AWS Glue is an ideal solution for running stream consumer applications, discovering, extracting, transforming, loading, and integrating data from multiple sources.
This post explores how to use a combination of Amazon MSK, the AWS Glue Schema Registry, AWS Glue streaming ETL jobs, and Amazon Simple Storage Service (Amazon S3) to create a robust and reliable real-time data processing platform.
Overview of solution
In this streaming architecture, the initial phase involves registering a schema with the AWS Glue Schema Registry. This schema defines the data being streamed while providing essential details like columns and data types, and a table is created in the AWS Glue Data Catalog based on this schema. This schema serves as a single source of truth for producer and consumer and you can leverage the schema evolution feature of AWS Glue Schema Registry to keep it consistent as the data changes over time. Refer appendix section for more information on this feature. The producer application is able to retrieve the schema from the Schema Registry, and uses it to serialize the records into the Avro format and ingest the data into an MSK cluster. This serialization ensures that the records are properly structured and ready for processing.
Next, an AWS Glue streaming ETL (extract, transform, and load) job is set up to process the incoming data. This job extracts data from the Kafka topics, deserializes it using the schema information from the Data Catalog table, and loads it into Amazon S3. It’s important to note that the schema in the Data Catalog table serves as the source of truth for the AWS Glue streaming job. Therefore, it’s crucial to keep the schema definition in the Schema Registry and the Data Catalog table in sync. Failure to do so may result in the AWS Glue job being unable to properly deserialize records, leading to null values. To avoid this, it’s recommended to use a data quality check mechanism to identify such anomalies and take appropriate action in case of unexpected behavior. The ETL job continuously consumes data from the Kafka topics, so it’s always up to date with the latest streaming data. Additionally, the job employs checkpointing, which keeps track of the processed records and allows it to resume processing from where it left off in the event of a restart. For more information about checkpointing, see the appendix at the end of this post.
After the processed data is stored in Amazon S3, we create an AWS Glue crawler to create a Data Catalog table that acts as a metadata layer for the data. The table can be queried using Amazon Athena, a serverless, interactive query service that enables running SQL-like queries on data stored in Amazon S3.
The following diagram illustrates our solution architecture for a real-time data processing platform by combining Amazon MSK for data ingestion, AWS Glue Schema Registry for schema management, and AWS Glue streaming ETL jobs for data processing. The architecture enables producers to serialize data using schemas from the Schema Registry, ingest it into MSK, process it using AWS Glue streaming jobs, store the processed data in Amazon S3, and finally query it using Amazon Athena.
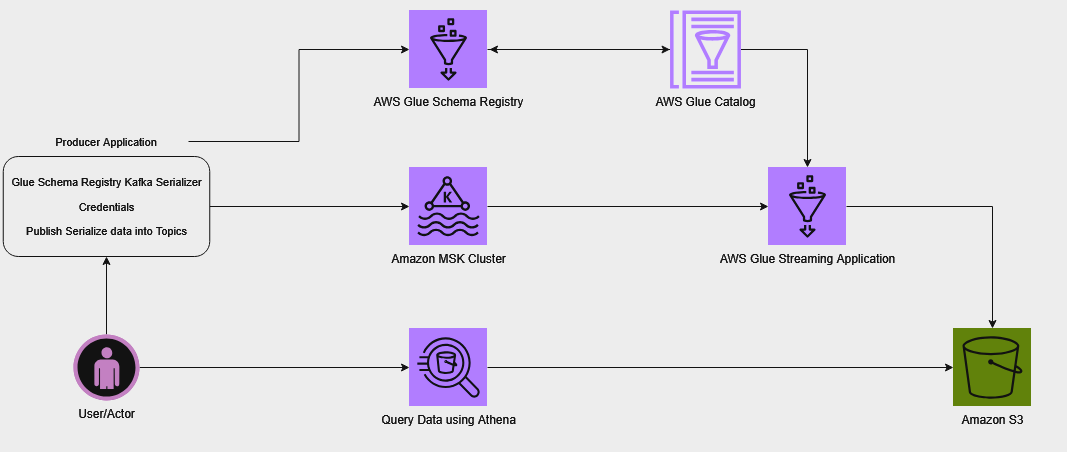
For this post, we are creating the solution resources in the us-east-1 region using AWS CloudFormation templates. In the following sections, we will show you how to configure your resources and implement the solution.
Prerequisites
Create and download a valid key to SSH into an Amazon Elastic Compute Cloud (Amazon EC2) instance from your local machine. For instructions, see Create a key pair using Amazon EC2.
Configure resources with AWS CloudFormation
To create your solution resources, complete the following steps:
- Launch the stack
vpc-subnet-and-mskclientusing the CloudFormation templatevpc-subnet-and-mskclient.template. This stack creates an Amazon VPC, private and public subnets, security groups, interface endpoints, an S3 bucket, an AWS Secrets Manager secret, and an EC2 instance.

- Provide parameter values as listed in the following table.
Parameters Description EnvironmentNameEnvironment name that is prefixed to resource names. VpcCIDRIP range (CIDR notation) for this VPC. PublicSubnet1CIDRIP range (CIDR notation) for the public subnet in the first Availability Zone. PublicSubnet2CIDRIP range (CIDR notation) for the public subnet in the second Availability Zone. PrivateSubnet1CIDRIP range (CIDR notation) for the private subnet in the first Availability Zone. PrivateSubnet2CIDRIP range (CIDR notation) for the private subnet in the second Availability Zone. KeyNameKey pair name used to log in to the EC2 instance. SshAllowedCidrCIDR block for allowing SSH connection to the instance. Check your public IP using http://checkip.amazonaws.com/ and add /32 at the end of the IP address. InstanceTypeInstance type for the EC2 instance. - When stack creation is complete, retrieve the EC2 instance
PublicDNSand S3 bucket name (for keyBucketNameForScript) from the stack’s Outputs tab.
- Log in to the EC2 instance using the key pair you created as a prerequisite.
- Clone the GitHub repository, and upload the ETL script from the
glue_job_scriptfolder to the S3 bucket created by the CloudFormation template: - Launch another stack
amazon-msk-and-glueusing templateamazon-msk-and-glue.template. This stack creates an MSK cluster, schema registry, schema definition, database, table, AWS Glue crawler, and AWS Glue streaming job.
- Provide parameter values as listed in the following table.
Parameters Description Sample value EnvironmentNameEnvironment name that is prefixed to resource names. amazon-msk-and-glueVpcIdID of the VPC for security group. Use the VPC ID created with the first stack. Refer to the first stack’s output. PrivateSubnet1Subnet used for creating the MSK cluster and AWS Glue connection. Refer to the first stack’s output. PrivateSubnet2Second subnet for the MSK cluster. Refer to the first stack’s output. SecretArnSecrets Manager secret ARN for Amazon MSK SASL/SCRAM authentication. Refer to the first stack’s output. SecurityGroupForGlueConnectionSecurity group used by the AWS Glue connection. Refer to the first stack’s output. AvailabilityZoneOfPrivateSubnet1Availability Zone for the first private subnet used for the AWS Glue connection. SchemaRegistryNameName of the AWS Glue schema registry. test-schema-registryMSKSchemaNameName of the schema. test_payload_schemaGlueDataBaseNameName of the AWS Glue Data Catalog database. test_glue_databaseGlueTableNameName of the AWS Glue Data Catalog table. outputScriptPathAWS Glue ETL script absolute S3 path. For example, s3://bucket-name/mskprocessing.py. Use the target S3 path from the previous steps. GlueWorkerTypeWorker type for AWS Glue job. For example, Standard, G.1X, G.2X, G.025X. G.1XNumberOfWorkersNumber of workers in the AWS Glue job. 5S3BucketForOutputBucket name for writing data from the AWS Glue job. aws-glue-msk-output-{accId}-{region}TopicNameMSK topic name that needs to be processed. testThe stack creation process can take around 15–20 minutes to complete. You can check the Outputs tab for the stack after the stack is created.

The following table summarizes the resources that are created as a part of this post.
Logical ID Type VpcEndointAWS::EC2::VPCEndpointVpcEndointAWS::EC2::VPCEndpointDefaultPublicRouteAWS::EC2::RouteEC2InstanceProfileAWS::IAM::InstanceProfileEC2RoleAWS::IAM::RoleInternetGatewayAWS::EC2::InternetGatewayInternetGatewayAttachmentAWS::EC2::VPCGatewayAttachmentKafkaClientEC2InstanceAWS::EC2::InstanceKeyAliasAWS::KMS::AliasKMSKeyAWS::KMS::KeyKmsVpcEndointAWS::EC2::VPCEndpointMSKClientMachineSGAWS::EC2::SecurityGroupMySecretAAWS::SecretsManager::SecretPrivateRouteTable1AWS::EC2::RouteTablePrivateSubnet1AWS::EC2::SubnetPrivateSubnet1RouteTableAssociationAWS::EC2::SubnetRouteTableAssociationPrivateSubnet2AWS::EC2::SubnetPrivateSubnet2RouteTableAssociationAWS::EC2::SubnetRouteTableAssociationPublicRouteTableAWS::EC2::RouteTablePublicSubnet1AWS::EC2::SubnetPublicSubnet1RouteTableAssociationAWS::EC2::SubnetRouteTableAssociationPublicSubnet2AWS::EC2::SubnetPublicSubnet2RouteTableAssociationAWS::EC2::SubnetRouteTableAssociationS3BucketAWS::S3::BucketS3VpcEndointAWS::EC2::VPCEndpointSecretManagerVpcEndointAWS::EC2::VPCEndpointSecurityGroupAWS::EC2::SecurityGroupSecurityGroupIngressAWS::EC2::SecurityGroupIngressVPCAWS::EC2::VPCBootstrapBrokersFunctionLogsAWS::Logs::LogGroupGlueCrawlerAWS::Glue::CrawlerGlueDataBaseAWS::Glue::DatabaseGlueIamRoleAWS::IAM::RoleGlueSchemaRegistryAWS::Glue::RegistryMSKClusterAWS::MSK::ClusterMSKConfigurationAWS::MSK::ConfigurationMSKPayloadSchemaAWS::Glue::SchemaMSKSecurityGroupAWS::EC2::SecurityGroupS3BucketForOutputAWS::S3::BucketCleanupResourcesOnDeletionAWS::Lambda::FunctionBootstrapBrokersFunctionAWS::Lambda::Function
Build and run the producer application
After successfully creating the CloudFormation stack, you can now proceed with building and running the producer application to publish records on MSK topics from the EC2 instance, as shown in the following code. Detailed instructions including supported arguments and their usage are outlined in the README.md page in the GitHub repository.
If the records are successfully ingested into the Kafka topics, you may see a log similar to the following screenshot.

Grant permissions
Confirm if your AWS Glue Data Catalog is being managed by AWS Lake Formation and grant necessary permissions. To check if Lake Formation is managing the permissions for the newly created tables, we can navigate to the Settings page on the Lake Formation console, or we can use the Lake Formation CLI command get-data-lake-settings.
If the check boxes on the Lake Formation Data Catalog settings page are unselected (see the following screenshot), that means that the Data Catalog permissions are being managed by LakeFormation.

If using the Lake Formation CLI, check if the values of CreateDatabaseDefaultPermissions and CreateTableDefaultPermissions are NULL in the output. If so, this confirms that the Data Catalog permissions are being managed by AWS Lake Formation.
If we can confirm that the Data Catalog permissions are being managed by AWS Lake Formation, we have to grant DESCRIBE and CREATE TABLE permissions for the database, and SELECT, ALTER, DESCRIBE and INSERT permissions for the table to the AWS Identity and Access Management role (IAM role) used by AWS Glue streaming ETL job before starting the job. Similarly, we have to grant DESCRIBE permissions for the database and DESCRIBE AND SELECT permissions for the table to the IAM principals using Amazon Athena to query the data. We can get the AWS Glue service IAM role, database, table, streaming job name, and crawler names from the Outputs tab of the CloudFormation stack amazon-msk-and-glue. For instructions on granting permissions via AWS Lake Formation, refer to Granting Data Catalog permissions using the named resource method.
Run the AWS Glue streaming job
To process the data from the MSK topic, complete the following steps:
- Retrieve the name of the AWS Glue streaming job from the
amazon-msk-and-gluestack output. - On the AWS Glue console, choose Jobs in the navigation pane.
- Choose the job name to open its details page.
- Choose Run job to start the job.
Because this is a streaming job, it will continue to run indefinitely until manually stopped.
Run the AWS Glue crawler
Once AWS Glue streaming job starts processing the data, you can use the following steps to check the processed data, and create a table using AWS Glue Crawler to query it
- Retrieve the name of the output bucket
S3BucketForOutputfrom the stack output and validate ifoutputfolder has been created and contains data. - Retrieve the name of the Crawler from the stack output.
- Navigate to the AWS Glue Console.
- In the left pane, select Crawlers.
- Run the crawler.
In this post, we run the crawler one time to create the target table for demo purposes. In a typical scenario, you would run the crawler periodically or create or manage the target table another way. For example, you could use the saveAsTable() method in Spark to create the table as part of the ETL job itself, or you could use enableUpdateCatalog=True in the AWS Glue ETL job to enable Data Catalog updates. For more information about this AWS Glue ETL feature, refer to Creating tables, updating the schema, and adding new partitions in the Data Catalog from AWS Glue ETL jobs.
Validate the data in Athena
After the AWS Glue crawler has successfully created the table for the processed data in the Data Catalog, follow these steps to validate the data using Athena:
- On the Athena console, navigate to the query editor.
- Choose the Data Catalog as the data source.
- Choose the database and table that the crawler created.
- Enter a SQL query to validate the data.
- Run the query.
The following screenshot shows the output of our example query.

Clean up
To clean up your resources, complete the following steps:
- Delete the CloudFormation stack
amazon-msk-and-glue. - Delete the CloudFormation stack
vpc-subnet-and-mskclient.
Conclusion
This post provided a solution for building a robust streaming data processing platform using a combination of Amazon MSK, the AWS Glue Schema Registry, an AWS Glue streaming job, and Amazon S3. By following the steps outlined in this post, you can create and control your schema in the Schema Registry, integrate it with a data producer to ingest data into an MSK cluster, set up an AWS Glue streaming job to extract and process data from the cluster using the Schema Registry, store processed data in Amazon S3, and query it using Athena.
Let’s start using AWS Glue Schema Registry to manage schema evolution for streaming data ETL with AWS Glue. If you have any feedback related to this post, please feel free to leave them in the comments section below.
Appendix
This appendix section provides more information about Apache Spark Structured Streaming Checkpointing feature and a brief summary on how schema evolution can be handled using AWS Glue Schema Registry.
Checkpointing
Checkpointing is a mechanism in Spark streaming applications to persist enough information in a durable storage to make the application resilient and fault-tolerant. The items stored in checkpoint locations are mainly the metadata for application configurations and the state of processed offsets. Spark uses synchronous checkpointing, meaning it ensures that the checkpoint state is updated after every micro-batch run. It stores the end offset value of each partition under the offsets folder for the corresponding micro-batch run before processing, and logs the record of processed batches under the commits folder. In the event of a restart, the application can recover from the last successful checkpoint, provided the offset hasn’t expired in the source Kafka topic. If the offset has expired, we have to set the property failOnDataLoss to false so that the streaming query doesn’t fail as a result of this.
Schema evolution
As the schema of data evolves over time, it needs to be incorporated into producer and consumer applications to avert application failure due to data encoding issues. The AWS Glue Schema Registry offers a rich set of options for schema compatibility such as backward, forward, and full to update the schema in the Schema Registry. Refer to Schema versioning and compatibility for the full list.
The default option is backward compatibility, which satisfies the majority of use cases. This option allows you to delete any existing fields and add optional fields. Steps to implement schema evolution using the default compatibility are as follows:
- Register the new schema version to update the schema definition in the Schema Registry.
- Upon success, update the AWS Glue Data Catalog table using the updated schema.
- Restart the AWS Glue streaming job to incorporate the changes in the schema for data processing.
- Update the producer application code base to build and publish the records using the new schema, and restart it.
About the Authors
 Vivekanand Tiwari is a Cloud Architect at AWS. He finds joy in assisting customers on their cloud journey, especially in designing and building scalable, secure, and optimized data and analytics workloads on AWS. During his leisure time, he prioritizes spending time with his family.
Vivekanand Tiwari is a Cloud Architect at AWS. He finds joy in assisting customers on their cloud journey, especially in designing and building scalable, secure, and optimized data and analytics workloads on AWS. During his leisure time, he prioritizes spending time with his family.
 Subramanya Vajiraya is a Sr. Cloud Engineer (ETL) at AWS Sydney specialized in AWS Glue. He is passionate about helping customers solve issues related to their ETL workload and implement scalable data processing and analytics pipelines on AWS. Outside of work, he enjoys going on bike rides and taking long walks with his dog Ollie, a 2-year-old Corgi.
Subramanya Vajiraya is a Sr. Cloud Engineer (ETL) at AWS Sydney specialized in AWS Glue. He is passionate about helping customers solve issues related to their ETL workload and implement scalable data processing and analytics pipelines on AWS. Outside of work, he enjoys going on bike rides and taking long walks with his dog Ollie, a 2-year-old Corgi.
 Akash Deep is a Cloud Engineer (ETL) at AWS with a specialization in AWS Glue. He is dedicated to assisting customers in resolving issues related to their ETL workloads and creating scalable data processing and analytics pipelines on AWS. In his free time, he prioritizes spending quality time with his family.
Akash Deep is a Cloud Engineer (ETL) at AWS with a specialization in AWS Glue. He is dedicated to assisting customers in resolving issues related to their ETL workloads and creating scalable data processing and analytics pipelines on AWS. In his free time, he prioritizes spending quality time with his family.
Audit History
Last reviewed and updated in September 2025 by Olajide Ogunmola | Solutions Architect